Machine Learning in Action -- Support Vector Machines
虽然SVM本身算法理论,水比较深,很难懂
但是基本原理却非常直观易懂,就是找到与训练集中支持向量有最大间隔的超平面
形式化的描述:
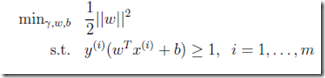
其中需要满足m个约束条件,m为数据集大小,即数据集中的每个数据点function margin都是>=1,因为之前假设所有支持向量,即离超平面最近的点,的function margin为1
对于这种有约束条件的最优化问题,用拉格朗日定理,于是得到如下的形式,
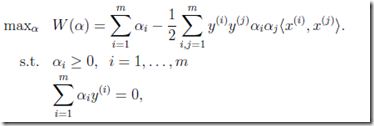
现在我们的目的就是求出最优化的m个拉格朗日算子,因为通过他们我们可以间接的算出w和b,从而得到最优超平面
考虑到某些离群值,加入松弛变量(slack variables),软间隔的版本为,
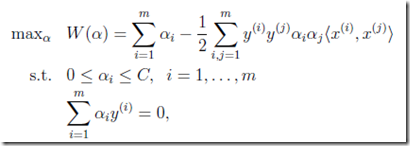
可以看到只是拉格朗日算子α的取值范围发生了变化,并且需要满足如下的KKT条件,
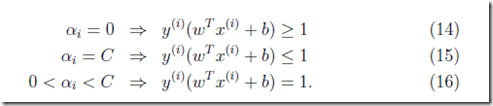
对于每个训练数据点都有一个对应的α
α对于绝大部分非支持向量而言,都是等于0的,这个由之前KKT条件可以推出
α等于C表示为离群值,个别function margin小于1的异常值
支持向量的α应该在0到C之间
所以这组KKT条件很容易理解,前面假设支持向量的function margin,即wx+b,为1
下面就是如何解这个问题?
之前大家都是用二次规划求解工具来求解,总之,这个计算量是非常大的
后来Platt提出SMO算法来优化这个求解过程,看过Andrew讲义就知道,这个算法是坐标上升算法的变种
下面就具体看看怎样实现SMO算法,关于算法的实现Andrew的讲义已经不够用,需要看Platt的论文
或参考这个blog,写的比较清楚,
SMO的简化版本
因为对于SMO算法,为了保持KKT条件,每次需要选取一对,即两个,α来进行优化
出于简单考虑,先随机的来选取α,后面再考虑启发式的来选取
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix) #初始化b为0
alphas = mat(zeros((m,1))) #初始化所有α为0
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m): #遍历所有的训练集
fXi = float(multiply(alphas,labelMat).T * (dataMatrix*dataMatrix[i,:].T)) + b #1.计算wx+b
Ei = fXi - float(labelMat[i]) #和真实值比,计算误差
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or \
((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m) #随机选择第二个α
fXj = float(multiply(alphas,labelMat).T * (dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); #存下变化前两个α的值
alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]): #2.算出H和L,即α的边界值
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - \ #3.计算新的α
dataMatrix[i,:]*dataMatrix[i,:].T - \
dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta #更新αj
alphas[j] = clipAlpha(alphas[j],H,L) #和边界比较,不能超过边界
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j]) #根据αj的更新,反过来更新αi b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*\ #4.更新b
dataMatrix[i,:]*dataMatrix[i,:].T - \
labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[j,:].T - \
labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0 alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged) if (alphaPairsChanged == 0): iter += 1 #记录α没有变化的次数,如果多次α没有变化,说明已经收敛
else: iter = 0
print "iteration number: %d" % iter return b,alphas
1. 计算wx+b
由于w是可以用α间接算出的,公式如下,
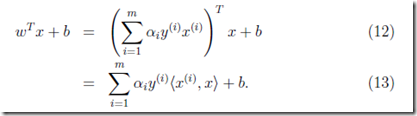
2. 计算α2的取值范围,即边界值,H和L,参考上面的blog
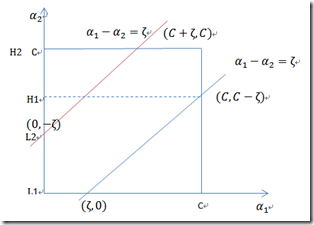
由约束条件,可以得到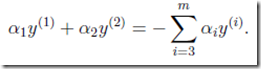
等式右边是常数,而y不是1,就是-1,所以α1和α2是上图的线性关系(y1=1,y2=-1的case)
图上画出线不同的两种边界值的case,可以比较直观的看出,
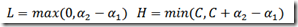
对于y1=1,y2=1的case同理差不多
3. 计算新的α
从讲义中,只知道算出下面式子的极值,就可以得到新的α
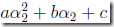
但没有给出具体解的过程,其实还是比较复杂的,参考上面的blog
得到的解是,

其中,
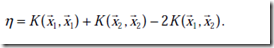 K表示内积
K表示内积
看到这个公式就不难理解上面的代码的计算过程了
SMO的完整版本
关键的变化就是α的选择,采用启发式的来选择,从而大大优化算法速度
首先如何选取第一个α?
因为我们是需要通过最优化W来更新α的,所以对于边界值,即α=0或C的case,α是不会改变的,因为边界值的改变一定不会让分类效果变得更好
所以我们希望可以不断的优化支持向量的α,因为这个才是真正有效的优化,而不需要在边界α上浪费时间,这样可以大大提高算法效率
但问题是,所有α的初始值都是0,所以直接找非0的α是不可行的,所以这里的方法是,
先遍历所有α进行更新,这样会产生一些非0的α,然后对于这些α进行不断优化,直到收敛
然后再遍历所有α进行更新,也许会得到一些新的非0的α。。。。。
代码如下,
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True #第一遍是全遍历
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS) #调用内循环去更新α
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #一次全遍历后,切换成选择遍历
elif (alphaPairsChanged == 0): entireSet = True #当前α不改变了,再全遍历
return oS.b,oS.alphas
上面的blog中,全遍历应该选取那些违反KKT条件的α进行优化,这样应该更合理一些,那些符合KTT条件的没必要做优化
有空可以把这个实现改一下,看看会不会更快一些
如何选择第二个α?
相对于之前的random选取,改进为,选择最大误差步长的,即Ei-Ej最大的
即当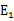 为正时选择负的绝对值最大的
为正时选择负的绝对值最大的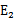 ,反之,选择正值最大的
,反之,选择正值最大的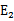
这个直观上看,是有道理的,
因为另外一个α,需要根据当前α的改动,做相反的改动,以保证所有α的和不变
具体的代码参考原书,因为和简单版的相似
只是要缓存和更新所有的E值,并在选择第二个α时,做下计算选出Ei-Ej最大的
对非线性的复杂数据集使用kernels核函数
基础的SVM只能用于线性可分的数据集,如果不可分怎么办?
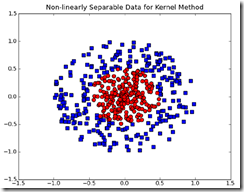
上面就是典型的例子,通常解决的方法,就是将低维数据转换为高维数据
比如上面的数据在二维看是线性不可分的,但是如果到了3维,可能蓝色的点和红色的点在高度上有些差异,这样就可以用一个平面,线性可分了
所以当数据非线性可分,当把数据的维度升高时,就有可能是线性可分的
对于SVM的对偶形式而言,只会计算内积形式,参考讲义
而我们如果把内积替换成核函数,就可以达成将低维数据到高维数据的转换,为什么?
因为所有的核函数,一定是等价于两个高维向量的内积,你不一定可以找出这个高维向量是什么,因为可能是无限维的向量,你也不需要care
所以用核函数替换当前低维向量的内积,就相当于用高维向量的内积替换低维向量的内积
下面看看具体的代码实现
这里实现的是最为流行的radial bias function的高斯版本,高斯核,对应于无限维的向量内积
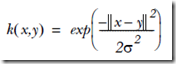
对于m个数据点的训练集,我们要用高斯核函数,算出每对数据点间的核函数值,即m×m的结果矩阵
这样做训练或预测时,当需要计算内积时,直接查表即可
self.K = mat(zeros((self.m,self.m))) #初始化m*m矩阵
for i in range(self.m): #对于一个数据点,算出和其他所有数据点之间的核函数值,填入表内
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
下面看下kernelTrans
def kernelTrans(X, A, kTup):
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #线性核
elif kTup[0]=='rbf': #高斯核
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K /(-1*kTup[1]**2))
else: raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
其中kTup[0]表示核类型,这里给出两种核的实现
kTup[1]是计算核需要的参数,对于高斯核就是a
剩下使用时,就把所有需要计算内积的地方,都替换成查表即可
Machine Learning in Action -- Support Vector Machines的更多相关文章
- Machine Learning No.7: Support Vector Machines
1. SVM hypothsis 2. large margin classification 3. kernals and similarity if f1 = 1; if x if far fr ...
- Machine Learning - 第7周(Support Vector Machines)
SVMs are considered by many to be the most powerful 'black box' learning algorithm, and by posing构建 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- 【Supervised Learning】支持向量机SVM (to explain Support Vector Machines (SVM) like I am a 5 year old )
Support Vector Machines 引言 内核方法是模式分析中非常有用的算法,其中最著名的一个是支持向量机SVM 工程师在于合理使用你所拥有的toolkit 相关代码 sklearn-SV ...
- Machine Learning in Action(5) SVM算法
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子.他的理论很优美,各种变种改进版本也很多,比如 ...
- 《Machine Learning in Action》—— 剖析支持向量机,单手狂撕线性SVM
<Machine Learning in Action>-- 剖析支持向量机,单手狂撕线性SVM 前面在写NumPy文章的结尾处也有提到,本来是打算按照<机器学习实战 / Machi ...
- Support Vector Machines for classification
Support Vector Machines for classification To whet your appetite for support vector machines, here’s ...
- machine learning in action , part 1
We should think in below four questions: the decription of machine learning key tasks in machine lea ...
- Introduction to One-class Support Vector Machines
Traditionally, many classification problems try to solve the two or multi-class situation. The goal ...
随机推荐
- hdu 4267 多维树状数组
题意:有一个序列 "1 a b k c" means adding c to each of Ai which satisfies a <= i <= b and (i ...
- [hive小技巧]增加hive并行度
可以通过修改set hive.exec.parallel=true来修改并行度.如果job中并行执行的阶段增多,那么集群利用率会增加.
- html 音频视频
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- BZOJ3836 : [Poi2014]Tourism
对于一个连通块,取一个点进行dfs,得到一棵dfs搜索树,则这棵树的深度不超过10,且所有额外边都是前向边. 对于每个点x,设S为三进制状态,S第i位表示根到x路径上深度为i的点的状态: 0:选了 1 ...
- Java集合的线程安全用法
线程安全的集合包含2个问题 1.多线程并发修改一 个 集合 怎么办? 2.如果迭代的过程中 集合 被修改了怎么办? a.一个线程在迭代,另一个线程在修改 b.在同一个线程内用同一个迭代器对象进行迭代. ...
- Java虚拟机工作原理详解
原文地址:http://blog.csdn.net/bingduanlbd/article/details/8363734 一.类加载器 首先来看一下java程序的执行过程. 从这个框图很容易大体上了 ...
- 使用HttpsURLConnection发送POST请求
重写X509TrustManager private static TrustManager myX509TrustManager = new X509TrustManager() { @Overri ...
- 手机开发必备技巧:javascript及CSS功能代码分享
1. viewport: 也就是可视区域.对于桌面浏览器,我们都很清楚viewport是什么,就是出去了所有工具栏.状态栏.滚动条等等之后用于看网页的区域,这是真正有效的区域.由于移动设备屏幕宽度不同 ...
- 几种进入mysql的方法
1.首先mysql服务得打开(运行cmd命令也可以net start mysql) 2.运行cmd,打开mysq 3.mysql命令行打开mysql 4.图形管理工具,如phpMyadmin
- OS | 哲学家问题
哲学家进餐问题: (1) 在什么情况下5 个哲学家全部吃不上饭?考虑两种实现的方式,如下:A.算法描述: void philosopher(int i) {/*i:哲学家编号,从0 到4*/ whil ...