哈希表查找(散列表查找) c++实现HashMap
算法思想:
哈希表
什么是哈希表
在前面讨论的各种结构(线性表、树等)中,记录在结构中的相对位置是随机的,和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较”的基础上。
在顺序查找时,比较的结果为“="与“!=”两种可能;
在折半查找、二叉排序树查找和B树查找时,比较的结果为“<"、"="和“>"3种可能。查找的效率依赖于查找过程中所进行的比较次数。
理想的情况是希望不经过任何比较,一次存取便能得到所查记录,那就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个惟一的存储位置相对应。因而在查找时,只要根据这个对应关系f找到给定值K的像f(K)。若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,由此,不需要进行比较便可直接取得所查记录。在此,我们称这个对应关系f为哈希( Hash)函数,按这个思想建立的表为哈希表。
哈希函数的构造方法
哈希函数是从关键字集合到地址集合的映像。通常,关键字集合比较大,它的元素包括所有可能的关键字,而地址集合的元素仅为哈希表中的地址值。哈希函数其实是一个压缩映像,那么这种情况就不可避免的产生冲突,那么在建造哈希表时不仅要设定一个好的哈希函数,还要设定一种处理冲突的方法。(设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表就是哈希表,映像的过程为哈希造表或散列,所得的存储位置称哈希地址或散列地址)
(1)直接定址法
取关键字或关键字的某个线性函数值为哈希地址。即H(key)=key 或 H(key)=a*key+b (a,b为常数)。
举例1:统计1-100岁的人口,其中年龄作为关键字,哈希函数取关键字自身。查找年龄25岁的人口有多少,则直接查表中第25项。
地址 01 02 03 ... 25 26 27 ... 100
年龄 1 2 3 ... 25 26 27 ... ....
人数 3000 2000 ............. 1050
...
举例2:统计解放以后出生人口,其中年份作为关键字,哈希函数取关键字自身加一个常数H(key)=key+(-1948).查找1970年出生的人数,则直接查(1970-1948)=22项即可。
地址 01 02 03 ... 22 23 24 ...
年份 1949 1950 1951 ... 1970
人数 ............. 15000
...
(2)数字分析法
若关键字是以r为基的数(如:以10为基的十进制数),并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
举例:有80个记录,其关键字为8位十进制数,假设哈希表长,则可取两位十进制数组成哈希地址,为了尽量避免冲突,可先分析关键字。
8 1 3 4 6 5 3 2
8 1 3 7 2 2 4 2
8 1 3 8 7 4 2 2
8 1 3 0 1 3 6 7
8 1 3 2 2 8 1 7
8 1 3 3 8 9 6 7
8 1 3 5 4 1 5 7
8 1 3 6 8 5 3 7
8 1 4 1 9 3 5 5 ...........
经分析,发现第一位、第二位都是8,1,第三位只可能取3或4,第八位只可能取2,5或7,所以这四位不可取,那么对于第四、五、六、七位可看成是随机的,因此,可取其中任意两位,或取其中两位与另外两位的叠加求和舍去进位作为哈希地址。
(3)平方取中法
取关键字平方后的中间几位为哈希地址。(较常用的一种)
举例:为BASIC源程序中的标识符键一个哈希表(假设BASIC语言允许的标识符为一个字母或者一个字母和一个数字两种情况,在计算机内可用两位八进制数表示字母和数字),假设表长为512=,则可取关键字平方后的中间9位二进制数为哈希地址。(每3个二进制位可表示1位八进制位,即3个八进制位为9个二进制位)
A :01 (A的ASCII码值为65,65的八进制为101,取后两位表示关键字)
B:02 (B的ASCII码值为66,66的八进制为102,取后两位表示关键字)
...
Z:32(Z的ASCII码值为90,90的八进制为132,取后两位表示关键字)
...
0:60(0的ASCII码值为48,48的八进制为60,取后两位表示关键字)
...
9:71(9的ASCII码值为57,57的八进制为71,取后两位表示关键字)
记录 关键字 关键字的平方 哈希地址(~)
A 0100 0010000 010
I 1100 1210000 210
P1 2061 4310541 310
Q2 2162 4741304 741
(4)折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。适用于关键字位数比较多,且关键字中每一位上数字分布大致均匀时。
举例:根据国际标准图书编号(ISBN)建立一个哈希表。如一个国际标准图书编号 0-442-20586-4的哈希地址为:
5864 5864
4220 0224
+ 04 + 04
10088 6092
移位叠加 间接叠加
H(key)=0088(将分割后的每一部分的最低位对齐) H(key)=6092(从一端向另一端沿分割界来回叠加)
(5)除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址(p为素数)
H(key)=key MOD p,p<=m (最简单,最常用)p的选取很重要
一般情况,p可以选取为质数或者不包含小于20的质因数的合数(合数指自然数中除了能被1和本身整除外,还能被其他数(0除外)整除的数)。
(6)随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址。即H(key)=random(key),其中random为随机函数。适用于关键字长度不等时。
总结:实际工作中根据情况不同选用的哈希函数不同,通常,考虑因素如下:
(1)计算哈希函数所需时间(包括硬件指令的因素)
(2)关键字的长度
(3)哈希表的大小
(4)关键字的分布情况
(5)记录的查找频率
常用冲突处理方法:
1.开放定址法:
方法: fi(key)=(f(key)+di) mod m,(di=1,2,3,4...,m−1)fi(key)=(f(key)+di) mod m,(di=1,2,3,4...,m−1)
线性探测:只要一旦发现冲突,就寻找下一个空的散列地址
二次探测:di=12,−12,22,−22,...,q2,−q2di=12,−12,22,−22,...,q2,−q2,目的是不让关键词集中在某块区域,产生堆积
随机探测:didi是一个随机数,但查询时需要设置和插入时相同的随机种子
2.再散列函数法:(再哈希法)
方法:fi(key)=RHi(key) (i=1,2,...k)fi(key)=RHi(key) (i=1,2,...k)
遇到冲突就重新采用一个散列函数计算新的存储位置,可以使关键字不产生聚集
3.链地址法(拉链)
方法:将所有关键字的同义词记录在一个单链表中,在散列表中只存储所有同义词表的头指针
4.建立一个公共溢出区法
方法:为所有冲突的关键字开辟一个公共的溢出区(表)来存放
适用于相对于基本表来说冲突数据很少的情况
实现方法:(哈希表采用数组存储,哈希函数构造和处理冲突的方法是除留余数法+开放定址法)
/****
* Hash Table
*
****/ //#include "Global.h"
#include"stdafx.h"
#include <iostream>
using namespace std; // HashTable Data Structure Definition
// array hashtable
#define tablesize 10
typedef int HashTable[tablesize];
//hash function initialization way
void Initial_HashTable(HashTable &ht)
{
for (int i = ; i < tablesize; i++)
ht[i] = ;
}
//search hashtable function
int Search_HashTable(HashTable &ht,int key)
{
int address = key%tablesize;
int compare = ;
while (compare < tablesize&&ht[address] != key&&ht[address] != )
{
compare++;
address = (address+)%tablesize;
}
if (compare == || ht[address] == )
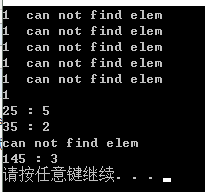
cout << "can not find elem" << endl;
return address;
}
//insert hashtable function
int Insert_HashTable(HashTable &ht,int key)
{
int res = Search_HashTable(ht,key);
if (ht[res] == )
{
ht[res] = key;
return ;
}
return ;
}
//test function
int main()
{
int data[] = { ,,,,,,, };
HashTable ht; //initialization.
Initial_HashTable(ht); //insert datas.
for (int i = ; i < ; i++)
{
cout << Insert_HashTable(ht, data[i]) << " ";
}
cout << endl; //search.
cout << "25 : " << Search_HashTable(ht, ) << endl;
cout << "35 : " << Search_HashTable(ht, ) << endl;
cout << "145 : " << Search_HashTable(ht, ) << endl;
system("pause");
return ;
}
哈希表查找(散列表查找) c++实现HashMap的更多相关文章
- 哈希表(散列表),Hash表漫谈
1.序 该篇分别讲了散列表的引出.散列函数的设计.处理冲突的方法.并给出一段简单的示例代码. 2.散列表的引出 给定一个关键字集合U={0,1......m-1},总共有不大于m个元素.如果m不是很大 ...
- java资料——哈希表(散列表)(转)
哈希表 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度. ...
- 哈希表(散列表)—Hash表解决地址冲突 C语言实现
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.具体的介绍网上有很详 ...
- 【Python算法】哈希存储、哈希表、散列表原理
哈希表的定义: 哈希存储的基本思想是以关键字Key为自变量,通过一定的函数关系(散列函数或哈希函数),计算出对应的函数值(哈希地址),以这个值作为数据元素的地址,并将数据元素存入到相应地址的存储单元中 ...
- 数据结构---散列表查找(哈希表)概述和简单实现(Java)
散列表查找定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,是的每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到给定值的key的对应f(key) ...
- 算法与数据结构(十二) 散列(哈希)表的创建与查找(Swift版)
散列表又称为哈希表(Hash Table), 是为了方便查找而生的数据结构.关于散列的表的解释,我想引用维基百科上的解释,如下所示: 散列表(Hash table,也叫哈希表),是根据键(Key)而直 ...
- 数据结构(四十二)散列表查找(Hash Table)
一.散列表查找的基础知识 1.散列表查找的定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到 ...
- 【PHP数据结构】散列表查找
上篇文章的查找是不是有意犹未尽的感觉呢?因为我们是真真正正地接触到了时间复杂度的优化.从线性查找的 O(n) 直接优化到了折半查找的 O(logN) ,绝对是一个质的飞跃.但是,我们的折半查找最核心的 ...
- 【哈希表】CodeVs1230元素查找
一.写在前面 哈希表(Hash Table),又称散列表,是一种可以快速处理插入和查询操作的数据结构.哈希表体现着函数映射的思想,它将数据与其存储位置通过某种函数联系起来,其在查询时的高效性也体现在这 ...
随机推荐
- echarts 3D地球实现自动旋转
素材已上传至https://gitee.com/i1520/echarts3DEarth.git https://github.com/i1520/echarts3DEarth 1.引入js文 ...
- Vue.js学习-组件注册与使用
Vue.js学习文档 地址:https://cn.vuejs.org/v2/guide/ 关于自定义组件注册: 建议将<script></script>放在body标签之后 H ...
- k8s 之service资源介绍(三)
kubernetes service资源 apiVersion: v1 kind: Service metadata: name: kubia spec: ports: - port: 80 targ ...
- python的一些包安装
Linux下pip 的安装方法: 使用get-pip.py安装 要安装pip,请安全下载get-pip.py.1: curl https://bootstrap.pypa.io/get-pip.py ...
- Git 冲突:Your local changes would be overwritten by merge. Commit, stash or revert them to proceed.
解决方案有三种: 1,无视,直接commit自己的代码. git commit -m "your msg" 2,stash stash翻译为“隐藏”,如下操作: git stash ...
- centos服务器上线第二个django项目方法。
阿里云服务器开启端口8001,9001 创建一个虚拟环境 virtualenv -p python3 web2 使虚拟环境生效 source web2/bin/activate 虚拟环境中安装djan ...
- Android PKMS服务
它的作用? 关于PKMS的全称是啥应该咱们不陌生,PackageManagerService,和AMS一样是Android系统的核心服务,它主要负责系统中Package的管理,应用程序的安装.卸载.信 ...
- 洛谷P4556 雨天的尾巴(线段树合并)
洛谷P4556 雨天的尾巴 题目链接 题解: 因为一个点可能存放多种物品,直接开二维数组进行统计时间.空间复杂度都不能承受.因为每一个点所拥有的物品只与其子树中的点有关,所以可以考虑对每一个点来建立一 ...
- trait Monad:函数式编程类型系统本博客搜索关键字--类型升降
trait Monad:函数式编程类型系统本博客搜索关键字--类型升降
- Docker Quick Start
翻译自官方Quick Start: https://hub.docker.com/?overlay=onboarding 以Windows为例 1.下载源码 下载构建第一个容器的所需要的所有的东西 需 ...