python爬虫笔记之爬取足球比赛赛程
目标:爬取某网站比赛赛程,动态网页,则需找到对应ajax请求(具体可参考:https://blog.csdn.net/you_are_my_dream/article/details/53399949)
# -*- coding:utf-8 -*-
import sys
import re
import urllib.request link = "https://***"
r = urllib.request.Request(link)
r.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
html = urllib.request.urlopen(r,timeout=500).read()
html = bytes.decode(html,encoding="gbk")
#返回大量json,需提取 #找出返回json中对应正则匹配的字符串
js = re.findall('"n":"(.*?)"',html)
i=0 #循环打印比赛信息
try:
while(1):
#将字符串Unicode转化为中文,并输出
print (js[i].encode('utf-8').decode('unicode_escape'),js[i+1].encode('utf-8').decode('unicode_escape'),"VS",js[i+2].encode('utf-8').decode('unicode_escape'))
i=i+3
#当所有赛程爬取结束时,会报错“IndexError:list index out of range”,所以进行异常处理
except IndexError:
print ("finished")
总结注意点:
1、python 3 采用这个import urllib.request
因为urllib和urllib2合体了。
2、字符串Unicode转为中文需注意python3与python2的表示方法不同:
python3:print 字符串.encode('utf-8').decode('unicode_escape')
python2:print 字符串.decode('unicode_escape')
3、re.findall()
关于这个函数,他的输出内容规律可以参考我之前写的:http://www.cnblogs.com/4wheel/p/8497121.html
【"n":"(.*?)"】 这个表达式只输出(.*?)这部分(为什么,还是参考我之前写的那篇文章),加上问号就是非贪婪模式,不加就是贪婪模式,顺便实践解释下贪婪模式
example:
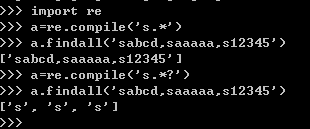
总结:非贪婪模式就是在满足正则表达式的情况下,尽可能少的匹配。
相反,贪婪模式就是在满足正则表达式的情况下,尽可能多的匹配。
so,爬取结果为:

python爬虫笔记之爬取足球比赛赛程的更多相关文章
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- PowerDesigner 在通过jdbc连接数据库时 Could not Initialize JavaVM!
最近用到PowerDesigner的逆向工程,从数据库中逆向生成模型,本想使用odbc连接的,但是需要安装驱动,mysql的还好弄,oracle对我来讲实在是有些麻烦,看到能用jdbc连接,就想试试, ...
- 原生Js汉语拼音首字母匹配城市名/自动提示列表
根据城市的汉语名称首字母把城市排序,基本思路: 1.处理数据,按照需要的格式分别添加{HOT:{hot:[],ABCDEFG:{a:[1,2,3],b:[1,2,3]},HIGHLMN:{},OPQR ...
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- 联想笔记本进入不了BIOS的解决方法
当计算机遇到问题时,很多情况下需要进入BIOS进行解决.但很多新出的联想笔记本电脑在开机时,无论怎么疯狂的按F2,Fn+F2,F12或者Del,都无法进入BIOS,十分气人. 这种现象出现的原因是联想 ...
- 3014C语言_运算符
第四章 运算符 4.1 分类 C语言的运算符范围很广,可分为以下几类: 1.算术运算符:用于各类数值运算.包括加(+).减(-).乘(*).除(/).求余(%).自增(++).自减(--)共七种. 2 ...
- 利用org.mybatis.generator生成实体类
springboot+maven+mybatis+mysql 利用org.mybatis.generator生成实体类 1.添加pom依赖: 2.编写generatorConfig.xml文件 ( ...
- CentOS7.x mini安装OVS
命令均在root用户下运行: 一.关闭防护墙及selinux sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config setenfor ...
- WebService跨域配置、Ajax跨域请求、附开发过程源码
项目开发过程中需要和其他公司的数据对接,当时我们公司提供的是WebService,本地测试,都是好的,Ajax跨域请求,就报错,配置WebService过程中,花了不少功夫,入不少坑,不过最终问题还是 ...
- 系统学习 Java IO (一)----输入流和输出流 InputStream/OutputStream
目录:系统学习 Java IO ---- 目录,概览 InputStream 是Java IO API中所有输入流的父类. 表示有序的字节流,换句话说,可以将 InputStream 中的数据作为有序 ...
- Netty源码分析--Channel注册&绑定端口(下)(七)
接下来,我们看到的就是两个非常重要的方法 就是 processSelectedKeys() 和 runAllTasks() 方法了. selectionKey中ready的事件,如accept.co ...