受限玻尔兹曼机(Restricted Boltzmann Machine)
受限玻尔兹曼机(Restricted Boltzmann Machine)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/


1. 生成模型


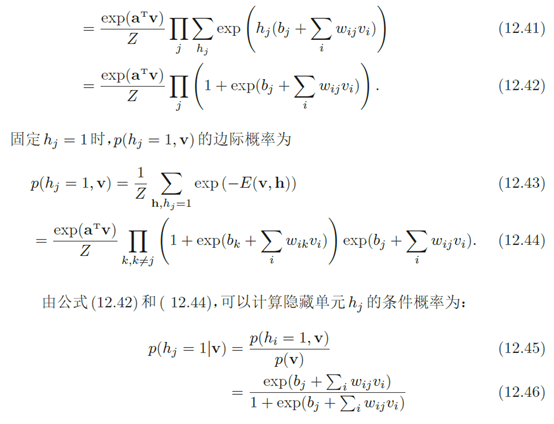

2. 参数学习


3. 对比散度学习算法
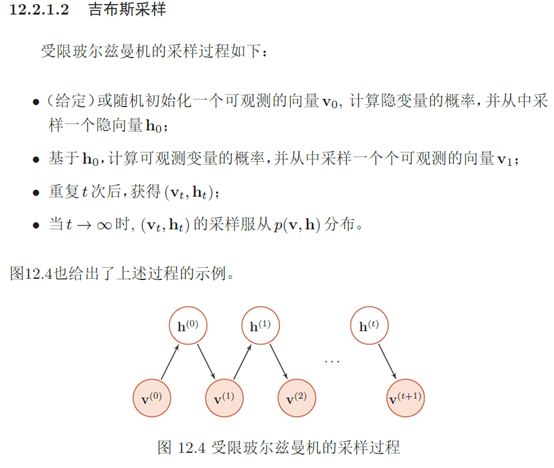
由于受限玻尔兹曼机的特殊结构,因此可以使用一种比吉布斯采样更有效 的学习算法,即对比散度(Contrastive Divergence)对比散度算法仅需k步吉布斯采样。为了提高效率,对比散度算法用一个训练样本作为可观测向量的初始值。然后,交替对可观测向量和隐藏向量进行吉布斯采样,不需要等到收敛,只需要k步就足够了。这就是CD-k 算法。通常,k = 1就可以学得很好。对比散度的流程如算法12.1所示。

4. MATLAB程序解读
% maxepoch -- 最大迭代次数maximum number of epochs
% numhid -- 隐含层神经元数number of hidden units
% batchdata -- 分批后的训练数据集the data that is divided into batches (numcases numdims numbatches)
% restart -- 如果从第1层开始学习,就置restart为1set to 1 if learning starts from beginning %作用:训练RBM,利用1步CD算法 直接调用权值迭代公式不使用反向传播
%可见的、二元的、随机的像素通过对称加权连接连接到隐藏的、二元的、随机的特征检测器
epsilonw = 0.1; % Learning rate for weights 权重学习率 alpha
epsilonvb = 0.1; % Learning rate for biases of visible units 可视层偏置学习率 alpha
epsilonhb = 0.1; % Learning rate for biases of hidden units 隐藏层偏置学习率 alpha
weightcost = 0.0002; %权衰减,用于防止出现过拟合
initialmomentum = 0.5; %动量项学习率,用于克服收敛速度和算法的不稳定性之间的矛盾
finalmomentum = 0.9; [numcases numdims numbatches]=size(batchdata);%[numcases numdims numbatches]=[每批中的样本数 每个样本的维数 训练样本批数] if restart ==1 %是否为重新开始即从头训练
restart=0;
epoch=1; % Initializing symmetric weights and biases. 初始化权重和两层偏置
vishid = 0.1*randn(numdims, numhid);% 连接权值Wij 784*1000
hidbiases = zeros(1,numhid);% 隐含层偏置项bi
visbiases = zeros(1,numdims);% 可视化层偏置项aj poshidprobs = zeros(numcases,numhid); %样本数*隐藏层NN数,隐藏层输出p(h1|v0)对应每个样本有一个输出 100*1000
neghidprobs = zeros(numcases,numhid); %重构数据驱动的隐藏层
posprods = zeros(numdims,numhid); % 表示p(h1|v0)*v0,用于更新Wij即<vihj>data 784*1000
negprods = zeros(numdims,numhid); %<vihj>recon
vishidinc = zeros(numdims,numhid); % 权值更新的增量 ΔW
hidbiasinc = zeros(1,numhid); % 隐含层偏置项更新的增量 1*1000 Δb
visbiasinc = zeros(1,numdims); % 可视化层偏置项更新的增量 1*784 Δa
batchposhidprobs=zeros(numcases,numhid,numbatches); % 整个数据隐含层的输出 每批样本数*隐含层维度*批数
end for epoch = epoch:maxepoch %每个迭代周期
fprintf(1,'epoch %d\r',epoch);
errsum=0;
for batch = 1:numbatches %每一批样本
fprintf(1,'epoch %d batch %d\r',epoch,batch);
%%CD-1
%%%%%%%%% START POSITIVE PHASE 正向梯度%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
data = batchdata(:,:,batch); %data里是100个图片数据
poshidprobs = 1./(1 + exp(-data*vishid - repmat(hidbiases,numcases,1))); %隐藏层输出p(h=1|v0)=sigmod函数=1/(1+exp(-wx-b)) 根据这个分布采集一个隐变量h
batchposhidprobs(:,:,batch)=poshidprobs; %将输出存入一个三位数组
posprods = data' * poshidprobs; %p(h|v0)*v0 更新权重时会使用到 计算正向梯度vh'
poshidact = sum(poshidprobs); %隐藏层中神经元概率和,在更新隐藏层偏置时会使用到
posvisact = sum(data); %可视层中神经元概率和,在更新可视层偏置时会使用到
%%%%%%%%% END OF POSITIVE PHASE %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%gibbs采样
poshidstates = poshidprobs > rand(numcases,numhid); %将隐藏层输出01化表示,大于随机概率的置1,小于随机概率的置0,gibbs抽样,设定状态 %%%%%%%%% START NEGATIVE PHASE 反向梯度%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
negdata = 1./(1 + exp(-poshidstates*vishid' - repmat(visbiases,numcases,1))); %01化表示之后算vt=p(vt|ht-1)重构的数据 p(v=1|h)=sigmod(W*h+a) 采集重构的可见变量v'
neghidprobs = 1./(1 + exp(-negdata*vishid - repmat(hidbiases,numcases,1))); %ht=p(h|vt)使用重构数据隐藏层的输出 p(h=1|v)=sigmod(W'*v+b) 采样一个h'
negprods = negdata'*neghidprobs; %计算反向梯度v'h';
neghidact = sum(neghidprobs);
negvisact = sum(negdata);
%%%%%%%%% END OF NEGATIVE PHASE %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%更新参数
err= sum(sum( (data-negdata).^2 )); %整批数据的误差 ||v-v'||^2
errsum = err + errsum; if epoch>5 %迭代次数不同调整冲量
momentum=finalmomentum;
else
momentum=initialmomentum;
end %%%%%%%%% UPDATE WEIGHTS AND BIASES 更新权重和偏置%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
vishidinc = momentum*vishidinc + ...
epsilonw*( (posprods-negprods)/numcases - weightcost*vishid); %权重的增量 ΔW=alpha*(vh'-v'h')
visbiasinc = momentum*visbiasinc + (epsilonvb/numcases)*(posvisact-negvisact); %可视层增量 Δa=alpha*(v-v')
hidbiasinc = momentum*hidbiasinc + (epsilonhb/numcases)*(poshidact-neghidact); %隐含层增量 Δb=alpha*(h-h') vishid = vishid + vishidinc; %a=a+Δa
visbiases = visbiases + visbiasinc; %W=W+ΔW
hidbiases = hidbiases + hidbiasinc; %b=b+Δb
%%%%%%%%%%%%%%%% END OF UPDATES %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% end
fprintf(1, 'epoch %4i error %6.1f \n', epoch, errsum);
end
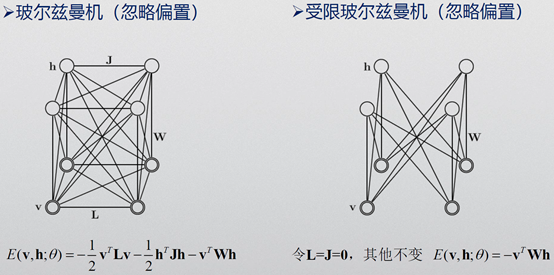
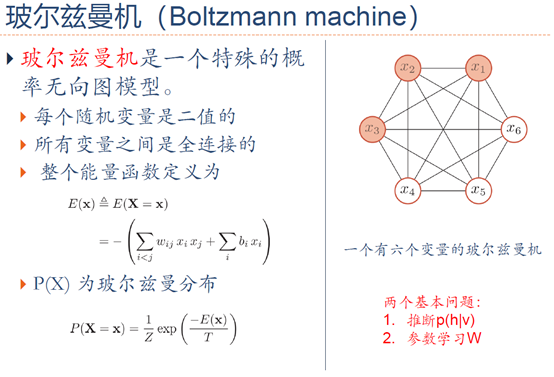
5. 玻尔兹曼机与受限玻尔兹曼机



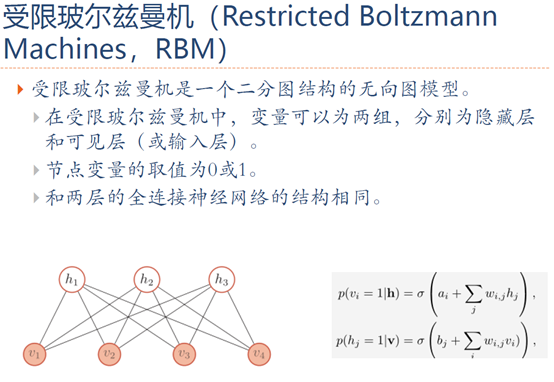
6. 参考文献
[1] 邱锡鹏, 神经网络与深度学习[M]. 2019.
[2] Salakhutdinov R, Hinton G. Deep boltzmann machines[C]//Artificial intelligence and statistics. 2009: 448-455.
[3] Hinton, Training a deep autoencoder or a classifieron MNIST digits. 2006.
[4] Hinton G E. Training products of experts by minimizing contrastive divergence[J]. Neural computation, 2002, 14(8): 1771-1800.
[5] Hinton G E. A practical guide to training restricted Boltzmann machines[M]//Neural networks: Tricks of the trade. Springer, Berlin, Heidelberg, 2012: 599-619.
[8] Deep Learning(深度学习)学习笔记整理系列之(四)
[9] Restricted Boltzmann Machines (RBM)
受限玻尔兹曼机(Restricted Boltzmann Machine)的更多相关文章
- 受限玻尔兹曼机(Restricted Boltzmann Machine, RBM) 简介
受限玻尔兹曼机(Restricted Boltzmann Machine,简称RBM)是由Hinton和Sejnowski于1986年提出的一种生成式随机神经网络(generative stochas ...
- 机器学习理论基础学习19---受限玻尔兹曼机(Restricted Boltzmann Machine)
一.背景介绍 玻尔兹曼机 = 马尔科夫随机场 + 隐结点 二.RBM的Representation BM存在问题:inference 精确:untractable: 近似:计算量太大 因此为了使计算简 ...
- 受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)
这篇写的主要是翻译网上一篇关于受限玻尔兹曼机的tutorial,看了那篇博文之后感觉算法方面讲的很清楚,自己收获很大,这里写下来作为学习之用. 原文网址为:http://imonad.com/rbm/ ...
- 限制玻尔兹曼机(Restricted Boltzmann Machine)RBM
假设有一个二部图,每一层的节点之间没有连接,一层是可视层,即输入数据是(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值)同时假设全概率分布满足Boltzmann 分 ...
- 限制Boltzmann机(Restricted Boltzmann Machine)
起源:Boltzmann神经网络 Boltzmann神经网络的结构是由Hopfield递归神经网络改良过来的,Hopfield中引入了统计物理学的能量函数的概念. 即,cost函数由统计物理学的能量函 ...
- RBM:深度学习之Restricted Boltzmann Machine的BRBM学习+LR分类—Jason niu
from __future__ import print_function print(__doc__) import numpy as np import matplotlib.pyplot as ...
- Boltzmann Machine 玻尔兹曼机入门
Generative Models 生成模型帮助我们生成新的item,而不只是存储和提取之前的item.Boltzmann Machine就是Generative Models的一种. Boltzma ...
- 受限波兹曼机导论Introduction to Restricted Boltzmann Machines
Suppose you ask a bunch of users to rate a set of movies on a 0-100 scale. In classical factor analy ...
- 受限玻尔兹曼机(RBM)原理总结
在前面我们讲到了深度学习的两类神经网络模型的原理,第一类是前向的神经网络,即DNN和CNN.第二类是有反馈的神经网络,即RNN和LSTM.今天我们就总结下深度学习里的第三类神经网络模型:玻尔兹曼机.主 ...
随机推荐
- SQL Server通过函数把逗号分隔的字符串拆分成数据列表的脚本-干货
CREATE FUNCTION [dbo].[Split](@separator VARCHAR(64)=',',@string NVARCHAR(MAX)) RETURNS @ResultTab ...
- [Go] Golang中的面向对象
struct interface 就可以实现面向对象中的继承,封装,多态 继承的演示:Tsh类型继承People类型,并且使用People类型的方法 多态的演示Tsh类型实现了接口Student,实现 ...
- Linux系统学习 八、SSH服务—SSH远程管理服务
1.SSH简介 ssh(安全外壳协议)是Secure Shell的缩写,是建立在应用层和传输层基础上的安全协议.传输的时候是经过加密的,防止信息泄露,比telnet(明文传递)要安全很多. ftp安装 ...
- requests---requests上传图片
我们在做接口测试的时候肯定会遇到一些上传图片,然后进行校验,今天我们一起学习通过requests上传图片,查看是否上传成功 抓取上传接口 这里我以百度为例子进行操作,为啥要用百度呢,主要上传文件比较简 ...
- Java流程控制之顺序结构
概述 在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的.也就是说,程序的流程对运行结果有直接的影响.所以,我们必须清楚每条语句的执行流程.而且,很多时候我们要通过控制语句的执行顺序 ...
- js正则高级函数(replace,matchAll用法),实现正则替换(实测很有效)
有这么一个文档,这是在PC端显示的效果,如果放在移动端,会发现字体大小是非常大的,那么现在想让这个字体在移动端能按照某个比例缩小,后台返回的数据格式是: <html> <head&g ...
- vscode源码分析【一】从源码运行vscode
安装git,nodejs和yarn 安装Python27,3.x版本的不行,确保它在你的环境变量里: 安装gulp npm install --global gulp-cli 安装windows bu ...
- MS SQL OPENJSON JSON
前段时间,有写过一个小练习<MS SQL读取JSON数据>https://www.cnblogs.com/insus/p/10911739.html 晚上为一个网友的问题,尝试获取较深层节 ...
- SQL Server查询某个表被哪些存储过程调用
问题描述: 今天有个同事问到如何查询某个表被哪些存储过程调用, 然后同事说可以用SQL search查询,自己试了一下确实可以 sqlsearch下载说明地址:https://www.cnblogs. ...
- Java13 闪亮来袭,你是否还停留在 Java8
近期 Java 界好消息频传.先是 Java 13 发布,接着 Eclipse 也发布了新版本表示支持新版本的 Java 特性. 本文介绍了 Java 13 的新特性并展示了相关的示例. 2019 年 ...