Hadoop2.8分布式集群安装与测试
1.hadoop2.x 概述
个)。每一个都有相同的职能。一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,standby状态的NameNode就可以转变为active状态的,就可以继续工作了。
个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Network File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享(这也是主流的做法)。JournalNode的架构图如下:
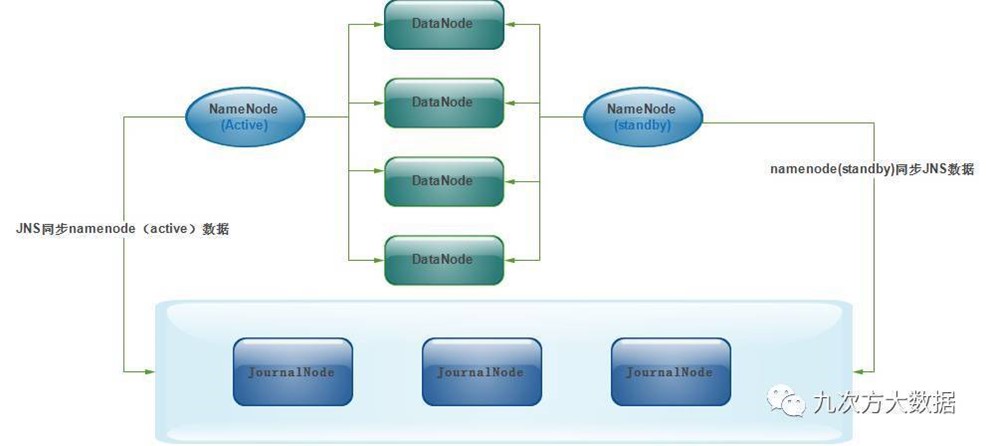
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。来自 <http://www.jianshu.com/p/a1d3028f3e27>

Hadoop安装分为三种方式,分别为单机、伪分布式、完全分布式,安装过程不难,在此主要详细叙述完全分布式的安装配置过程,毕竟生产环境都使用的完全分布式,前两者作为学习和研究使用。按照下述步骤一步一步配置一定可以正确的安装Hadoop分布式集群环境。
2、搭建
2.1 网络环境
|
No. |
Host Name |
IP Address |
Node Type |
User Name |
|
1 |
Maser |
192.168.1.106 |
Name Node |
hadoop/root |
|
2 |
Slave1 |
192.168.1.107 |
Data Node |
hadoop/root |
|
3 |
Slave2 |
192.168.1.108 |
Data Node |
hadoop/root |
2.2、软硬件环境
Centos7.3
Java-1.8.0-openjdk
Hadoop 2.8.1
2.3、环境搭建
All nodes are disabled SELinux and firewalld
All nodes can ping with each other
All nodes have same hadoop directory structure and a same user account
Create a hadoop user, home directory is /home/hadoop, add into root group.
hadoop directory is /usr/local/hadoop, directory owner is hadoop
Master node and slave node can SSH with no password publick key authentication
All nodes have same /etc/hosts, add master node and slave node record line
SSH采用了公钥加密。过程如下:
(1)远程主机收到用户的登录请求,把自己的公钥发给用户。
(2)用户使用这个公钥,将登录密码加密后,发送回来。
(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
3、安装配置java
3.1、安装Java
安装JDK以及配置环境变量,需要以"root"的身份进行
# yum search jdk
# yum -y install java-1.8.0-openjdk*
3.2、配置java环境
新建配置文件etc/profile/java.sh
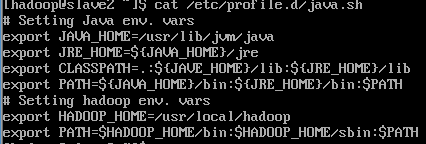
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
3.3、验证
# java -version
# javac -version

4、 安装配置hadoop
4.1 安装
# cd /usr/local/src
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.1/hadoop-2.8.1.tar.gz
# tar -vxzf hadoop-2.8.1
# mv hadoop-2.8.1 ../hadoop
# chown -R hadoop:hadoop hadoop
4.2 配置 hadoop 环境
/etc/profile.d/java
4.3.2 创建hadoop子目录
# cd /usr/local/hadoop
# mkdir tmp hdfs
# cd hdfs
# mkdir name tmp data
4.3 hadoop 配置文件
进入到$HADOOP_HOME/etc/hadoop目录修改配置文件,配置项可参考文档http://hadoop.apache.org/docs/r2.8.0/
4.3.1 hadoop-env.sh
验证
4.3.2 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<final>true</final>
<!--(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹) -->
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<!-- hdfs://Master.Hadoop:22-->
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
4.3.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.3.4 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.3.5 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master.Hadoop:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master.Hadoop:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master.Hadoop:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master.Hadoop:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master.Hadoop:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.3.6 /usr/local/hadoop/etc/hadoop/masters 文件
/usr/local/hadoop/etc/hadoop/slaves
4.4 Slave node 上java/hadoop安装与配置
4.4.1 java/openjdk安装同master node
在master node上
scp /etc/profile.d/java.sh slave1:/etc/profile.d
scp /etc/profile.d/java.sh slave2:/etc/profile.d
4.4.2 Hadoop安装
在master node上
scp -r /usr/local/hadoop slave1:/usr/local
scp -r /usr/local/hadoop slave1:/usr/local
4.4.3 改变权限
chown -R hadoop:hadoop /usr/lib/jvm/java-1.8.0-openjdk-*
chown -R hadoop:hadoop /usr/local/hadoop
5、测试、验证
5.1
$ hadoop namenode -format
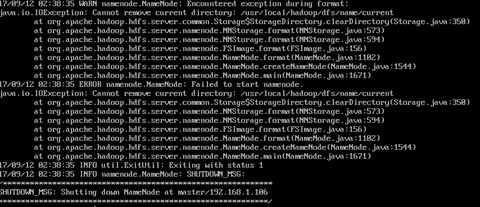
$ start-all .sh
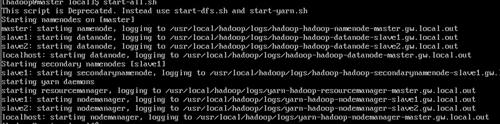
$ ps -ef |grep hadoop

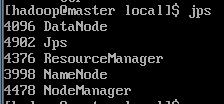
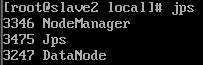
$ jps
master (master)

slave1 (Secondary master)

slave2
5.2 通过网页查看集群
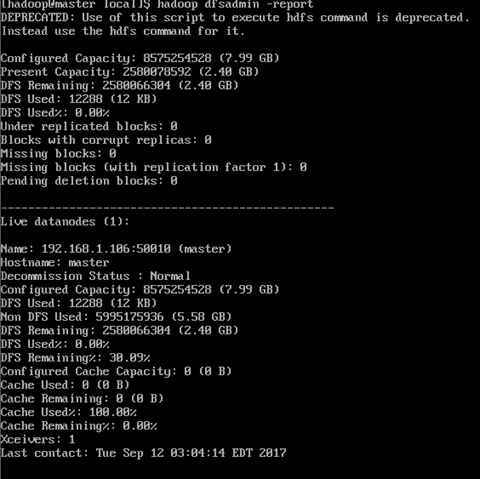
在本地访问HDFS WebUI: http://8088:50070
YARN WebUI: http://master:8088
5.3 向hadoop集群系统提交第一个mapreduce任务(wordcount)
5.3.1 cd /home/hadoop
$ cat >>test.txt<<EOF
Hello World
Hello World
Hello World
Hello World
5.3.2 进入本地hadoop目录(/usr/local/hadoop)
$ hdfs dfs -mkdir -p /data/input在虚拟分布式文件系统上创建一个测试目录/data/input
$ hdfs dfs -put test.txt /data/input 将当前目录下的README.txt 文件复制到虚拟分布式文件系统中
$ hdfs dfs-ls /data/input 查看文件系统中是否存在我们所复制的文件

5.3.3 运行如下命令向hadoop提交单词统计任务
进入jar文件目录,执行下面的指令。
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar \
wordcount \
/data/input /data/output/result
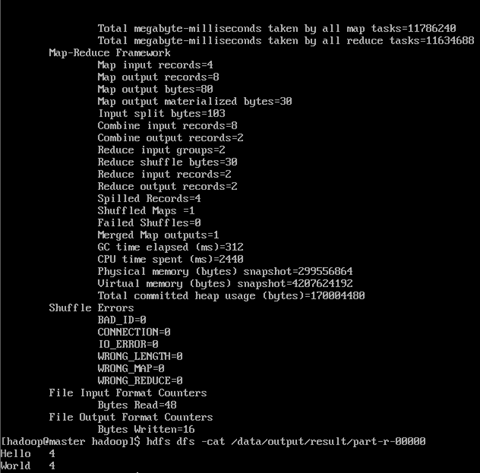
查看result,结果在result下面的part-r-00000中
Hadoop2.8分布式集群安装与测试的更多相关文章
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路. (一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 基于A ...
- 新闻实时分析系统-Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- 新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- 5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01.02.03.04.05.06.07的分布式集群的HA测试 1) weekend01.02的hdfs的HA测试 2) weekend03.04的yarn的HA测试 1) wee ...
随机推荐
- html background-image 图片打开失败的原因
写网页的时候遇到一个问题,在样式表里面引用background-image,没有出现效果.查了一下是提取图片的路径不对,记录下遇到问题以及解决方法. 1.系统自带url 引号问题 这个最坑,以为系统就 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- 简单地认识一下 HTML
简单复盘一下 HTML. 1.HTML 什么是 HTML?HTML 是 Hyper Text Markup Language 的简写,译成中文是「超文本标记语言」. 顾名思义,超文本,就是不止于文本, ...
- Java多线程——锁
Java多线系列文章是Java多线程的详解介绍,对多线程还不熟悉的同学可以先去看一下我的这篇博客Java基础系列3:多线程超详细总结,这篇博客从宏观层面介绍了多线程的整体概况,接下来的几篇文章是对多线 ...
- 单核苷酸多态性SNP(single nucleotide polymorphism)
定义 主要指基因组水平上由单个核苷酸的变异所引起的 DNA 序列多态性. 在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性.即:在不同个体的同一条染色体或同一位点的核苷酸序列中,绝大多数核苷酸 ...
- 深入理解inode和硬链接和软连接和挂载点
inode 一.inode是什么? 理解inode,要从文件储存说起. 扇区 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector).每个扇区储存512字节(相当于0.5 ...
- VisualStudio2012编辑器错误
https://blogs.msdn.microsoft.com/webdev/2014/11/11/dialog-box-may-be-displayed-to-users-when-opening ...
- javaSE笔记(重点部分)
Java 基础篇 数据类型 基本数据类型 由于java是强类型语言,所以要进行有些运算的时候,需要用到类型转换. 低-----------------------------高 byte,short, ...
- ModelArts微认证零售客户分群知识点总结
\ 作者:华为云MVP郑永祥
- python读写配置文件使用总结与避坑指南
关于今天的内容 最近拿python在写项目部署的相关集成代码,本来两天的工作量,硬是在来回的需求变更中,拖到了一周的时间.今天算是暂时告一段落了.这次由于涉及多个系统的调用和配置参数,代码开发中出现了 ...