新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装
Hadoop 版本选择目前主要基于三个厂商(国外)如下所示:
1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进。
2.基于HortonWorks厂商的开源免费的hdp版本。
3.基于Cloudera厂商的cdh版本,Cloudera有免费版和企业版, 企业版只有试用期。不过cdh大部分功能都是免费的。
(二)hadoop2.x分布式集群配置
1.集群资源规划设计
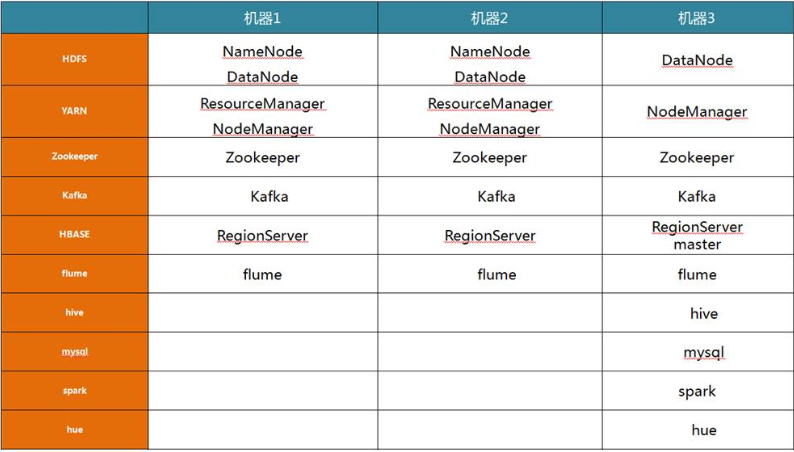
2.hadoop2.x分布式集群配置
1)hadoop2.x分布式集群配置-HDFS
安装hdfs需要修改4个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml和slaves
2)hadoop2.x分布式集群配置-YARN
安装yarn需要修改4个配置文件:yarn-env.sh、mapred-env.sh、yarn-site.xml和mapred-site.xml
(三)分发到其他各个机器节点
hadoop相关配置在第一个节点配置好之后,可以通过脚本命令分发给另外两个节点即可,具体操作如下所示。
#将安装包分发给第二个节点
scp -r hadoop-2.5.0 kaf@bigdata-pro02.kfk.com:/opt/modules/
#将安装包分发给第三个节点
scp -r hadoop-2.5.0 kaf@bigdata-pro02.kfk.com:/opt/modules/
(四)HDFS启动集群运行测试
hdfs相关配置好之后,可以启动hdfs集群。
1.格式化NameNode
通过命令:bin/hdfs namenode -format 格式化NameNode。
2.启动各个节点机器服务
1)启动NameNode命令:sbin/hadoop-daemon.sh start namenode
2) 启动DataNode命令:sbin/hadoop-daemon.sh start datanode
3)启动ResourceManager命令:sbin/yarn-daemon.sh start resourcemanager
4)启动NodeManager命令:sbin/yarn-daemon.sh start resourcemanager
5)启动log日志命令:sbin/mr-jobhistory-daemon.sh start historyserver
(五)YARN集群运行MapReduce程序测试
前面hdfs和yarn都启动起来之后,可以通过运行WordCount程序检测一下集群是否能run起来。
集群自带的WordCount程序执行命令:bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount input output
(六)ssh无秘钥登录
在集群搭建的过程中,需要不同节点分发文件,那么节点间分发文件每次都需要输入密码,比较麻烦。另外在hadoop 集群启动过程中,也需要使用批量脚本统一启动各个节点服务,此时也需要节点之间实现无秘钥登录。具体操作步骤如下所示:
1.主节点上创建 .ssh 目录,然后生成公钥文件id_rsa.pub和私钥文件id_rsa
mkdir .ssh
ssh-keygen -t rsa
2.拷贝公钥到各个机器
ssh-copy-id bigdata-pro1.kfk.com
ssh-copy-id bigdata-pro2.kfk.com
ssh-copy-id bigdata-pro3.kfk.com
3.测试ssh连接
ssh bigdata-pro1.kfk.com
ssh bigdata-pro2.kfk.com
ssh bigdata-pro3.kfk.com
4.测试hdfs
ssh无秘钥登录做好之后,可以在主节点通过一键启动命令,启动hdfs各个节点的服务,具体操作如下所示:
sbin/start-dfs.sh
如果yarn和hdfs主节点共用,配置一个节点即可。否则,yarn也需要单独配置ssh无秘钥登录。
(七)配置集群内机器时间同步(使用Linux ntp进行)
选择一台机器作为时间服务器,比如bigdata-pro1.kfk.com节点。
1.查看ntp服务是否已经存在
sudo rpm -qa|grep ntp
2.ntp服务相关操作
1)查看ntp状态
sudo service ntpd status
2)启动ntp
sudo service ntpd start
3)关闭ntp
sudo service ntpd stop
3.设置ntp随机器启动
sudo chkconfig ntpd on
4.修改ntp配置文件
vi /etc/ntp.conf
#释放注释并将ip地址修改为
restrict 192.168.31.151 mask 255.255.255.0 nomodify notrap
#注释掉以下命令行
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#释放以下命令行
server 127.127.1.0 #local clock
fudge 127.127.1.0 stratum 10
重启ntp服务
sudo service ntpd restart
5.修改服务器时间
#设置当前日期
sudo date -s 2017-06-16
#设置当前时间
sudo date -s 22:06:00
6.其他节点手动同步主服务器时间
#查看ntp位置
which ntpdate
/usr/sbin/ntpdate
1)手动同步bigdata-pro2.kfk.com节点时间
sudo /usr/sbin/ntpdate bigdata-pro2.kfk.com
2)手动同步bigdata-pro3.kfk.com节点时间
sudo /usr/sbin/ntpdate bigdata-pro3.kfk.com
7.其他节点定时同步主服务器时间
bigdata-pro2.kfk.com和bigdata-pro3.kfk.com节点分别切换到root用户, 通过crontab -e 命令,每10分钟同步一次主服务器节点的时间。
crontab -e
#定时,每隔10分钟同步bigdata-pro1.kfk.com服务器时间
0-59/10 * * * * /usr/sbin/ntpdate bigdata-pro1.kfk.com
新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署的更多相关文章
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——16、Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述 (二)Hive在Hadoop生态圈中的位置 (三)Hive 架构设计 (四)Hive 的优点及应用场景 (五)Hive 的下载和安装部署 1.Hive 下载 Apache版本的H ...
随机推荐
- 四种常见的数据结构、LinkedList、Set集合、Collection、Map总结
四种常见的数据结构: 1.堆栈结构: 先进后出的特点.(就像弹夹一样,先进去的在后进去的低下.) 2.队列结构: 先进先出的特点.(就像安检一样,先进去的先出来 ...
- Django - Form嵌套的Meta类 + 为什么type()能创建类
Form里面嵌套了一个Meta类 class PostForm(forms.ModelForm): class Meta: model = Post # field to be exposed fie ...
- 4_5 追踪电子表格中的单元格(UVa512)(选做)
在电子表格中的数据都存储在单元格中,它是按行和列(R)(C).一些在电子表格上的操作可以应用于单个单元格(研发),而其他的可以应用于整个行或列.典型的单元操作包括插入和删除行或列和交换单元格内容.一些 ...
- 三分钟让你秒懂.Net生态系统
提到.Net的时候,大多数人的第一反应可能就是.Net Framework和Visual Studio..Net Framework的第一个版本发布与2002年2月13日,这对于科技发展日新月异的时代 ...
- Java 数据脱敏 工具类
一.项目导入Apache的commons的Jar包. Jar包Maven下载地址:https://mvnrepository.com/artifact/org.apache.commons/commo ...
- The Captain 题解
20200216题目题解 这是一篇题解祭题解记,但一共就一道题目.(ROS菜大了) 题目如下: The Captain 给定平面上的n个点,定义(x1,y1)到(x2,y2)的费用为min(|x1-x ...
- nginx、apache和tomcat之间的关系和区别
Apache/Nginx 应该叫做 HTTP Server,即安装后生成httpd服务. Tomcat 则是一个 Application Server,或者更准确的来说,是一个「Servlet/JSP ...
- Python - unittest打印成功信息
参考 https://stackoverflow.com/questions/36834677/print-success-messages-for-asserts-in-python 总结 clas ...
- JavaScript - Array对象,数组
1. 创建数组 方式1. new关键字 var arr = new Array(1, 2, 3); 方式2. 使用字面量创建数组对象 var arr = [1, 2, 3]; 2. 检测一个对象是否是 ...
- 记一次RocketMQ源码导入IDEA过程
首先,下载源码,可以官网下载source包,也可以从GitHub上直接拉下来导入IDEA.如果是官网下载的source zip包,直接作为当前project的module导入,这里不赘述太多,只强调一 ...