happy machine learning(First One)
从前几天起我就开始了愉快的机器学习,这里记录一下学习笔记,我看的是吴恩达老师的视频,这篇博客将会按吴老师的教学目录来集合各优良文章,以及部分的我的个人总结
1、 监督学习与无监督学习
监督:给定一个算法,需要部分数据集有正确的答案
分类和回归:给定一个样本特征 , 我们希望预测其对应的属性值 , 如果 是离散的, 那么这就是一个分类问题,反之,如果 是连续的实数, 这就是一个回归问题。
无监督学习:
聚类算法:给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
鸡尾酒聚会算法:https://blog.csdn.net/mrharvey/article/details/18598605
2、 代价函数
实质为线性函数的拟合度问题
参考https://www.cnblogs.com/luozhenj/articles/7639484.html
相应的代码(python)
https://o-my-chenjian.com/2017/05/26/Cost-Function-Of-ML/
3、梯度下降
这玩意跟dfs一样,拿吴老师的举例,下山,每一步找最陡的下去,最终到最低点
这篇文章写的比较好 https://www.jianshu.com/p/c7e642877b0e
4、多项式回归
概念见这篇文章:https://blog.csdn.net/zoe9698/article/details/82386914
实践见这篇:https://www.cnblogs.com/Belter/p/8530222.html
5、正规方程
公式推导:https://blog.csdn.net/zoe9698/article/details/82419330
python实现:https://www.lmlphp.com/user/3178/article/item/27041/
接下来就是与识别有关的内容,首先是分类问题
6、分类
理论介绍:https://www.cnblogs.com/lsyz/p/8711103.html
然后我找到了skleran这个库,尝试去编写一些代码来进行分析
今天先学会怎么生成数据吧23333
from sklearn import datasets#引入数据集 #构造的各种参数可以根据自己需要调整 X,y=datasets.make_regression(n_samples=200,n_features=2,n_targets=2,noise=1) ###绘制构造的数据### import matplotlib.pyplot as plt plt.figure() plt.scatter(X,y) plt.show()
还有那啥datatest.load_xxxx
今天继续学习这个库
首先是KNN
import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = datasets.load_iris() iris_X = iris.data iris_Y = iris.target # print(iris_X[:2,:]) # print(iris_Y) ##将上面的数据集分成测试集和训练集,其中测试集占30% X_train,X_test,Y_train,Y_test = train_test_split(iris_X,iris_Y,test_size=0.3) ##此时数据打乱了 #print(Y_train) knn = KNeighborsClassifier() ##训练 knn.fit(X_train,Y_train) ##预测是哪种花 print(knn.predict(X_test)) ##打印真实值 print(Y_test)
下面是聚类,2到多维
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2,0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
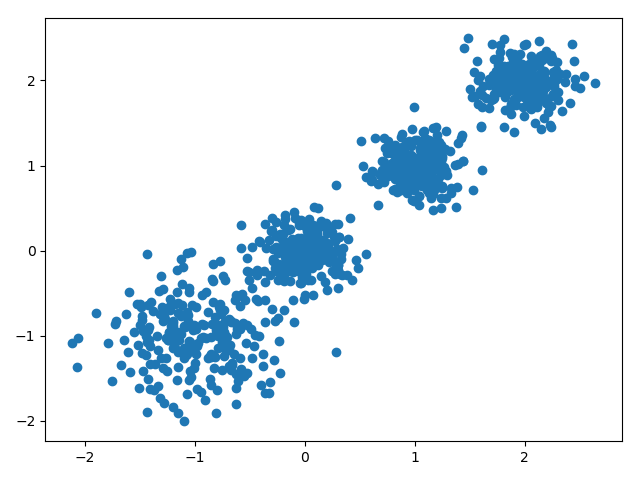
我们改一下数据来看一下效果
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.3, 0.2,0.1]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.3, 0.2, 0.1],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
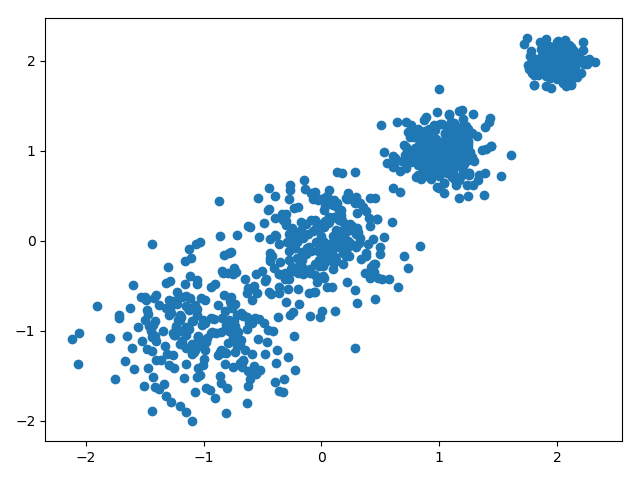
所以差不多应该能理解对应参数的含义了吧,这是二维数据和二维特征
我们用K-Means聚类方法来做聚类,首先选择k=2
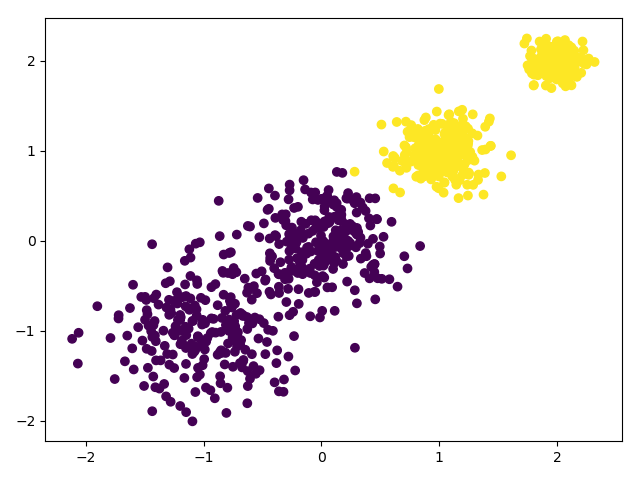
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.3, 0.2, 0.1],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
k=3,4只需改一下clusters
我们选择一个效果评判函数:
from sklearn import metrics metrics.calinski_harabaz_score(X, y_pred)
下面是相应的kmeans理论:https://www.cnblogs.com/bourneli/p/3645049.html
happy machine learning(First One)的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- [Machine Learning] Active Learning
1. 写在前面 在机器学习(Machine learning)领域,监督学习(Supervised learning).非监督学习(Unsupervised learning)以及半监督学习(Semi ...
- [Machine Learning & Algorithm]CAML机器学习系列2:深入浅出ML之Entropy-Based家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 写在前面 记得在<Pattern Recognition And Machine ...
- machine learning基础与实践系列
由于研究工作的需要,最近在看机器学习的一些基本的算法.选用的书是周志华的西瓜书--(<机器学习>周志华著)和<机器学习实战>,视频的话在看Coursera上Andrew Ng的 ...
- matlab基础教程——根据Andrew Ng的machine learning整理
matlab基础教程--根据Andrew Ng的machine learning整理 基本运算 算数运算 逻辑运算 格式化输出 小数位全局修改 向量和矩阵运算 矩阵操作 申明一个矩阵或向量 快速建立一 ...
- Machine Learning
Recently, I am studying Maching Learning which is our course. My English is not good but this course ...
随机推荐
- 开发Android项目中使用androidannotations
前言 最近接手了一个工程,使用了androidannotations,因为以前使用过butterknife所以有似曾相识的感觉,但是有些用法还是不一样,所以就花时间学习了下androidannotat ...
- eclipse中JUnit工具的使用
- HDU 4861(多校)1001 Couple doubi
Problem Description DouBiXp has a girlfriend named DouBiNan.One day they felt very boring and decide ...
- WPF“天狗食月”效果
原文:WPF"天狗食月"效果 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/yangyisen0713/article/deta ...
- 获取root权限及破解原理分析
2012-03-18 17:58:45| 分类: android |字号 订阅 如今Android系统的root破解基本上成为大家的必备技能!网上也有非常多中一键破解的软件,使root破解越来越ea ...
- WPF太阳、地球、月球运动轨迹模拟
原文:WPF太阳.地球.月球运动轨迹模拟 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/yangyisen0713/article/details/ ...
- InitializeComponent无法识别的问题
学习Xamarin官方文档的时候,Xamarin.Forms的开始篇一直在用ContentPage讲解自己一直是创建Page,然后手动修改成继承于ContentPage,然后InitializeCom ...
- SVN如何迁徙到Git
由于一直都是采用SVN作为源码管理,转到Git不能从头开始吧~~下面就具体说说如何将SVN已有的项目工程迁徙到Git上面 步骤 (1) 安装Git客户端程序(2) 将SVN上面的工程通过Git克隆到本 ...
- WPF依赖属性对内存的使用方式
WPF允许对象在创建时候并不包含存储数据的空间,只保留在用到时获取数据默认值,借用其他对象数据或者实时分配空间的能力
- 微服务架构之「 下一代微服务 Service Mesh 」
Service Mesh 被大家称为下一代的微服务,是微服务领域的一颗新星,被大家讨论的非常多. 我在大家的讨论中,还看到有人说 “目前的微服务架构我都没学会呢,现在又来一个下一代微服务,真学不动了” ...