简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页

这是简易数据分析系列的第 8 篇文章。
我们在Web Scraper 翻页——控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法。
但是你在预览一些网站时,会发现随着网页的下拉,你需要点击类似于「加载更多」的按钮去获取数据,而网页链接一直没有变化。
所以控制链接批量抓去数据的方案失效了,所以我们需要模拟点击「加载更多」按钮,去抓取更多的数据。
今天我们讲的,就是利用 web scraper 里的 Element click 模拟点击「加载更多」,去加载更多的数据。
这次的练习网站,我们拿少数派网站的热门文章作为我们的练习对象,对应的网址链接是:
https://sspai.com/tag/%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home
为了复习上一个小节的内容,这次我们模拟点击翻页的同时,还要抓取多条内容,包括作者、标题、点赞数和评论数。
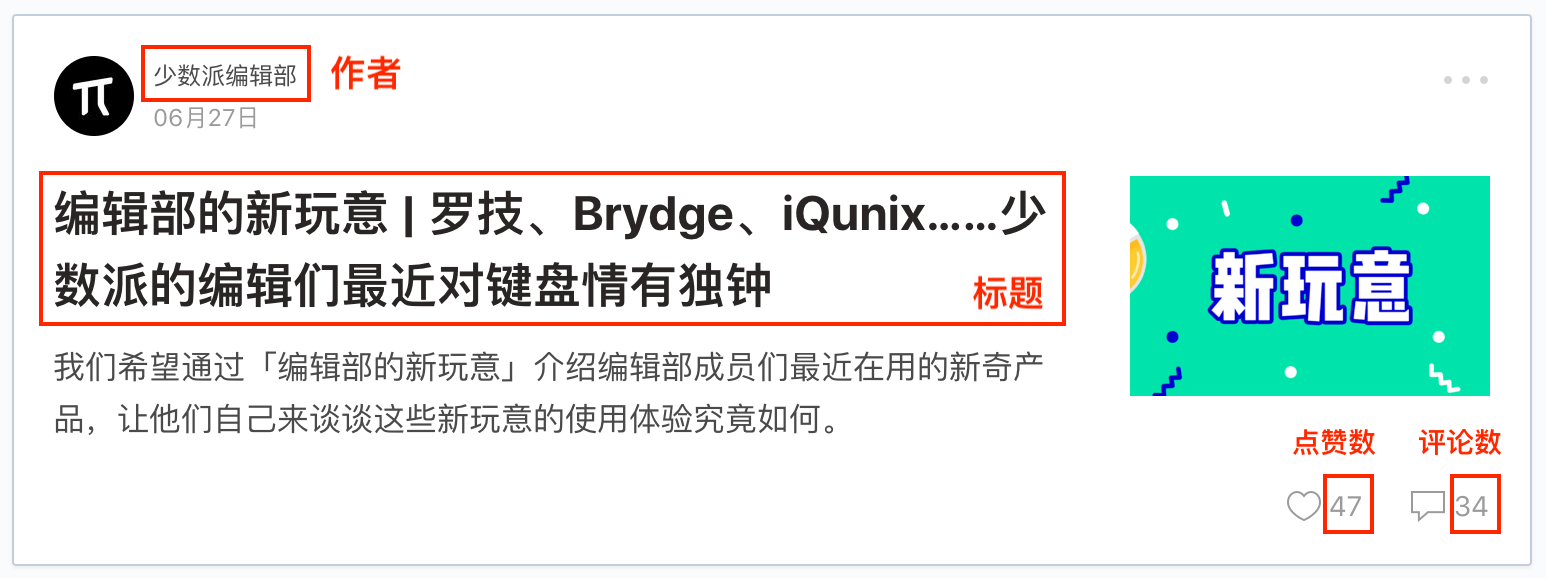
下面开始我们的数据采集之路。
1.创建 sitmap
老规矩,第一步我们先创建一个少数派的 sitmap,取名为 sspai_hot,起始链接为 https://sspai.com/tag/%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home。

2.创建容器的 selector
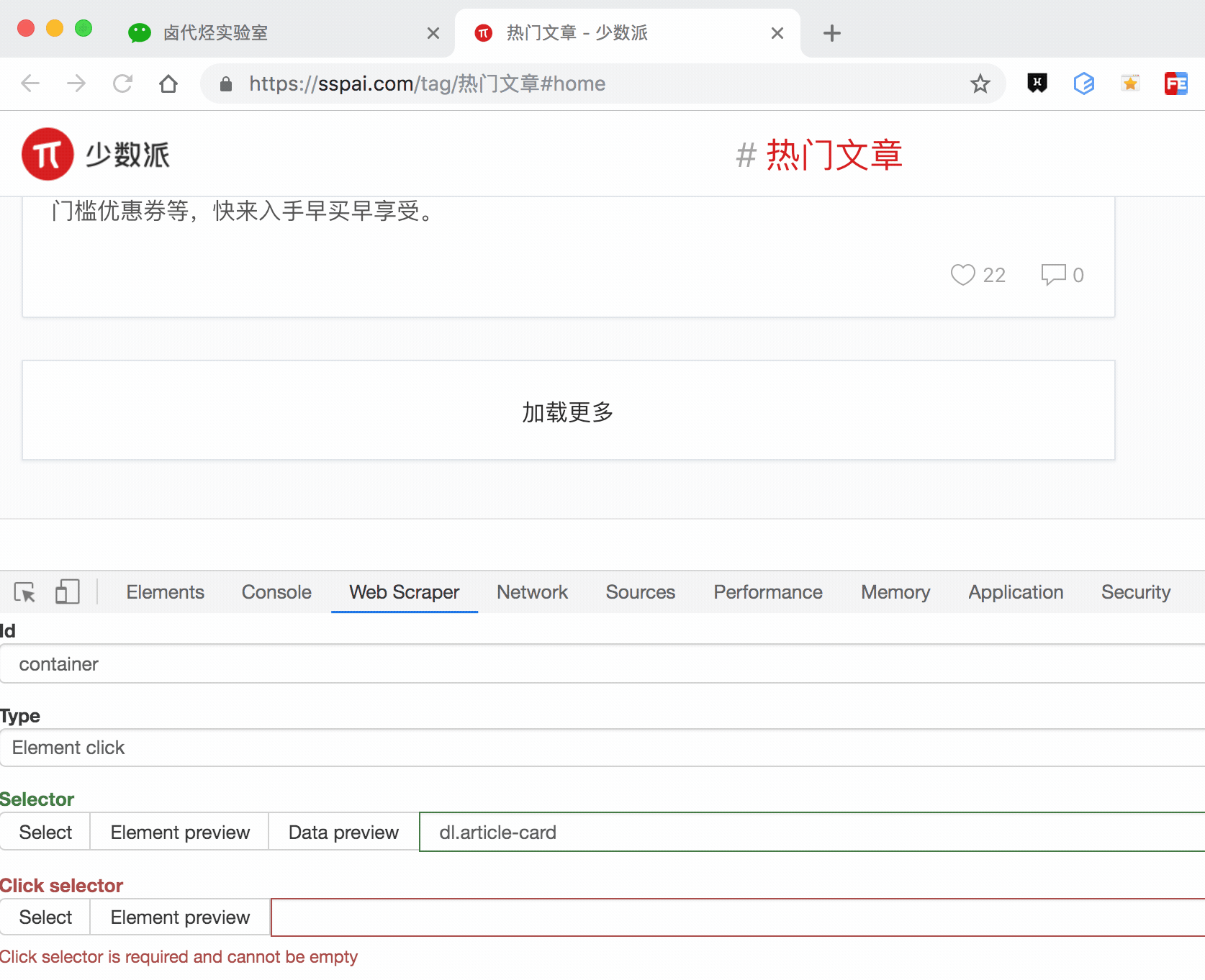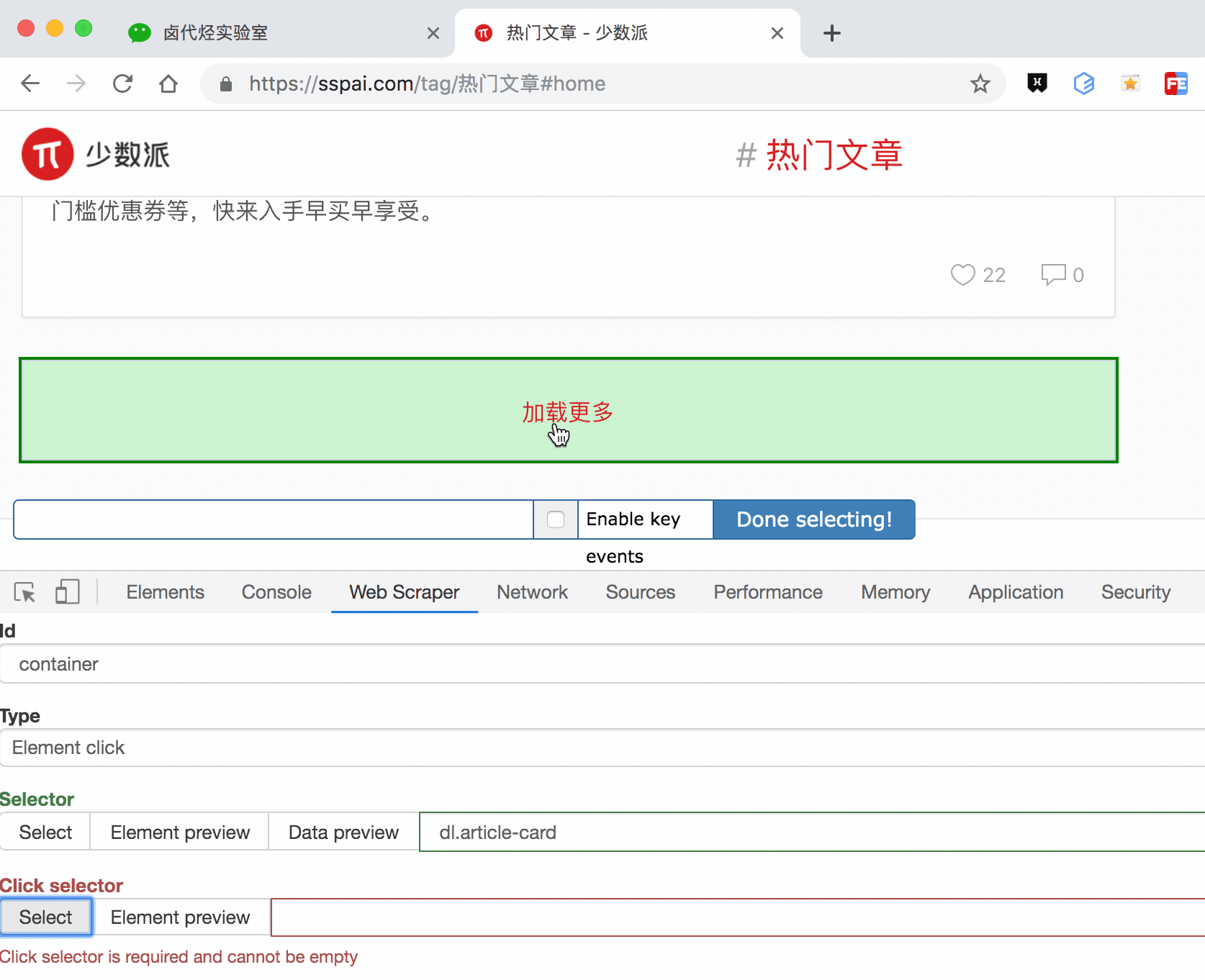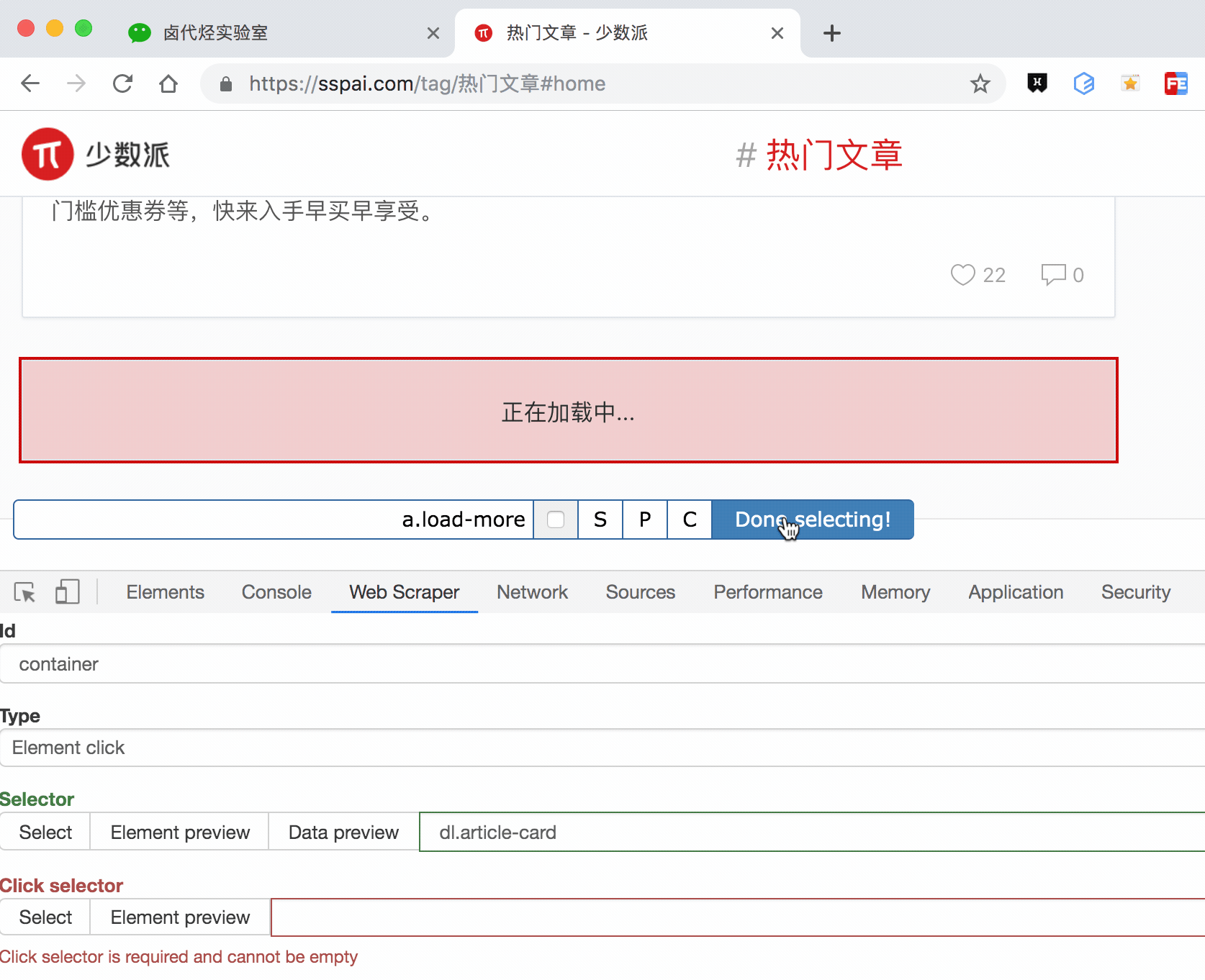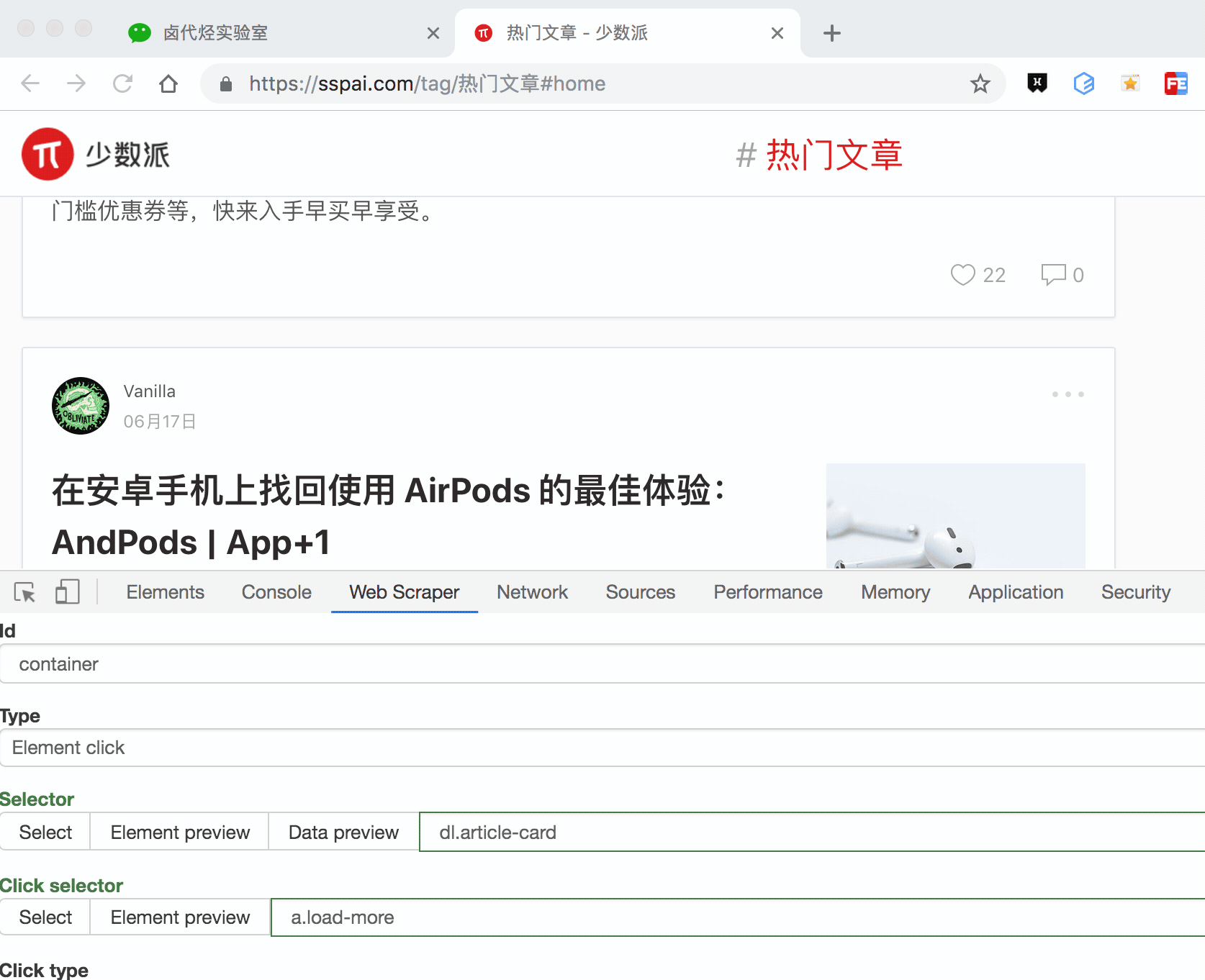
通过上一节的内容,我们知道想在 web scraper 里想抓取多种类型的数据,必须先创建一个容器(container),这个容器包含多种类型的数据,所以我们第二步就是要创建容器的 selector。
要注意的是,这个 selector 的 Type 类型选为 Element click,翻译成中文就是模拟点击元素,意如其名,我们可以利用这种类型模拟点击「加载更多」按钮。
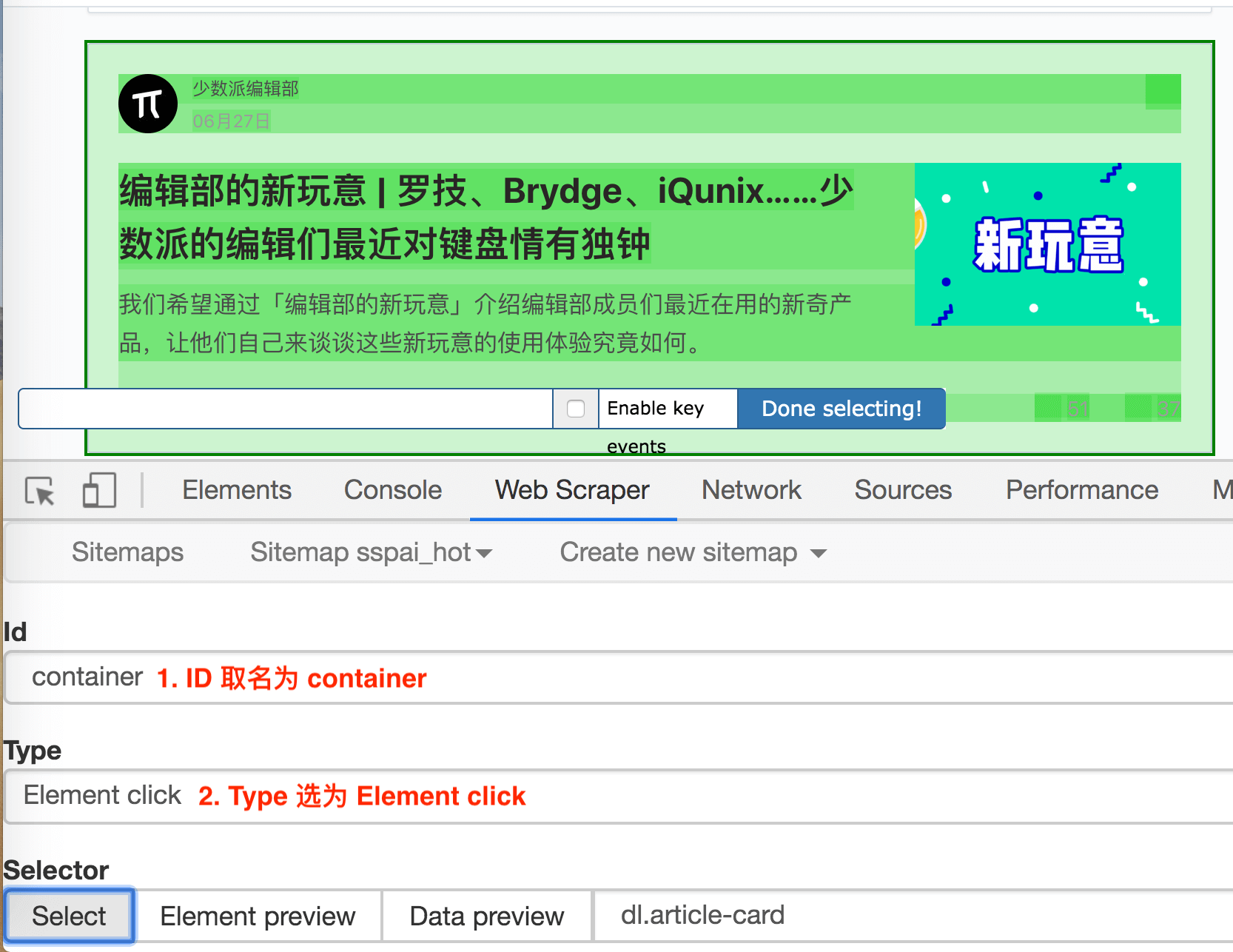
这种类型的 selector,会多出几个选项,第一个就是 Click selector,这个就是选择「加载更多」按钮的,具体操作可见下图的动图。
还有几个多出来的选项,我们一一解释一下:

1.Click type
点击类型,click more 表示点击多次,因为我们要抓取批量数据,这里就选择 click more,还有一个 click once 选项,点击一次
2.Click element uniqueness
这个选项是控制 Web Scraper 什么时候停止抓取数据的。比如说 Unique Text,表示文字改变时停止抓取数据。
我们都知道,一个网站的数据不可能是无穷无尽的,总有加载完的时候,这时候「加载更多」按钮文字可能就变成「没有更多」、「没有更多数据」、「加载完了」等文字,当文字变动时,Web scraper 就会知道没有更多数据了,会自动停止抓取数据。
3.Multiple
这个我们的老朋友了,表示是否多选,这里我们要抓取多条数据,当然要打勾。
4.Discard initial elements
是否丢弃初始元素,这个主要是去除一些网站的重复数据用的,不是很重要,我们这里也用不到,直接选择 Never discard,从不丢弃数据。
5.Delay
延迟时间,因为点击加载更多后,数据加载需要一段时间,delay 就是等待数据加载的时间。一般我们设置要大于等于 2000,因为延迟 2s 是一个比较合理的数据,如果网络不好,我们可以设置更大的数字。
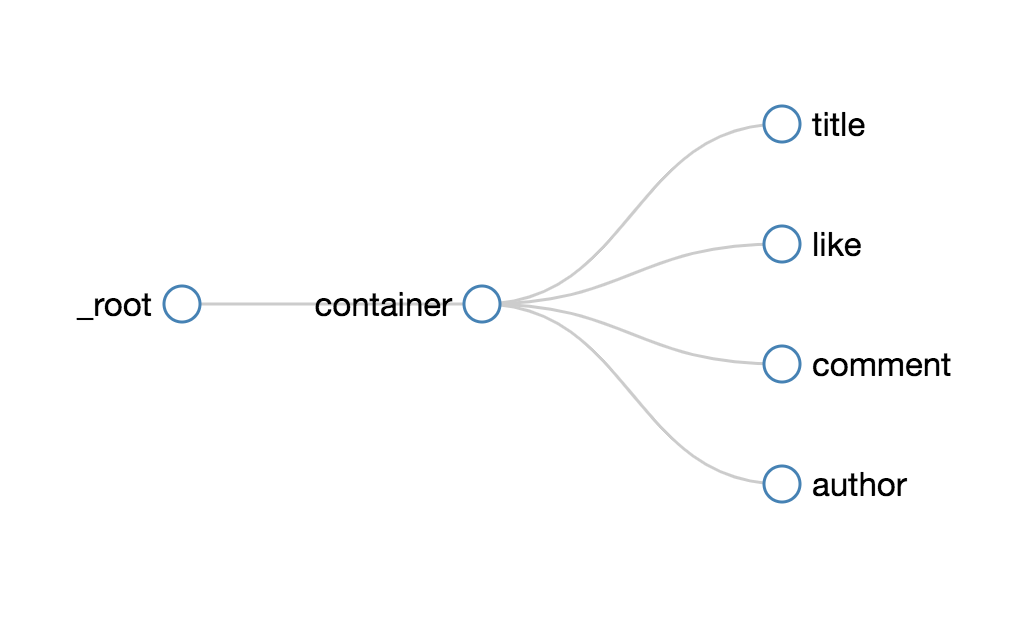
3.创建子选择器
接下来我们创建几个子选择器,分别抓取作者、标题、点赞数和评论数四种类型的数据,详细操作我在上一篇教程中已经说明了,这里我就不详细说明了。整个爬虫的结构如下,大家可以参考一下:
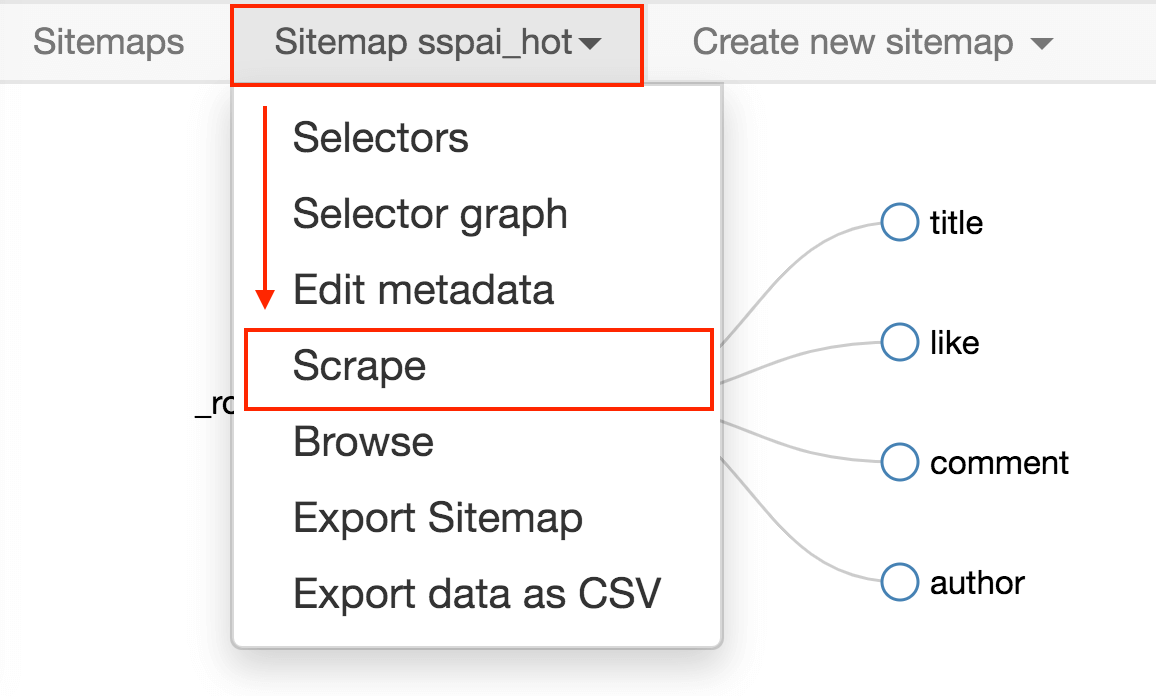
4.抓取数据
按照 Sitemap spay_hot -> Scrape 的操作路径就可以抓取数据了。
今天我们学习了通过 Web Scraper 抓取点击加载更多类型的网页。实践过程中,你会发现这种类型的网页无法控制爬取数目,不像豆瓣 TOP250,明明白白就是 250 条数据,不多也不少。下一篇我们就聊聊,如何利用 Web Scraper,自动控制抓取的数目。
推荐阅读
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫
简易数据分析 07 | Web Scraper 抓取多条内容

简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页的更多相关文章
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 02 | Web Scraper 的下载与安装
这是简易数据分析系列的第 2 篇文章. 上篇说了数据分析在生活中的重要性,从这篇开始,我们就要进入分析的实战内容了.数据分析数据分析,没有数据怎么分析?所以我们首先要学会采集数据. 我调研了很多采集数 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
随机推荐
- ABP开发框架前后端开发系列---(13)高级查询功能及界面的处理
在一般的检索界面中,基于界面易用和美观方便的考虑,我们往往只提供一些常用的条件查询进行列表数据的查询,但是有时候一些业务表字段很多,一些不常见的条件可能在某些场景下也需要用到.因此我们在通用的查询条件 ...
- django-haystack+whoosh+jieba实现中文全文搜索
先上效果图 附上个人网站:https://liyuankun.cn 安装依赖库 注意:这里我们不安装django-haystack,因为要添加中文分词的功能很麻烦,所以我直接集成了一个中文的djang ...
- vs 编译说明
静态编译/MT,/MTD 是指使用libc和msvc相关的静态库(lib). 动态编译,/MD,/MDd是指用相应的DLL版本编译. 其中字母含义 d:debug m:multi-th ...
- HDU 1394:Minimum Inversion Number(线段树区间求和单点更新)
http://acm.hdu.edu.cn/showproblem.php?pid=1394 Minimum Inversion Number Problem Description The in ...
- 自动化冒烟测试 Unittest , Pytest 哪家强?
前言:之前有一段时间一直用 Python Uittest做自动化测试,觉得Uittest组织冒烟用例比较繁琐,后来康哥提示我使用pytest.mark来组织冒烟用例 本文讲述以下几个内容: 1.Uni ...
- dapper支持DataSet
在源代码中添加 /// <summary> /// describe:支持 DataSet /// </summary> /// <param name="cn ...
- bzoj1584 9.20考试 cleaning up 打扫卫生
1584: [Usaco2009 Mar]Cleaning Up 打扫卫生 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 549 Solved: 38 ...
- 求1-2/3+3/5-4/7+......49/97和(C语言实现)
一.功能需求 求1 - 2/3 + 3/5 - 4/7 + ......49/97的和 C语言等级考试中也有涉及到类似的需求. 二.代码分析 仔细查看功能需求,可以发现这个等式的三个规律: 1.从每一 ...
- Jmeter自定义Java请求开发
一.本次实验目的 IDEA新建maven项目,使用java开发自定义jmeter的请求. 本次开发使用的代码,会百度云分享给大家. 二.本次实验环境 Idea 2017.02 Jmeter 5.1.1 ...
- 使用gulp构建微信小程序工作流
前言 刚入门微信小程序的时候,一切都基于微信web开发者工具,没有使用其他框架,也没有工程化的概念.当时做的项目都比较简单,单单用微信web开发者工具倒也得心应手.学了些东西后,就按捺不住地想跳出原生 ...