Hadoop 数据去重
数据去重这个实例主要是为了读者掌握并利用并行化思想对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
1.实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入:
file1:
2006-6-9 a
2006-6-10 b
2006-6-11 c
2006-6-12 d
2006-6-13 a
2006-6-14 b
2006-6-15 c
2006-6-11 c
file2:
2006-6-9 b
2006-6-10 a
2006-6-11 b
2006-6-12 d
2006-6-13 a
2006-6-14 c
2006-6-15 d
2006-6-11 c
运行结果:
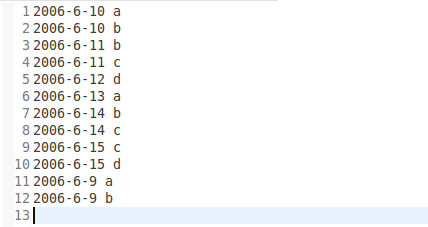
2.设计思路
数据去重实例的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台Reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是Reduce的输入应该以数据作为key,而对value-list则没有要求。当Reduce接收到一个<key,value-list>时就直接将key复制到输出的key中,并将value设置成空值。在MapReduce流程中,Map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会被交给Reduce。所以从设计好的Reduce输入可以反推出Map输出的key应为数据,而value为任意值。继续反推,Map输出的key为数据。而在这个实例中每个数据代表输入文件中的一行内容,所以Map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将value设置成key,并直接输出(输出中的value任意)。Map中的结果经过shuffle过程之后被交给Reduce。在Reduce阶段不管每个key有多少个value,都直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空)
3.程序代码:
程序代码如下:
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class Dedup { // map 将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text line = new Text();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
line = value;
context.write(line, new Text(""));
}
} // reduce 将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Data Deduplication");
job.setJarByClass(Dedup.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1);
} }
Hadoop 数据去重的更多相关文章
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- hadoop mapreduce实现数据去重
实现原理分析: map函数数将输入的文本按照行读取, 并将Key--每一行的内容 输出 value--空. reduce 会自动统计所有的key,我们让reduce输出key-> ...
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- map/reduce实现数据去重
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.co ...
- MapReduce实例(数据去重)
数据去重: 原理(理解):Mapreduce程序首先应该确认<k3,v3>,根据<k3,v3>确定<k2,v2>,原始数据中出现次数超过一次的数据在输出文件中只出现 ...
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- hadoop数据流转过程分析
hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转. hadoop:数据流转图(基于hadoop 0.18.3): 这里使用一个例子说明ha ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- MYSQL数据去重与外表填充
经常要对数据库中的数据进行去重,有时还需要使用外部表填冲数据,本文档记录数据去重与外表填充数据. date:2016/8/17 author:wangxl 1 需求 对user_info1表去重,并添 ...
随机推荐
- Android回调监听的实现
一.首先定义监听函数 public interface OnKeyValueListener { void getKeyValueClick(String value); } 二.在需要传递内容的 A ...
- day20包
https://www.cnblogs.com/Eva-J/articles/7292109.html 一.模块: 1.什么是模块:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名 ...
- PLSQL僵死
同样的SQL语句,同一数据库,但在不同的PLSQL中执行,出现僵死的问题. 修改SQLNET.ORA文件的SQLNET.EXPIRE_TIME值为10,10为默认值.
- [原创]免固件开发USB2.0 FPGA方案 速度40Mbyte/s+
USB 2.0接口,实测速度40Mbyte/s: 一个接口实现两种功能(USB2.0+FPGA配置): 免固件开发: 完整的FPGA代码,即拿即用: FPGA逻辑工程师开发USB接口福音: 平台可移植 ...
- virtualenv Mac版
环境 MAC python 3.6.7 安装python python官网下载3.6.7版本,默认安装 安装完成后检查是否安装成功: python3.6 确认安装目录:which python3.6 ...
- Redis数据结构之skiplist(续)
本文摘抄于<Redis内部数据结构详解-skiplist> 一.skiplist的由来 skiplist,顾名思义,首先它是一个list.实际上,它是在有序链表的基础上发展起来的. 我们先 ...
- C#实现视频监控客户端onvif协议一
前言 最近做的项目是监控方面的,需要对接各种摄像头,之前的方案是把各个厂家的SDK都集成到系统中,然后让用户进行切换,后来知道了Onvif (自行百度具体概念)这个东西.原来早就有人一统江湖了. on ...
- jQuery AJAX相关方法
接jQuery学习上篇.因为AJAX是相对独立的一块,所以和jQuery的随笔分开记录了.素材同样来自runoob. 先了解下什么是AJAX. AJAX = 异步 JavaScript 和 XML(A ...
- 吻逗死(windows)系统下自动部署脚本(for java spring*)及linux命令行工具
转载请注明出处:https://www.cnblogs.com/funnyzpc/p/10051647.html (^^)(^^)自動部署腳本原本在上個公司就在使用,由於近期同事需要手動部署一個Spr ...
- android studio gradle 打jar 包 (混淆+第三方库包)
将依赖的第三方库打包进自己的jar包 1.先将第三方的库包拿到,然后添加jar包到项目的libs. 2.项目的build.gradle脚本添加下面的task: task buildJar(depend ...