利用Python爬去囧网福利(多线程、urllib、request)
import os;
import urllib.request;
import re;
import threading;# 多线程
from urllib.error import URLError#接收异常's 模块 #获取网站的源码
class QsSpider:
#init 初始化构造函数 .self本身
def __init__(self):
self.user_agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
self.header = {'User-Agent':self.user_agent}
self.url = 'http://www.qiubaichengren.net/%s.html'
self.save_dir = './img'
self.page_num = 20 #page num
#获取网站源代码
def load_html(self,page):
try:
web_path = self.url % page
request = urllib.request.Request(web_path,headers=self.header)
with urllib.request.urlopen(request) as f:
html_content = f.read().decode('gbk')
#print(html_content)
self.pick_pic(html_content)
except URLError as e :
print(e.reason) #异常原因
#download
def sava_pic(self,img):
save_path = self.save_dir + "/" +img.replace(':','@').replace('/','_')
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
print(save_path)
urllib.request.urlretrieve(img,save_path)
#filter
def pick_pic(self,html_content):
patren = re.compile(r'src="(http:.*?\.(?:jpg|png|gif))')
pic_path_list = patren.findall(html_content)
for i in pic_path_list:
#print(i)
self.sava_pic(str(i)) #mamy threading
def start(self):
for i in range(1,self.page_num):
thread = threading.Thread(target=self.load_html,args=str(i))
thread.start() # main void
spider = QsSpider()
spider.start()
一、爬虫流程:

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
二、响应Response
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
三、http协议 请求与响应

Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、结果(福利)
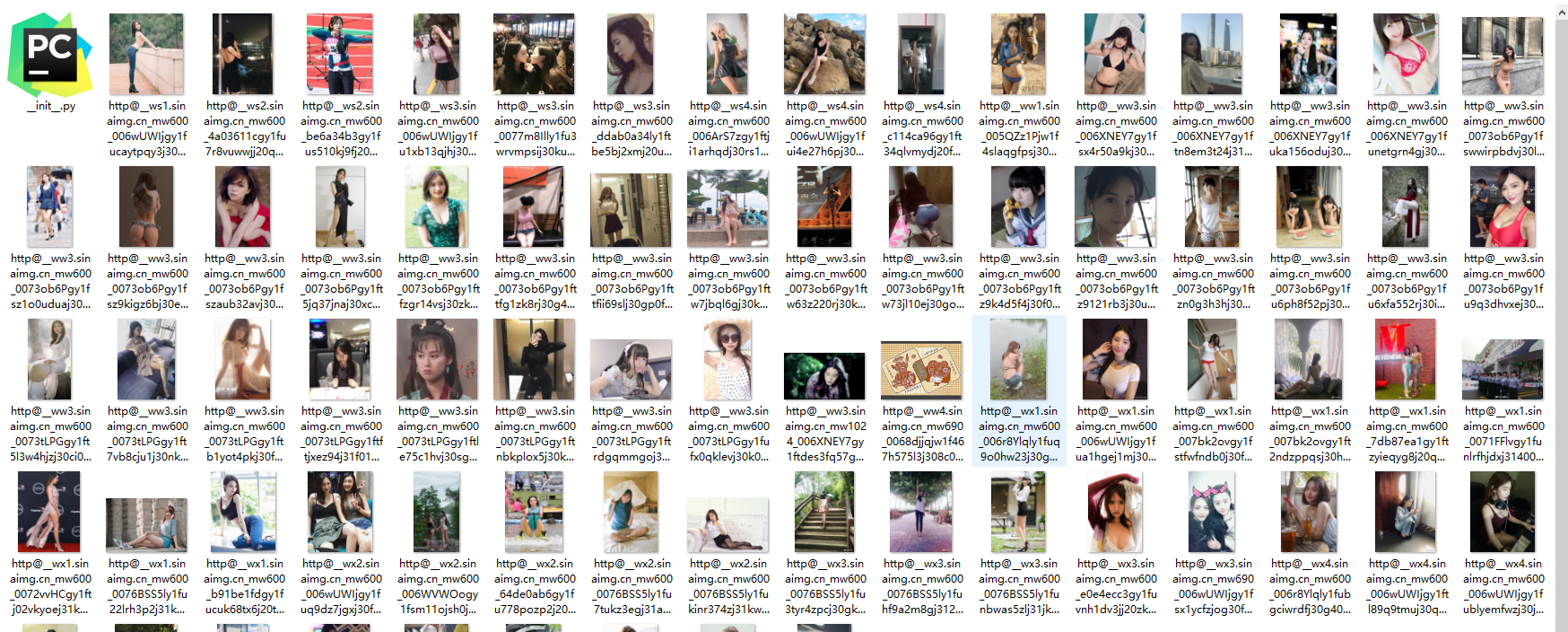
利用Python爬去囧网福利(多线程、urllib、request)的更多相关文章
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- Python学习之路 (五)爬虫(四)正则表示式爬去名言网
爬虫的四个主要步骤 明确目标 (要知道你准备在哪个范围或者网站去搜索) 爬 (将所有的网站的内容全部爬下来) 取 (去掉对我们没用处的数据) 处理数据(按照我们想要的方式存储和使用) 什么是正则表达式 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- python爬去电影天堂恐怖片+游戏
1.爬去方式python+selenium 2.工作流程 selenium自动输入,自动爬取,建立文件夹,存入磁力链接到记事本 3.贴上代码 #!/usr/bin/Python# -*- coding ...
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
随机推荐
- Jmeter中基本操作
Jmeter中基本操作包括 1:线程组 2:HTTP信息头管理器 3:HTTP请求默认值 4:HTTP请求 5:查看结果树 操作步骤如下: 1.创建一个线程组 通俗的讲一个线程组,,可以看做一个虚拟用 ...
- mybatis常用类起别名
在mybatis的配置文件中添加如下配置 <settings> <setting name="cacheEnabled" value="true&quo ...
- C语言第零次作业
Q1.你对网络专业或者计算机专业了解是怎样? 说实话不了解网络专业,在甚至在填志愿之前我都不曾听说过.但经过一番的查阅资料.现在,首先我了解到我们主要学习计算机.通信以及网络方面的基础理论.设计原理, ...
- tp5 mkdir(): Permission denied 问题
今天使用tp5 线上上传图片的时候遇到了一个问题 mkdir(): Permission denied 如图 百度了一下 发现大家都说 chmod -R 777 runtime 能解决问题 尝试了一下 ...
- [转]webpack中require和import的区别
webpack中可以写commonjs格式的require同步语法,可以写AMD格式的require回调语法,还有一个require.ensure,以及webpack自己定义的require.incl ...
- 推荐vim学习教程--《Vim 练级手册》
非常不错的vim学习资源,讲解的简单明了,可以作为速查工具,在忘记时就翻下.地址如下: <Vim 练级手册>
- 关于各种工具输入参数中"-"和"--"
关于各种工具输入参数中"-"和"--" 写个随笔记录下来 一直搞不懂,为啥在使用很多工具的时候,他的参数要加的"-"数量不一样呢? 如果输入 ...
- 微信跳转ticket值怎么得到?浏览器跳到微信?哪里有微信跳转接口?跳转功能能用多久?
目前很多实用微信跳转技术的电商朋友,网站文章头部或者文章中部出现了点击关注微信关注的二维码,用户点击进去直接跳转到微信内打开指定的二维码,识别即可关注,方便省事,比以往的一键复制—粘贴微信号,转化效果 ...
- RaspberryPi上建立wordpress
准备工作: 1.RaspberryPi 3代 B型 2.可用内存卡 3.读卡器 4.DiskGenius 5.Win32 Disk Imager 6.可用局域网 7.Xshell 和 Xftp 8.官 ...
- lua语言自学知识点----简单了解
零碎知识点: lua:用lua写UI,更新UI,因为lua可直接跨平台解析,不需要编译,方便更新------>热更新. c#反射也可以达到更新,但非常麻烦,切不支持iOS. 在lua中一个人汉字 ...