Flink学习(九) Sink到Kafka
package com.wyh.streamingApi.sink import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011} //温度传感器读数样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double) object Sink2Kafka {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) /**
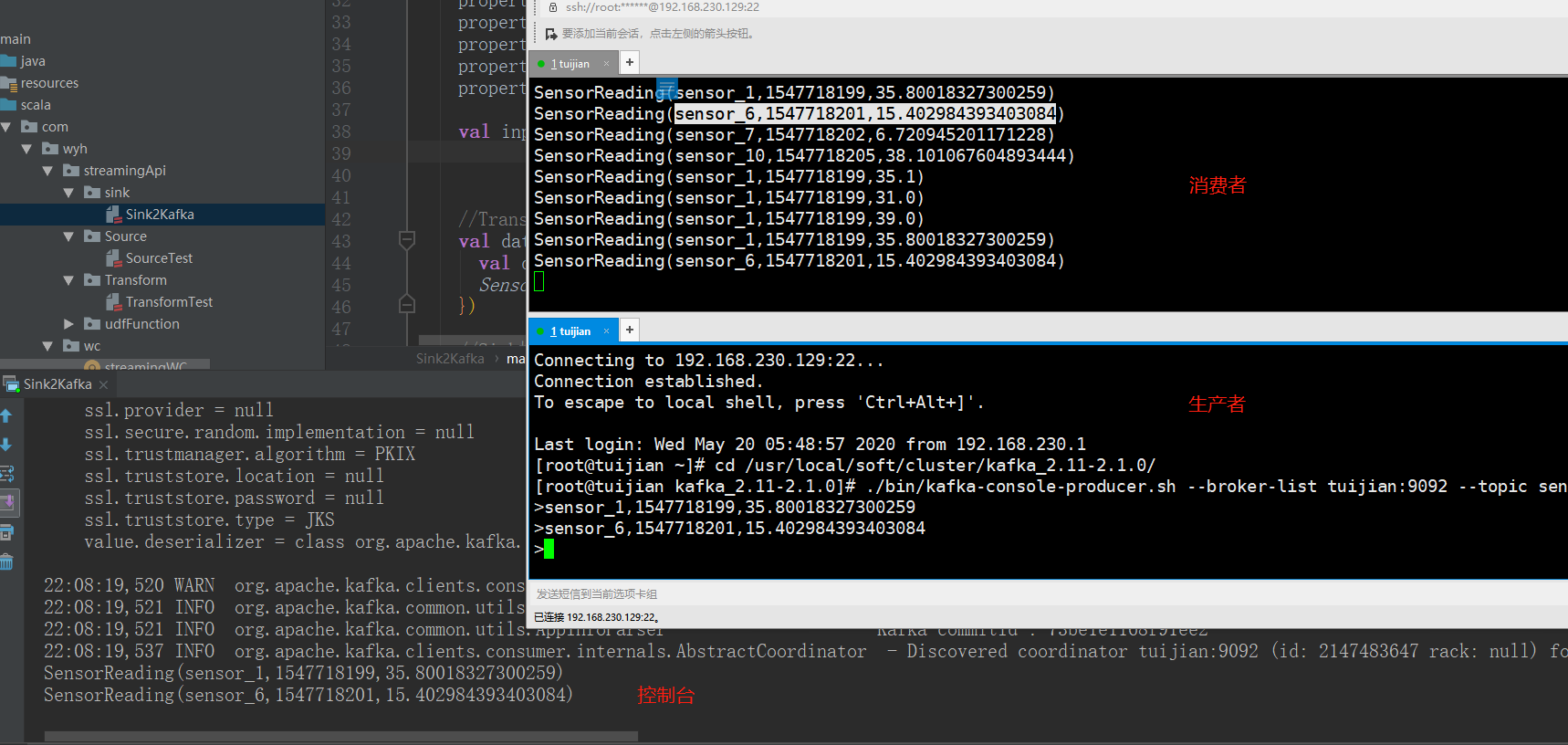
* sensor_1,1547718199,35.80018327300259
* sensor_6,1547718201,15.402984393403084
* sensor_7,1547718202,6.720945201171228
* sensor_10,1547718205,38.1010676048934444
* sensor_1,1547718199,35.1
* sensor_1,1547718199,31.0
* sensor_1,1547718199,39
*/
//Source操作
// val inputStream = env.readTextFile("F:\\flink-study\\wyhFlinkSD\\data\\sensor.txt") val properties = new Properties()
properties.setProperty("zookeeper.connect", "tuijian:2181")
properties.setProperty("bootstrap.servers", "tuijian:9092")
properties.setProperty("group.id", "test-consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest") //偏移量自动重置 val inputStream = env.addSource(new FlinkKafkaConsumer011[String]("sensor",new SimpleStringSchema(),properties)) //Transform操作
val dataStream: DataStream[String] = inputStream.map(data => {
val dataArray = data.split(",")
SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble).toString //转成String方便序列化输出
}) //Sink操作
dataStream.addSink(new FlinkKafkaProducer011[String]("tuijian:9092","sinkTest",new SimpleStringSchema())) dataStream.print()
env.execute("kafka sink test") } }
Flink学习(九) Sink到Kafka的更多相关文章
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 《从0到1学习Flink》—— Data Sink 介绍
前言 再上一篇文章中 <从0到1学习Flink>-- Data Source 介绍 讲解了 Flink Data Source ,那么这里就来讲讲 Flink Data Sink 吧. 首 ...
- flink学习总结
flink学习总结 1.Flink是什么? Apache Flink 是一个框架和分布式处理引擎,用于处理无界和有界数据流的状态计算. 2.为什么选择Flink? 1.流数据更加真实的反映了我们的生活 ...
- Flink 之 Data Sink
首先 Sink 的中文释义为: 下沉; 下陷; 沉没; 使下沉; 使沉没; 倒下; 坐下; 所以,对应 Data sink 意思有点把数据存储下来(落库)的意思: Source 数据源 ---- ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- 准备数据集用于flink学习
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink学习笔记:Connectors之kafka
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- 【javaweb】【Session】记录用户访问时间
效果 Servlet import jakarta.servlet.*; import jakarta.servlet.http.*; import jakarta.servlet.annotatio ...
- Web前端常见的英文缩写
PV (Page View)页面浏览量 FED(Front-End Development)前端开发 F2E(Front-End Engineer)前端工程师 WWW(World Wide Web)万 ...
- Qt/C++编写视频监控系统82-自定义音柱显示
一.前言 通过音柱控件实时展示当前播放的声音产生的振幅的大小,得益于音频播放组件内置了音频振幅的计算,可以动态开启和关闭,开启后会对发送过来的要播放的声音数据,进行运算得到当前这个音频数据的振幅,类似 ...
- Qt开源作品33-图片开关控件
一.前言 进入智能手机时代以来,各种各样的APP大行其道,手机上面的APP有很多流行的元素,开关按钮个人非常喜欢,手机QQ.360卫士.金山毒霸等,都有很多开关控制一些操作,在WINFORM项目上,如 ...
- Uniapp 获取当前版本号
plus.runtime.getProperty(plus.runtime.appid, function(wgtinfo) { oldversion = wgtinfo.versionCode // ...
- 查询 maven 依赖 的最新版本号
如何通过maven官网查询相关依赖的具体代码和版本? 通过官网:http://mvnrepository.com/,或者:https://search.maven.org/ 在搜索栏中输入想要引入的依 ...
- TNN-linux编译测试记录
Github: https://github.com/Tencent/TNN docs: https://github.com/Tencent/TNN/blob/master/doc/cn/user/ ...
- 【狂神说Java】Java零基础学习笔记-Java方法
[狂神说Java]Java零基础学习笔记-Java方法 Java方法01:何谓方法? System.out.println(),那么它是什么呢? Java方法是语句的集合,它们在一起执行一个功能. 方 ...
- RocksDB-键值存储
存储和访问数百PB的数据是一个非常大的挑战,开源的RocksDB就是FaceBook开放的一种嵌入式.持久化存储.KV型且非常适用于fast storage的存储引擎. 传统的数据访问都是RPC, ...
- 面向对象-下(复习:关键字static、单例模式、main()的使用说明、类的结构代码块、属性的赋值顺序、关键字final)
一.关键字:static static:静态的1.可以用来修饰的结构:主要用来修饰类的内部结构属性.方法.代码块.内部类2.static修饰属性:静态变量(或类变量) 2.1 属性,是否使用stati ...