python-2:爬取某个网页(虎扑)帖子的标题做词云图
关键词:requests,BeautifulSoup,jieba,wordcloud
整体思路:通过requests请求获得html,然后BeautifulSoup解析html获得一些关键数据,之后通过jieba分词对数据进行切分,去停,最后通过wordcloud画词云图
1、请求虎扑Acg区
Acg区首页的url为:https://bbs.hupu.com/acg
Acg区第二页的url为:https://bbs.hupu.com/acg-2
从这里可以得知,如果我们要请求多个网页,只需要以首页作为基础url,后面的每一页在首页的url基础上进行添加即可。引入requests库进行请求
base_url = r'https://bbs.hupu.com/acg'
add_url = ''
content_str = ''
# 尝试请求15个网页
for i in range(1, 15):
if i != 1:
add_url = r'-{}'.format(i)
else:
add_url = ''
url = base_url + add_url
response = requests.get(url)
2、BeautifulSoup解析
打开浏览器的控制台,观察网页源码,寻找需要获得的数据的标签。我们需要获取一个帖子的标题,通过浏览网页源码可以发现帖子的标题在一个<a></a>标签中,且class=“truetit”,通过这两个信息我们就可以通过BeautifulSoup获取一个帖子的标题了。
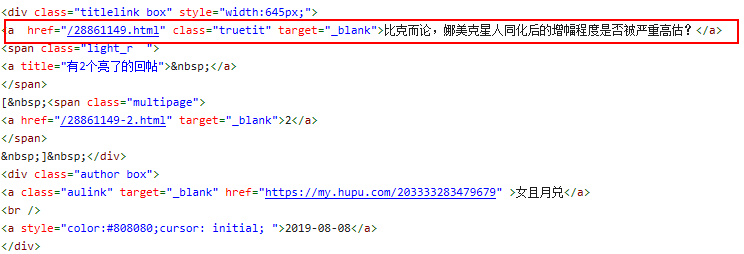
base_url = r'https://bbs.hupu.com/acg'
add_url = ''
content_str = ''
for i in range(1, 15):
if i != 1:
add_url = r'-{}'.format(i)
else:
add_url = ''
url = base_url + add_url
response = requests.get(url)
# 引入BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
# 找<a></a>标签,class = ‘truetit’
all_title = soup.find_all("a", class_="truetit")
for title in all_title:
content_str += title.text
需要注意的是,
all_title = soup.find_all("a", class_="truetit")
会把当前网页的所有标题都读出来,且格式是一个以<a></a>标签为元素的list,通过for遍历这个list,对每一个<a></a>,调用title.text即可以获得帖子的标题。
print一下,查看是不是获得了想要的结果:

可以看到我们已经获得了我们想要的标题,下一步就是数据处理了(jieba分词+去停)
3、jieba分词+去停用词
先写一个生成停用词表的函数
# 引入停用词表
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
再进行jieba分词,去停使用的是哈工大停用词表
# 用lcut使得分词后为一个list
s_list = jieba.lcut(content_str)
out_list = []
# 引入停用词表
stopwords = stopwordslist(r'E:\stopwords-master\哈工大停用词表.txt')
for word in s_list:
if word not in stopwords:
if word != '\t':
out_list.append(word)
out_str = " ".join(out_list)
到这一步,就可以获得分词后的关键词了。下一步就是画词云图了。
4、画词云图
引入wordcloud,font_path是字体的路径,不导入的话可能只会显示一些框框,具体文字下载可以去网上找。mask是背景图片。generate()里的是string类型的数据。
alice_mask = plt.imread(r'D:\壁纸\huge.jpg')
# generate的是string类型的
word_cloud = WordCloud(font_path='msyh.ttc',mask=alice_mask,background_color='white', max_words=400, max_font_size=80).generate(out_str)
plt.figure(figsize=(15,9))
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis('off')
plt.show()
5、结果展示
不引入mask参数:

引入mask参数:

今天是8月8号,最近正好是巨人最新一话发布的时候,所以巨人的讨论度很高。同时一直支撑着虎扑acg区热度的海贼王讨论度也很高,其次的关键词还有 动画,动漫,龙珠,艾伦,漫画,情报等等。
6、需要改进的地方
(1)无关紧要的词太多了,需要自写停用词表进行去停。如最后结果中的“是不是”,“觉得”等,这些词都应该去掉
(2)引入mask的情况下,很多背景图使用了最后却没有展示出来。有的背景图可以,有的却不可以。
最后,感谢观看这篇博客。其中借鉴了许多网上的内容,感谢一些原作者的努力。
python-2:爬取某个网页(虎扑)帖子的标题做词云图的更多相关文章
- 一、python简单爬取静态网页
一.简单爬虫框架 简单爬虫框架由四个部分组成:URL管理器.网页下载器.网页解析器.调度器,还有应用这一部分,应用主要是NLP配合相关业务. 它的基本逻辑是这样的:给定一个要访问的URL,获取这个ht ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- 用python简单爬取一个网页
1打开编辑器 2撸几行代码 import urllib.request import urllib.error def main(): askURl("http://movie.douban ...
- Python爬虫:爬取自己博客的主页的标题,链接,和发布时间
代码 # -*- coding: utf-8 -*- """ ------------------------------------------------- File ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
随机推荐
- 哈密尔顿环x
欧拉回路是指不重复地走过所有路径的回路,而哈密尔顿环是指不重复地走过所有的点,并且最后还能回到起点的回路. 代码如下: #include<iostream> #include<cs ...
- 15.Python bool布尔类型
Python 提供了 bool 类型来表示真(对)或假(错),比如常见的5 > 3比较算式,这个是正确的,在程序世界里称之为真(对),Python 使用 True 来代表:再比如4 > 2 ...
- Apicloud_(接口验证)用户注册头部信息X-APICloud-AppKey生成
接口验证KEY生成规则说明 官方文档: 传送门 "X-APICloud-AppKey"生成规则是基于SHA1()算法生成的 AppKey= SHA1(你的应用ID + 'UZ' + ...
- 原生Js_使用setInterval() 方法实现图片轮播功能
用javascript图片轮播功能 <!DOCTYPE html> <html> <head> <meta charset="utf-8" ...
- 为什么要使用 Go 语言,Go 语言的优势在哪里?
1.Go有什么优势 可直接编译成机器码,不依赖其他库,glibc的版本有一定要求,部署就是扔一个文件上去就完成了. 静态类型语言,但是有动态语言的感觉,静态类型的语言就是可以在编译的时候检查出来隐藏的 ...
- 把execel表数据导入mysql数据库
今天,是我来公司第二周的第一天. 作为新入职的实习生,目前还没适合我的实质项目工作,今天的学习任务是: 把execel表数据导入到mysql数据库,再练习下java操作JDBC. 先了解下execel ...
- C++入门经典-例3.13-不加break的switch判断语句
1:不加break,会依次运行下面的语句,代码如下: // 3.13.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include &l ...
- 20175212童皓桢 实验四 Android程序设计
20175212童皓桢 实验四 Android程序设计 实验内容 参考<Java和Android开发学习指南(第二版)(EPUBIT,Java for Android 2nd)>并完成相关 ...
- nodejs 配置服务器
node 是 js 的运行的后台环境,他自身集成了很多模块,集成的模块直接 require 就行了: npm 第三方平台,他也是为 node 服务的,对于 npm 中的模块,先 npm install ...
- laravel 使用不同账号发送邮件的问题
业务背景: 公司自己做的oa系统,不同的模块需要用不同的邮箱发送信息给收件人.比如:员工离职的时候用离职的邮箱发送离职邮件通知,员工入职的时候用入职的邮箱发送入职邮件通知.发邮件是一件耗时的任务,如果 ...