一、python简单爬取静态网页
一、简单爬虫框架
简单爬虫框架由四个部分组成:URL管理器、网页下载器、网页解析器、调度器,还有应用这一部分,应用主要是NLP配合相关业务。
它的基本逻辑是这样的:给定一个要访问的URL,获取这个html及内容(也可以获取head和cookie等其它信息),获取html中的某一类链接,如a标签的href属性。从这些链接中继续访问相应的html页面,然后获取这些html的固定标签的内容,并把这些内容保存下来。
一些前提:;所有要爬取的页面,它们的标签格式都是相同的,可以写一个网页解析器去获取相应的内容;给定的URL(要访问的资源)所获得的html,它包含的标签链接是可以筛选的,筛选后的标签链接(新的URL)会被继续请求其html文档。调度器是一个循环体,循环处理这些URL、请求以及html、网页解析。
1.运行流程
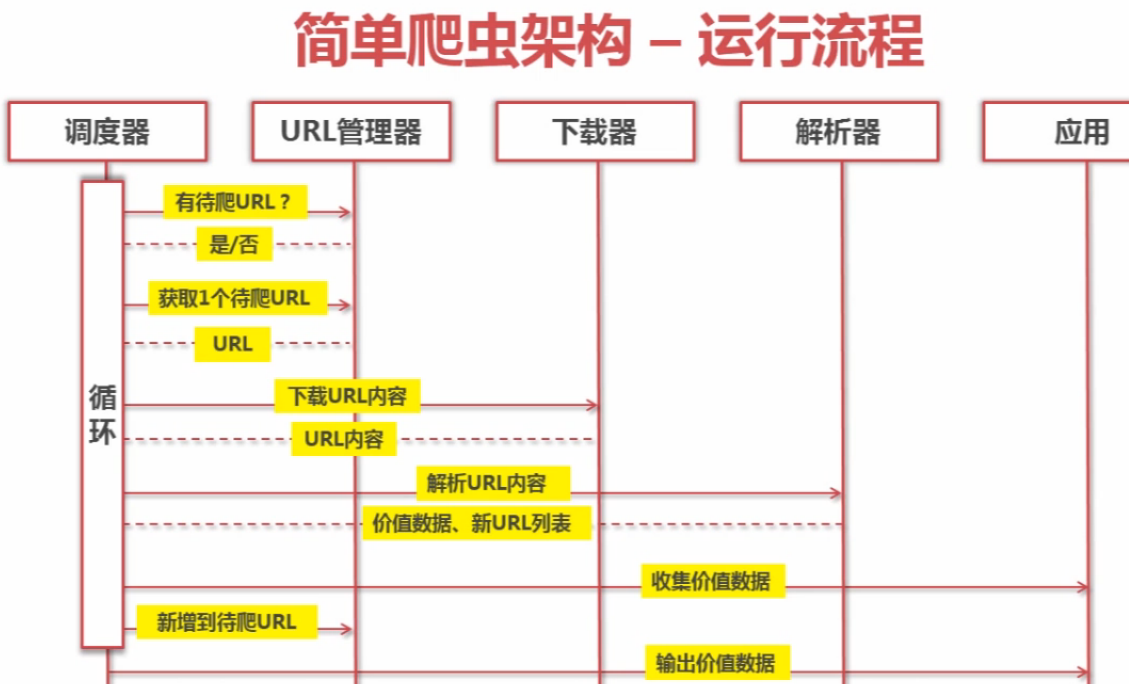
调度器是一个主循环体,负责不断重复执行URL管理器、下载器、解析器。URL是管理新的URL的添加、旧的URL的去除,以及URL的去重和记录。下载器顾名思义,就是根据URL,发送http请求,获取utf-8编码的字节流的html文件数据。解析器负责将html还原成DOM对象,并提供一套类似js的DOM操作的方法,从html中获取节点、属性、文本、甚至是样式等内容。
2.URL管理器
URL管理器有两个功能,获取待添加的URL--判断它是否在已被读取的URL集合里--[No]判断它是否在待读取的URL集合里--[No]添加到待读取的URL集合里。否则就直接抛弃。
URL管理器一般放在内存、关系型数据库和缓存数据库里。python里可以使用set()集合去重。
3.网页下载器
向给定的URL发送请求,获取html。python的两个模块。内置urllib模块和第三方模块request。python3将urllib2封装成了urllib.request模块。
# 网页下载器代码示例
import urllib url = "http://www.baidu.com" print("第一种方法: 直接访问url")
response1 = urllib.request.urlopen(url)
print(response1.getcode()) # 状态码
print(len(response1.read())) # read读取utf-8编码的字节流数据 print("第二种方法: 设置请求头,访问Url")
request = urllib.request.Request(url) # 请求地址
request.add_header("user-agent", "mozilla/5.0") # 修改请求头
response2 = urllib.request.urlopen(request)
print(response2.getcode())
print(len(response2.read())) import http.cookiejar # 不知道这是啥 print("第三种方法: 设置coockie,返回的cookie")
# 第三种方法的目的是为了获取浏览器的cookie内容
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print(response3.getcode())
print(len(response3.read()))
print(cj) # 查看cookie的内容
4.网页解析器
将utf-8编码的字节码重新重新解析为html。因为数据传输是字节数据,所以网页下载器下载的内容需要重新解析。
提供DOM对象[html文档解构]的操作方法。和js类似。包括节点、标签元素、属性[包括name、class、style、value等等]、样式、内容等的操作。从而能够获取特定的内容。
python的BeautifulSoup模块(bs4)。以下代码可直接在bs4模块官方文档中获取和运行。
from bs4 import BeautifulSoup
from re import compile
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, "html.parser")
print(soup.prettify())
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
print(soup.a)
print(soup.find_all(href=compile(r"/example.com/\S*")))
print(soup.find_all('a'))
print(soup.find(id="link3"))
print(soup.get_text())
print(soup.find("p", attrs={"class": "story"}).get_text()) for link in soup.find_all('a'):
print(link.get('href'))
二、简单示例
爬取百度百科上词条为python的以href='/tem/'开头的所有相关网页的词条简介。
from re import compile
from html.parser import HTMLParser
from bs4 import # url管理器
class UrlManager(object):
"""
url管理器主要有三个功能:add_new_url添加新的待爬取的页面;get_new_url删除已爬取的页面;标记待爬取的和已爬取的页面。
"""
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
# 如果传入的url既不在待爬取的url里又不在爬过的url里,说明它是待爬取的url
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url) def has_new_url(self):
return len(self.new_urls) != 0 def get_new_url(self):
new_url = self.new_urls.pop() # 从待爬去的url中剔除要爬取的目标
self.old_urls.add(new_url) # 添加到
return new_url # 简单的下载器
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read() # 解析器
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
# 这里要提一下,百度百科python词汇的url是https://baike.baidu.com/item/Python/407313
# 页面中的a标签的href属性都类似href="/item/%E6%95%99%E5%AD%A6"这种属性
# 在处理时,需要加上baike.baidu.com保证url资源定位符的完整性。后面只需匹配"/item/"
new_urls = set()
links = soup.find_all('a', href=compile(r"/item/\S*"))
for link in links:
new_url = link["href"]
new_full_url = urllib.parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls def _get_new_data(self, page_url, soup):
res_data = {}
res_data["url"] = page_url
# 爬取标题
# <dd class="lemmaWgt-lemmaTitle-title"></dd><h1>Python</h1>
title_node = soup.find("dd", attrs={"class": "lemmaWgt-lemmaTitle-title"}).find("h1")
res_data["title"] = title_node.get_text()
# 爬取简介内容
# <div class="lemma-summary" label-module="lemmaSummary"></div>
# 这个div下的所有div里的text
summary_node = soup.find('div', attrs={"class": "lemma-summary", "label-module":"lemmaSummary"})
res_data["summary"] = summary_node.get_text()
return res_data def parse(self, page_url, html_doc):
if page_url is None or html_doc is None:
return
# 解析成了一个整个的DOM对象,也就是纯html格式的文件
soup = BeautifulSoup(html_doc, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
# print("page_url: %r, new_urls: %r, new_data: %r" % (page_url, new_urls, new_data))
return new_urls, new_data # 输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open("output.html", 'w', encoding="UTF-8")
fout.write("<html>")
fout.write("<meta http-equiv='content-type' content='text/html;charset=utf-8'>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" %data['url'])
fout.write("<td>%s</td>" %data['title'])
fout.write("<td>%s</td>" %data['summary'])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>") class SpiderMain(object):
def __init__(self):
self.urls = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.outputer = HtmlOutputer() def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
html_cont = self.downloader.download(new_url)
# print("\033[1;36m %r \033[0m" % html_cont.decode("utf-8"))
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 11:break
print("\033[1;36m [CRAW]\033[0m : %d %r" %(count, new_url))
count += 1
except Exception as e:
print("craw failed")
print(e)
self.outputer.output_html()
运行结果如下:
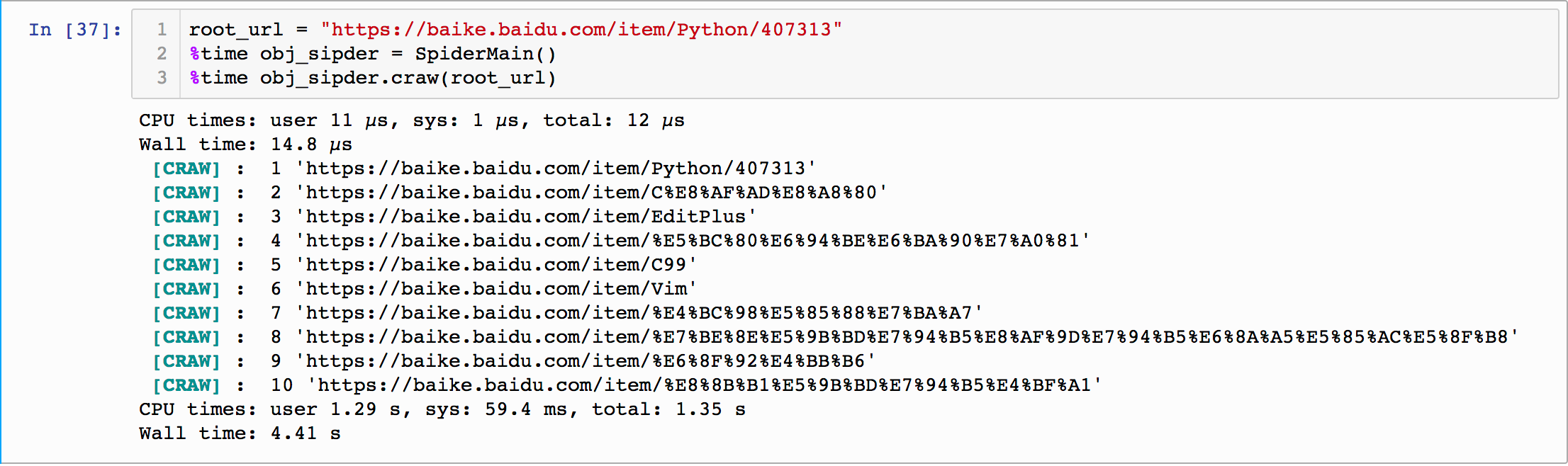
打开保存的out.html,内容如下:

一、python简单爬取静态网页的更多相关文章
- 用python简单爬取一个网页
1打开编辑器 2撸几行代码 import urllib.request import urllib.error def main(): askURl("http://movie.douban ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- Python简单爬取图书信息及入库
课堂上老师布置了一个作业,如下图所示: 就是简单写一个借书系统. 大概想了一下流程,登录-->验证登录信息-->登录成功跳转借书界面-->可查看自己的借阅书籍以及数量... 登录可以 ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
随机推荐
- java内存模型(jMM)(一)
在说java的内存模型之前先简单的了解计算机的主存和缓存的相关概念. 多任务和高并发是衡量一台计算机处理器的重要指标.一般衡量一个服务器性能的高低好坏,使用每秒事务处理数(Transactions P ...
- Java - 多线程与锁
进程-线程 进程,Process,处于运行中的程序,系统进行资源分配和调度的独立单位,拥有独立的内存空间(堆). 动态性:生命周期和状态: 独立性:独立实体: 并发性:Concurrency,抢占式多 ...
- Gsteramer 环境配置
安装命令: sudo add-apt-repository universe sudo add-apt-repository multiverse sudo apt-get update sudo a ...
- Boost内存池使用与测试
目录 Boost内存池使用与测试 什么是内存池 内存池的应用场景 安装 内存池的特征 无内存泄露 申请的内存数组没有被填充 任何数组内存块的位置都和使用operator new[]分配的内存块位置一致 ...
- Jmeter将JDBC Request查询结果作为下一个接口参数方法(转载)
现在有一个需求,从数据库tieba_info表查出rank小于某个值的username和count(*),然后把所有查出来的username和count(*)作为参数值,用于下一个接口. tieba_ ...
- 01-复杂度2 Maximum Subsequence Sum (25 分)
Given a sequence of K integers { N1, N2, ..., NK }. A continuous subsequence is defined to ...
- python 继承与组合
一.组合 #老师 课程 生日 class Course: def __init__(self,name,period,price): self.name = name self.period = pe ...
- c# 线程,同步,锁
最近在阅读<c#高级编程> 这本书.记录一下关于锁的使用 大致分为三种方法: 方法1:使用 lock 方法2:使用 Interlocked 方法3:使用 Monitor using Sys ...
- 2019.04.19 读书笔记 比较File.OpenRead()和File.ReadAllBytes()的差异
最近涉及到流的获取与转化,终于要还流的债了. 百度了一下,看到这样的两条回复,于是好奇心,决定看看两种写法的源码差异. 先来看看OpenRead() public static FileStream ...
- Jquery ajax, Axios, Fetch区别
1. Jquery ajax, Axios, Fetch区别之我见 2. ajax.axios.fetch之间的详细区别以及优缺点