NebulaGraph实战:3-信息抽取构建知识图谱
自动信息抽取发展了几十年,虽然模型很多,但是泛化能力很难用满意来形容,直到LLM的诞生。虽然最终信息抽取质量部分还是需要专家审核,但是已经极大的提高了信息抽取的效率。因为传统方法需要大量时间来完成数据清洗、标注和训练,然后来实体抽取、实体属性抽取、实体关系抽取、事件抽取、实体链接和指代消解等等。现在有了LLM,可以实现Zero/One/Few-Shot信息抽取构建知识图谱。
一.ChatIE实现过程
ChatIE本质上是将零样本IE任务转变为一个两阶段框架的多轮问答问题(使用的ChatGPT,也可以修改为ChatGLM2),问题是第一阶段和第二阶段如何设计?本质上还是Prompt的设计。接下来都是以RE(关系抽取)为例进行说明,NER(命名实体识别)和EE(事件抽取)以此类推。下面看一个例子,如下所示:
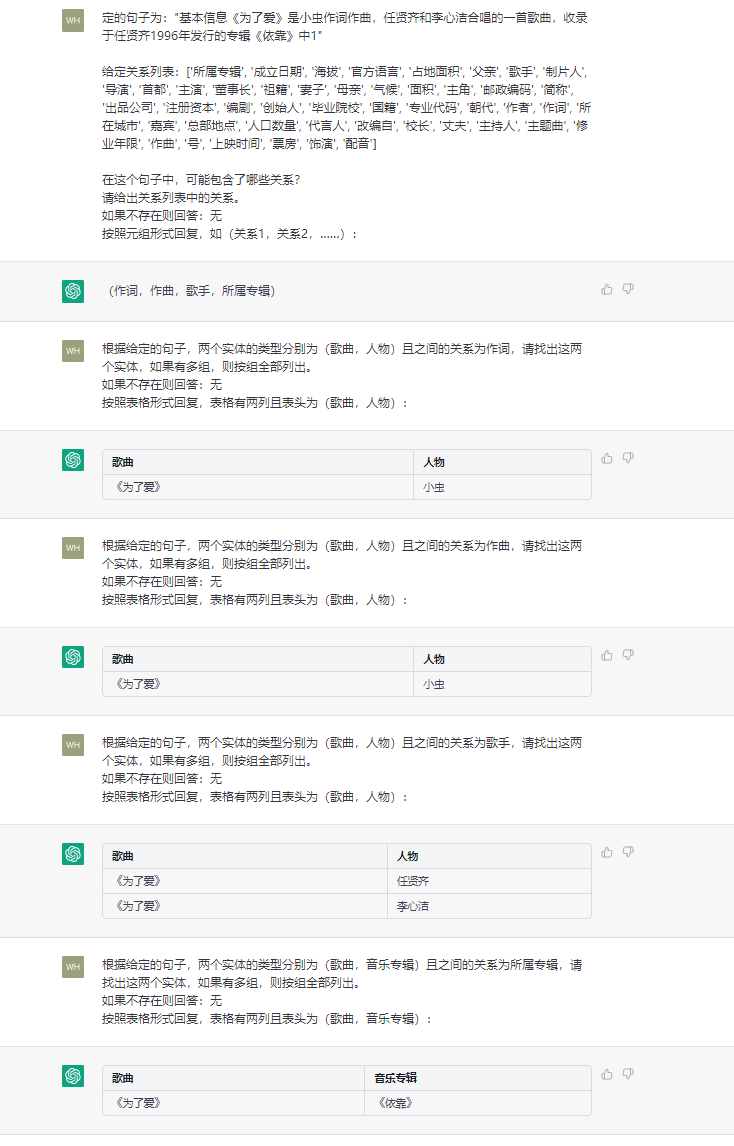
df_ret = {
'chinese': {'所属专辑': ['歌曲', '音乐专辑'], '成立日期': ['机构', 'Date'], '海拔': ['地点', 'Number'], '官方语言': ['国家', '语言'], '占地面积': ['机构', 'Number'], '父亲': ['人物', '人物'],
'歌手': ['歌曲', '人物'], '制片人': ['影视作品', '人物'], '导演': ['影视作品', '人物'], '首都': ['国家', '城市'], '主演': ['影视作品', '人物'], '董事长': ['企业', '人物'], '祖籍': ['人物', '地点'],
'妻子': ['人物', '人物'], '母亲': ['人物', '人物'], '气候': ['行政区', '气候'], '面积': ['行政区', 'Number'], '主角': ['文学作品', '人物'], '邮政编码': ['行政区', 'Text'], '简称': ['机构', 'Text'],
'出品公司': ['影视作品', '企业'], '注册资本': ['企业', 'Number'], '编剧': ['影视作品', '人物'], '创始人': ['企业', '人物'], '毕业院校': ['人物', '学校'], '国籍': ['人物', '国家'],
'专业代码': ['学科专业', 'Text'], '朝代': ['历史人物', 'Text'], '作者': ['图书作品', '人物'], '作词': ['歌曲', '人物'], '所在城市': ['景点', '城市'], '嘉宾': ['电视综艺', '人物'], '总部地点': ['企业', '地点'],
'人口数量': ['行政区', 'Number'], '代言人': ['企业/品牌', '人物'], '改编自': ['影视作品', '作品'], '校长': ['学校', '人物'], '丈夫': ['人物', '人物'], '主持人': ['电视综艺', '人物'], '主题曲': ['影视作品', '歌曲'],
'修业年限': ['学科专业', 'Number'], '作曲': ['歌曲', '人物'], '号': ['历史人物', 'Text'], '上映时间': ['影视作品', 'Date'], '票房': ['影视作品', 'Number'], '饰演': ['娱乐人物', '人物'], '配音': ['娱乐人物', '人物'], '获奖': ['娱乐人物', '奖项']
}
}
1.第一阶段
第一阶段的模板,如下所示:
re_s1_p = {
'chinese': '''给定的句子为:"{}"\n\n给定关系列表:{}\n\n在这个句子中,可能包含了哪些关系?\n请给出关系列表中的关系。\n如果不存在则回答:无\n按照元组形式回复,如 (关系1, 关系2, ……):''',
}
2.第二阶段
第二段的模板,如下所示:
re_s2_p = {
'chinese': '''根据给定的句子,两个实体的类型分别为({},{})且之间的关系为{},请找出这两个实体,如果有多组,则按组全部列出。\n如果不存在则回答:无\n按照表格形式回复,表格有两列且表头为({},{}):''',
}
ChatIE通过两阶段的ChatGPT多轮问答来解决Zero-Shot信息抽取构建知识图谱。但有个问题是可能或一定会出现错误关系抽取,这该如何办呢?工程有个解决方案就是引入多个裁判,比如ChatGPT是一个裁判,文心一言是一个裁判,BERT实体关系抽取是一个裁判,规则实体关系抽取是一个裁判。可根据知识精度要求,比如4个裁判都一致了,才会自动更新到知识库中,否则需要人工来审核实体关系抽取是否正确。知识图谱自动化更新是一个工程活,需要一个人工审核的功能,来确保模型识别不一致时的最终审核。
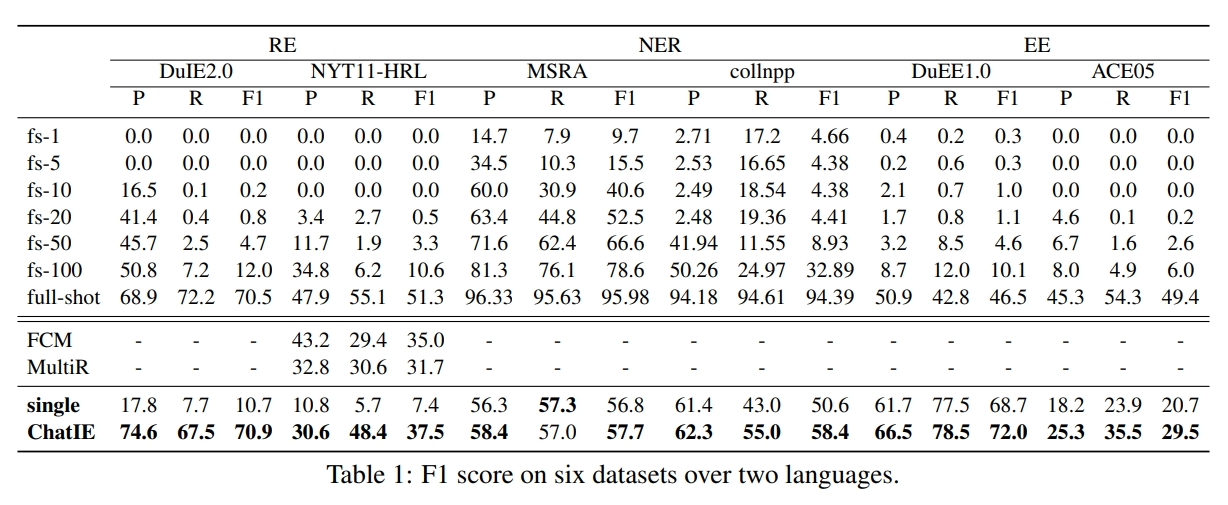
3.测试效果
ChatIE在不同任务(RE、NER和EE)和不同数据集上的测试效果,如下所示:
二.使用ChatGLM2来信息抽取[1]
这部分替换ChatGPT为ChatGLM2来做多轮问答。ChatGLM2进行金融知识抽取实践中,在ChatGLM前置了两轮对话达到了较好的效果,具体代码实现参考[9]。基本思路是加载ChatGLM2模型,然后初始化Prompt(分类和信息抽取),最后根据输入和模型完成推理过程。简单理解,整体思路是通过Few-Shot信息抽取构建知识图谱。
(1)加载ChatGLM2模型
tokenizer = AutoTokenizer.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True) # 指定使用的tokenizer
model = AutoModel.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True).half().cuda() # 指定使用的model
model = model.eval() # 指定model为eval模式
(2)初始化Prompt
def init_prompts():
"""
初始化前置prompt,便于模型做 incontext learning。
"""
class_list = list(class_examples.keys()) # 获取分类的类别,class_list = ['基金', '股票']
cls_pre_history = [
(
f'现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。',
f'好的。'
)
]
for _type, exmpale in class_examples.items(): # 遍历分类的类别和例子
cls_pre_history.append((f'“{exmpale}”是 {class_list} 里的什么类别?', _type)) # 拼接前置prompt
ie_pre_history = [
(
"现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中三元组,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'好的,请输入您的句子。'
)
]
for _type, example_list in ie_examples.items(): # 遍历分类的类别和例子
for example in example_list: # 遍历例子
sentence = example['content'] # 获取句子
properties_str = ', '.join(schema[_type]) # 拼接schema
schema_str_list = f'“{_type}”({properties_str})' # 拼接schema
sentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置prompt
ie_pre_history.append(( # 拼接前置prompt
f'{sentence_with_prompt}',
f"{json.dumps(example['answers'], ensure_ascii=False)}"
))
return {'ie_pre_history': ie_pre_history, 'cls_pre_history': cls_pre_history} # 返回前置prompt
custom_settings数据结构中的内容如下所示:

(3)根据输入和模型完成推理过程
def inference(
sentences: list,
custom_settings: dict
):
"""
推理函数。
Args:
sentences (List[str]): 待抽取的句子。
custom_settings (dict): 初始设定,包含人为给定的few-shot example。
"""
for sentence in sentences: # 遍历句子
with console.status("[bold bright_green] Model Inference..."): # 显示推理中
sentence_with_cls_prompt = CLS_PATTERN.format(sentence) # 拼接前置prompt
cls_res, _ = model.chat(tokenizer, sentence_with_cls_prompt, history=custom_settings['cls_pre_history']) # 推理
if cls_res not in schema: # 如果推理结果不在schema中,报错并退出
print(f'The type model inferenced {cls_res} which is not in schema dict, exited.')
exit()
properties_str = ', '.join(schema[cls_res]) # 拼接schema
schema_str_list = f'“{cls_res}”({properties_str})' # 拼接schema
sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置prompt
ie_res, _ = model.chat(tokenizer, sentence_with_ie_prompt, history=custom_settings['ie_pre_history']) # 推理
ie_res = clean_response(ie_res) # 后处理
print(f'>>> [bold bright_red]sentence: {sentence}') # 打印句子
print(f'>>> [bold bright_green]inference answer: ') # 打印推理结果
print(ie_res) # 打印推理结果
如果实体关系抽取搞定了,那么自动更新到NebulaGraph就比较简单了,可参考NebulaGraph实战:2-NebulaGraph手工和Python操作。
参考文献:
[1]利用ChatGLM构建知识图谱:https://discuss.nebula-graph.com.cn/t/topic/13029
[2]ChatGPT+SmartKG 3分钟生成"哈利波特"知识图谱:https://www.msn.cn/zh-cn/news/technology/chatgpt-smartkg-3分钟生成-哈利波特-知识图谱/ar-AA17ykNr
[3]ChatIE:https://github.com/cocacola-lab/ChatIE
[4]ChatIE:http://124.221.16.143:5000/
[5]financial_chatglm_KG:https://github.com/zhuojianc/financial_chatglm_KG
[6]Creating a Knowledge Graph From Video Transcripts With ChatGPT 4:https://neo4j.com/developer-blog/chatgpt-4-knowledge-graph-from-video-transcripts/
[7]GPT4IE:https://github.com/cocacola-lab/GPT4IE
[8]GPT4IE:http://124.221.16.143:8080/
[9]https://github.com/ai408/nlp-engineering/blob/main/20230917_NLP工程化公众号文章\NebulaGraph教程\NebulaGraph实战:3-信息抽取构建知识图谱
NebulaGraph实战:3-信息抽取构建知识图谱的更多相关文章
- ACL2016信息抽取与知识图谱相关论文掠影
实体关系推理与知识图谱补全 Unsupervised Person Slot Filling based on Graph Mining 作者:Dian Yu, Heng Ji 机构:Computer ...
- springboot2.0+Neo4j+d3.js构建知识图谱
Welcome to the Neo4j wiki! 初衷这是一个知识图谱构建工具,最开始是对产品和领导为了做ppt临时要求配合做图谱展示的不厌其烦,做着做着就抽出一个目前看着还算通用的小工具 技术栈 ...
- Redis闲谈(1):构建知识图谱
场景:Redis面试 (图片来源于网络) 面试官: 我看到你的简历上说你熟练使用Redis,那么你讲一下Redis是干嘛用的? 小明: (心中窃喜,Redis不就是缓存吗?)Redis主要用作缓存,通 ...
- 中文维基百科分类提取(jwpl)--构建知识图谱数据获取
首先感谢 : 1.https://blog.csdn.net/qq_39023569/article/details/88556301 2.https://www.cnblogs.com/Cheris ...
- [知识图谱]Neo4j知识图谱构建(neo4j-python-pandas-py2neo-v3)
neo4j-python-pandas-py2neo-v3 利用pandas将excel中数据抽取,以三元组形式加载到neo4j数据库中构建相关知识图谱 Neo4j知识图谱构建 1.运行环境: pyt ...
- Task1:知识图谱介绍(1天)
一.知识图谱简介 "知识图谱本质上是语义网络(Semantic Network)的知识库".但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图( ...
- Atitit 知识图谱的数据来源
Atitit 知识图谱的数据来源 2. 知识图谱的数据来源1 a) 百科类数据2 b) 结构化数据3 c) 半结构化数据挖掘AVP (垂直站点爬虫)3 d) 通过搜索日志(query record ...
- Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview
Atitit 知识图谱解决方案:提供完整知识体系架构的搜索与知识结果overview 知识图谱的表示和在搜索中的展1 提升Google搜索效果3 1.找到最想要的信息.3 2.提供最全面的摘要.4 ...
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
随机推荐
- ChatGPT 时代,程序员的生存之道 | 人工智能 AI
前言 ChatGPT 近期炙手可热,仿佛没有什么问题是它不能解决的.出于对 ChatGPT 的好奇,我们决定探索下它对于前端开发人员来讲,是作为辅助工具多一些,还是主力工具更多一些? 2D 能力测试 ...
- CSS 图片加载提前占位 padding-top、padding-bottom
今天聊一个图片加载提前占位的一个问题 ,内容比较适合初学者. 起因 在响应式页面当中,图片加载之前是不知道图片高度的,加载成功图片完全撑开.如果不做提前占位会把下面的内容挤下去,页面出现抖动,就像下面 ...
- 精彩回顾 | 金蝶云苍穹技术开放日xUser Club广州站
6月14日,以"项目实践案例:性能优化与实践"为主题的金蝶云·苍穹技术开放日广州站圆满落幕.此次活动吸引了50多位开发者到场,大家不仅聆听了开发者关于"代码检查.性能优化 ...
- 洛谷 P8179 Tyres
滴叉题/se/se 题意 直接复制了 有 \(n\) 套轮胎,滴叉需要用这些轮胎跑 \(m\) 圈.使用第 \(i\) 套轮胎跑的第 \(j\) 圈(对每套轮胎单独计数)需要 \(a_i+b_i(j- ...
- 聊聊 ASP.NET 6 整洁架构开发模板
大家好,我是Edison. 最近看了一些整洁架构(CleanArchitecture)的文章,自己和同事也简单写了一个基于整洁架构的ASP.NET 6开发模板在玩.这里就仅仅抛个砖,案例主要以自己根据 ...
- GPT3的技术突破:实现更准确、更真实的语言生成
目录 1. 引言 2. 技术原理及概念 3. 实现步骤与流程 4. 应用示例与代码实现讲解 5. 优化与改进 6. 结论与展望 7. 附录:常见问题与解答 GPT-3 技术突破:实现更准确.更真实的语 ...
- Kafka中的消费者Offset
消费者位移 每个 consumer 实例都会为它消费的分区维护属于自己的位置信息来记录当前消费了多少条消息.这在 Kafka 中有一个特有的术语:位移(offset). 相比较将offset保存在服务 ...
- Redis解决网络抖动问题
Redis解决网络抖动问题 所谓网络抖动问题, 简单来说就是防止用户短暂的时间内对同一个接口多次点击访问 这里利用的是redis锁的原子性和with Statement上下文管理器实现, 另外该类还支 ...
- UE4构建基础和实践:一、概述
序言 构建这个概念是和应用程序包及资源等相关的,它的特点是使用脚本控制一系列的任务的处理,以减少人力操作带来的成本和操作失误风险. 在UE的概念里,构建往往是和打包相关的(如编译.cook.压缩打包等 ...
- Linux 概念:存储
块存储 (略) 文件存储 基于文件系统的本地文件存储: 基于网络的共享文件存储:NFS.Samba.Windows文件共享: 基于网络的分布式文件存储:HDFS... 对象存储 一种Key(对象ID) ...