Flask框架——请求扩展、flask中间件、蓝图、分析线程和协程
文章目录
01 请求扩展
01 before_first_request :项目启动后第一次请求的时候执行
@app.before_first_request
def before_first_request():
print('第一次请求的时候执行')
02 before_request:每次请求之前执行
@app.before_request
def before_request():
print('每次请求之前执行')
# return '直接return' # 如果有一个写了return返回值,那么其他的before_request不会执行,视图也不会执行。
注意:
- 可以写多个
- 如果有一个写了return返回值,那么其他的before_request不会执行,视图也不会执行。
03 after_request:每次请求之后执行,请求出现异常不会执行
def after_request(result):
print('每次请求之后执行,请求出现异常不会执行')
# 这个result是封装的响应对象,需要return否则报错
return result
04 errorhandler:可以自定义监听响应的状态码并处理:
@app.errorhandler(404)
def errorhandler(error):
print(error) # 是具体的错误信息
return '404页面跑到了火星上面去了'
@app.errorhandler(500)
def errorhandler(error):
print('errorhandler的错误信息')
print(error)
return '服务器内部错误500'
05 teardown_request:每次请求之后绑定了一个函数,在非debug模式下即使遇到了异常也会执行。
@app.teardown_request
def terardown_reqquest(error):
print('无论视图函数是否有错误,视图函数执行完都会执行')
print('想要此函数生效,debug不能为True')
print('error 是具体的错误信息')
print(error)
06 template_global():全局模板标签
@app.template_global()
def add(a1, a2):
return a1+a2
#{{add(1,2)}}
这个可以在模板中作为全局的标签使用,在模板中可以直接调用,调用方式:
{{add(1,2)}}
07 template_filter:全局模板过滤器
@app.template_filter()
def add_filter(a1, a2, a3):
return a1 + a2 + a3
这个可以在模板中作为全局过滤器使用,在模板中可以直接调用,调用方式(注意同template_global的区别) :
{{1|add_filter(2,3,4)}}
优势:
全局模板标签和全局模板过滤器简化了需要手动传一个函数给模板调用:
# app.py
```
def test(a1,a2):
return a1+a2
@app.route('/')
def index():
return render_template('index.html',test=test)
```
# index.html
```
{{test(22,22)}}
```
02 flask中间件
Flask的中间件的性质,就是可以理解为在整个请求的过程的前后定制一些个性化的功能。
flask的中间件的实现案例:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
print('视图函数中')
return 'hello world'
class my_middle:
def __init__(self,wsgi_app):
self.wsgi_app = wsgi_app
def __call__(self, *args, **kwargs):
print('中间件的代码上')
obj = self.wsgi_app( *args, **kwargs)
print('中间件的代码下')
return obj
if __name__ == '__main__':
app.wsgi_app = my_middle(app.wsgi_app)
# app.wsgi_app(environ, start_response)
app.run()
# 梳理一下 根据werkzeug我们可以知道 每次请求必然经历了app()
# 所以我们要查看Flask的源码找到__call__方法
# 找到了__call__方法后发现执行了return self.wsgi_app(environ, start_response)
# 然后flask里面所有的内容调度都是基于这个self.wsgi_app(environ, start_response),这就是就是flask的入口
# 如何实现中间件呢? 原理上就是重写app.wsgi_app,然后在里面添加上一些自己想要实现的功能。
# 首先分析 app.wsgi_app需要加括号执行 所以我们把app.wsgi_app做成一个对象,并且这个对象需要加括号运行
# 也就是会触发这个对象的类的__call__()方法
# 1 那么就是app.wsgi_app=对象=自己重写的类(app.wsgi_app) ,我们需要在自己重写的类里面实现flask源码中的app.wsgi_app,在实例化的过程把原来的app.wsgi_app变成对象的属性
# 2 app.wsgi_app() =对象() = 自己重写的类.call()方法
# 3 那么上面的代码就可以理解了,在自己重写的类中实现了原有的__call__方法
梳理:
- 根据
werkzeug我们可以知道 每次请求必然经历了app() - 所以我们要查看Flask的源码找到
__call__方法 - 找到了Flask的
__call__方法后发现执行了return self.wsgi_app(environ, start_response) - flask里面所有的内容调度都是基于这个
self.wsgi_app(environ, start_response),这就是就是flask的入口,也就是selef是app,也就是app.wsgi_app(environ, start_response)为程序的入口。 - 如何实现中间件呢? 原理上就是重写app.wsgi_app,然后在里面添加上一些自己想要实现的功能。
- 首先分析 app.wsgi_app需要加括号执行 所以我们把app.wsgi_app做成一个对象,并且这个对象需要加括号运行。
- 也就是会触发这个对象的类的
__call__()方法。
实操理解:
- app.wsgi_app=对象=自己重写的类(app.wsgi_app)
提示:我们需要在自己重写的类里面实现flask源码中的app.wsgi_app,在实例化的过程把原来的 app.wsgi_app变成对象的属性 - app.wsgi_app() =对象() = 自己重写的类.call()方法
app.wsgi_app(实参) =对象(实参) = 自己重写的类.call(实参)方法 - 那么上面的代码就可以理解了,在自己重写的类中实现了原有的call方法,并且重新调用了原有的app.wsgi_app
03 蓝图:
3.1 蓝图的基本使用
在我的flask中,我们可以利用蓝图对程序目录的划分。
思考如果我们有很多个视图函数,比如下面这样我们是不是应该抽取出来专门的py文件进行管理呢?
from flask import Flask
app = Flask(__name__)
@app.route('/login/')
def login():
return "login"
@app.route('/logout/')
def logout():
return "logout"
@app.route('/add_order/')
def add_order():
return "add_order"
@app.route('modify_order')
def modify_order():
return "modify_order"
if __name__ == '__main__':
app.run()
上面的这种是不是会显得主运行文件特别乱,这个时候我们的蓝图就闪亮登场了。
3.1.1实例:
项目目录:
-templates
-static
-views
-user.py
-order.py
-app.py
views/user.py
from flask import Blueprint
# 1 创建蓝图
user_bp = Blueprint('user',__name__)
# 2 利用蓝图创建路由关系
@user_bp.route('/login/')
def login():
return "login"
@user_bp.route('/logout/')
def logout():
return "logout"
views/order.py
from flask import Blueprint
order_bp = Blueprint('order',__name__)
@order_bp.route('/add_order/')
def add_order():
return "add_order"
@order_bp.route('/modify_order/')
def modify_order():
return "modify_order"
app.py
from flask import Flask
from views.user import user_bp
from views.order import order_bp
app = Flask(__name__)
# 3 注册蓝图
app.register_blueprint(user_bp)
app.register_blueprint(order_bp)
if __name__ == '__main__':
app.run()
访问:

其他的几条路由也是直接访问,在此就不做展示了。
讲解:
观察views/user.py
- 我们可以把所有的视图函数抽出来多个文件。
- 在这里我们通过
user_bp = Blueprint('user',__name__)创建一个蓝图对象
参数讲解:
- user_bp :是用于指向创建出的蓝图对象,可以自由命名。
- Blueprint的第一个参数自定义命名的
‘user’用于url_for翻转url时使用。 __name__用于寻找蓝图自定义的模板和静态文件使用。
蓝图对象的用法和之前实例化出来的app对象用法很像,可以进行注册路由。
这里我们需要手动的去注册一下蓝图,才会建立上url和视图函数的映射关系。
关键词:
创建蓝图
user_bp = Blueprint('user',__name__)利用蓝图创建路由关系
@bp.route('/login/')
def login():
return "login"
注册蓝图
app.register_blueprint(bp)
3.2 蓝图的高级使用(重点备课内容)
3.2.1 蓝图中实现path部分的url前缀
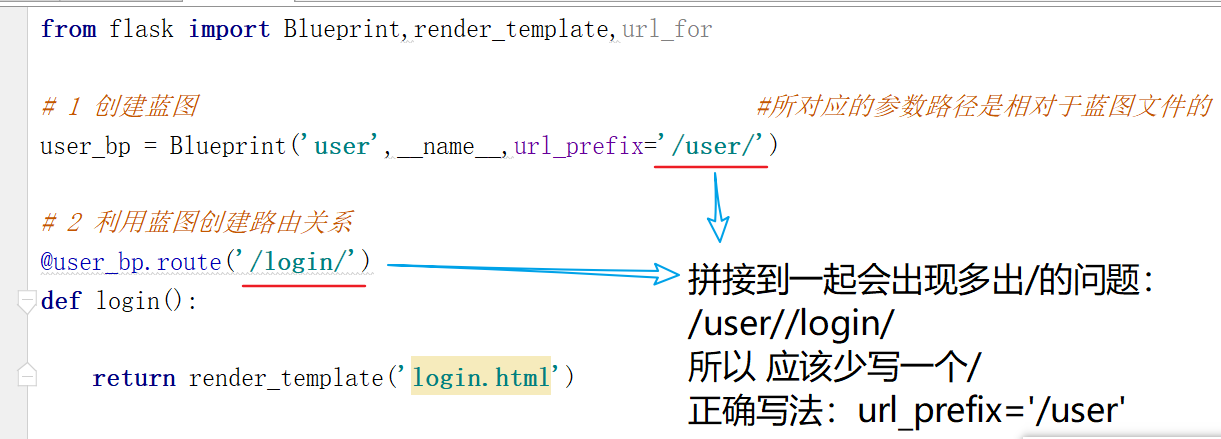
创建蓝图的时候填写url_prefix可以为增加url的path部分的前缀,可以更方便的去管理访问视图函数。
from flask import Blueprint
# 1 创建蓝图
user_bp = Blueprint('user',__name__,url_prefix='/user')
# 注意斜杠跟视图函数的url连起来时候不要重复了。
注意:
- 斜杠跟视图函数的url连起来时候不要重复了。
图解:
2.url加前缀的时候也可以再注册蓝图的时候加上,更推荐这么做,因为代码的可读性更强。
app.register_blueprint(user_bp,url_prefix='/order')
3.3.2 蓝图中自定义模板路径
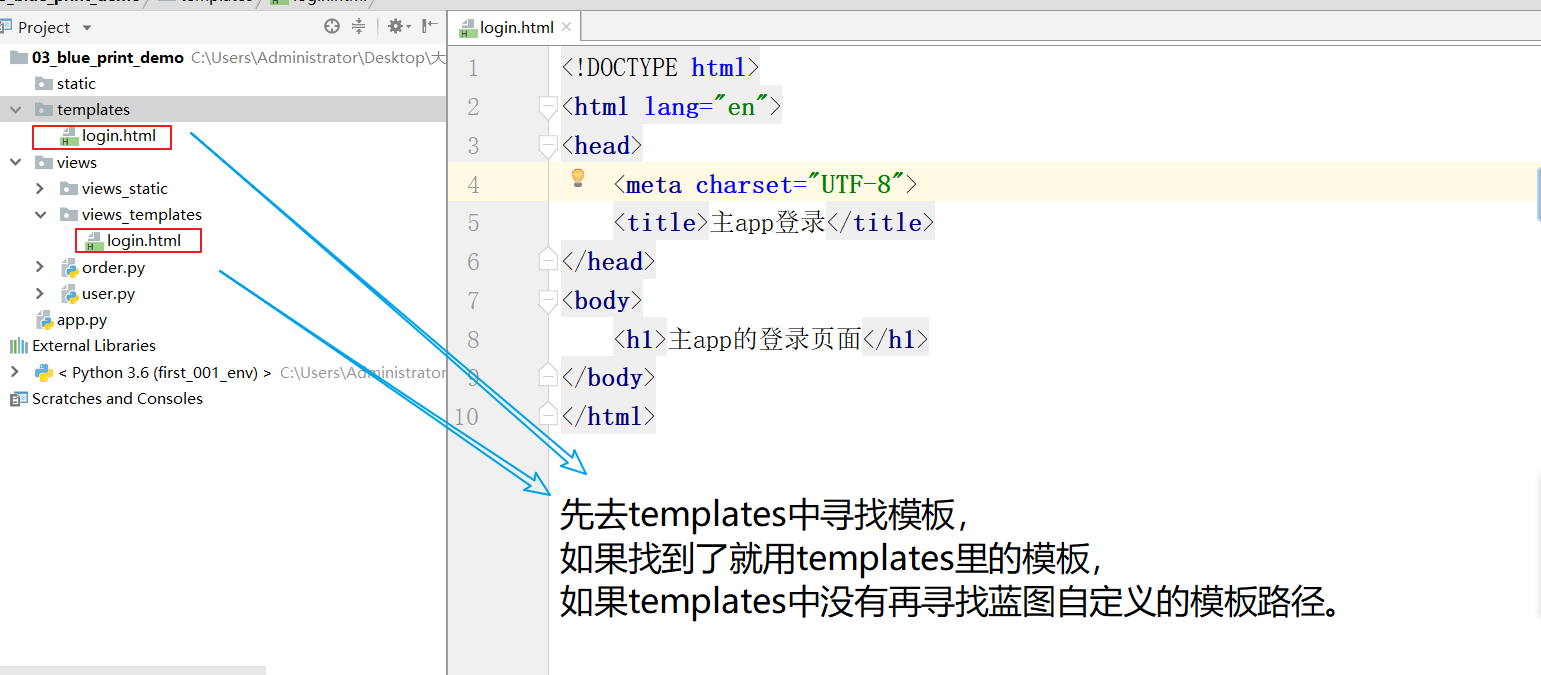
创建蓝图的时候填写template_folder可以指定自定义模板路径
# 1 创建蓝图 #所对应的参数路径是相对于蓝图文件的
user_bp = Blueprint('user',__name__,url_prefix='/user',template_folder='views_templates')
注意:
- 蓝图虽然指定了自定义的模板查找路径,但是查找顺序还是会先找主app规定的模板路径(templates),找不到再找蓝图自定义的模板路径。
Blueprint的template_folder参数指定的自定义模板路径是相对于蓝图文件的路径。
图解:
(01)

(02)
3.3.3 蓝图中自定义静态文件路径
创建蓝图的时候填写static_folder可以指定自定义静态文件的路径
user_bp = Blueprint('user',__name__,url_prefix='/user',template_folder='views_templates',static_folder='views_static')
注意:
- 在模板中使用自定义的静态文件路径需要依赖
url_for() - 下节讲解如何在模板中应用蓝图自定义的静态文件。
3.3.4 url_for()翻转蓝图
视图中翻转url:
url_for('创建蓝图时第一个参数.蓝图下的函数名')
# 如:
url_for('user.login')
模板中翻转url:
{{ url_for('创建蓝图时第一个参数.蓝图下的函数名') }}
# 如:
{{ url_for('user.login') }}
模板中应用蓝图自定义路径的静态文件:
{{ url_for('创建蓝图时第一个参数.static',filename='蓝图自定义静态文件路径下的文件') }}
# 如:
{{ url_for('user.static',filename='login.css') }}
3.3.5 蓝图子域名的实现
创建蓝图的时候填写subdomain可以指定子域名,可以参考之前注册路由中实现子域名。
(1) 配置C:\Windows\System32\drivers\etc\hosts
127.0.0.1 bookmanage.com
127.0.0.1 admin.bookmanage.com
(2) 给app增加配置
app.config['SERVER_NAME'] = 'bookmanage.com:5000'
(3) 创建蓝图的时候添加子域名 subdomain='admin'
# 1 创建蓝图
user_bp = Blueprint('user',__name__,url_prefix='/user',template_folder='views_templates',
static_folder='views_static',subdomain='admin')
# 2 利用蓝图创建路由关系
@user_bp.route('/login/')
def login():
return render_template('login_master.html')
(4) 访问admin.bookmanage.com:5000/user/login/

3.3.6 蓝图中使用自己请求扩展
在蓝图中我们可以利用创建好的蓝图对象,设置访问蓝图的视图函数的时候触发蓝图独有的请求扩展。
例如:
order_bp = Blueprint('order',__name__)
@order_bp.route('/add_order/')
def add_order():
return "add_order"
@order_bp.before_request
def order_bp_before_request():
return '请登录'
注意:
- 只有访问该蓝图下的视图函数时候才会触发该蓝图的请求扩展。
- 可以这么理解:相当app的请求扩展是全局的,而蓝图的请求扩展是局部的只对本蓝图下的视图函数有效。
3.3 使用蓝图之中小型系统
目录结构:
-flask_small_pro
-app01
-__init__.py
-static
-templates
-views
-order.py
-user.py
-manage.py
__init__.py
from flask import Flask
from app01.views.user import user_bp
from app01.views.order import order_bp
app = Flask(__name__)
app.register_blueprint(user_bp,url_prefix='/user')
app.register_blueprint(order_bp)
user.py
from flask import Blueprint
user_bp = Blueprint('user',__name__)
@user_bp.route('/login/')
def login():
return 'login'
@user_bp.route('/logout/')
def logout():
return 'logout'
order.py
from flask import Blueprint
order_bp = Blueprint('order',__name__)
@order_bp.route('/add_order/')
def add_order():
return 'buy_order'
@order_bp.route('/modify_order/')
def modify_order():
return 'modify_order'
manage.py
from app01 import app
if __name__ == '__main__':
app.run()
3.4 使用蓝图之使用大型系统
这里所谓的大型系统并不是绝对的大型系统,而是相对规整的大型系统,相当于提供了一个参考,在真实的生成环境中会根据公司的项目以及需求,规划自己的目录结构。
文件路径:
│ run.py
│
│
└─pro_flask # 文件夹
│ __init__.py
│
├─admin # 文件夹
│ │ views.py
│ │ __init__.py
│ │
│ ├─static # 文件夹
│ └─templates # 文件夹
│
└─web # 文件夹
│ views.py
│ __init__.py
│
├─static # 文件夹
└─templates # 文件夹
run.py 启动app
from pro_flask import app
if __name__ == '__main__':
app.run()
__init__.py 实例化核心类,导入蓝图对象,注册蓝图。
from flask import Flask
from .admin import admin
from .web import web
app = Flask(__name__)
app.debug = True
app.register_blueprint(admin, url_prefix='/admin')
app.register_blueprint(web)
admin.views.py 完成注册路由以及视图函数
from . import admin
@admin.route('/index')
def index():
return 'Admin.Index'
admin.__init__.py 生成蓝图对象导入views,使得views的代码运行完成注册路由
from flask import Blueprint
admin = Blueprint(
'admin',
__name__,
template_folder='templates',
static_folder='static'
)
from . import views # 这个必须要放在最后面才可以,不然会报错循环导入
web文件夹下和admin文件夹下目录构成完全一致,这里就不举例子了。
分析线程和协程
01 思考:每个请求之间的关系
我们每一个请求进来的时候都开一个进程肯定不合理,那么如果每一个请求进来都是串行的,那么根本实现不了并发,所以我们假定每一个请求进来使用的是线程。
那么线程中数据互相不隔离,存在修改数据的时候数据不安全的问题。
假定我们的需求是,每个线程都要设置值,并且该线程打印该线程修改的值。
from threading import Thread,current_thread
import time
class Foo(object):
def __init__(self):
self.name = 0
locals_values = Foo()
def func(num):
locals_values.name = num
time.sleep(2) # 取出该线程的名字
print(locals_values.name, current_thread().name)
for i in range(10):
# 设置该线程的名字
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
很明显阻塞了2秒的时间所有的线程都完成了修改值,而2秒后所有的线程打印出来的时候都是9了,就产生了数据不安全的问题。
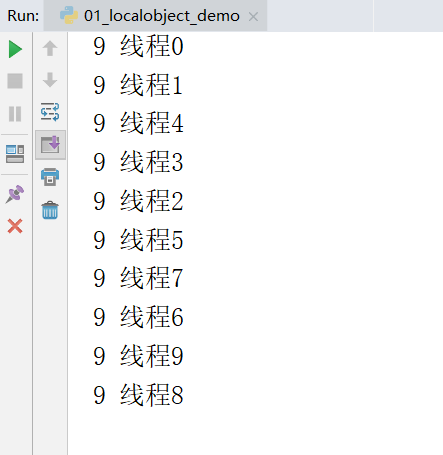
所以我们要解决这种线程不安全的问题,有如下两种解决方案。
- 方案一:是加锁
- 方案二:使用
threading.local对象把要修改的数据复制一份,使得每个数据互不影响。
我们要实现的并发是多个请求实现并发,而不是纯粹的只是修改一个数据,所以第二种思路更适合做我们每个请求的并发,把每个请求对象的内容都复制一份让其互相不影响。
详解:为什么不用加锁的思路?加锁的思路是多个线程要真正实现共用一个数据,并且该线程修改了数据之后会影响到其他线程,更适合类似于12306抢票的应用场景,而我们是要做请求对象的并发,想要实现的是该线程对于请求对象这部分内容有任何修改并不影响其他线程。所以使用方案二
02 threading.local

多个线程修改同一个数据,复制多份数据给每个线程用,为每个线程开辟一块空间进行数据存储
实例:
from threading import Thread,current_thread,local
import time
locals_values = local()
# 可以简单理解为,识别到新的线程的时候,都会开辟一片新的内存空间,相当于每个线程对该值进行了拷贝。
def func(num):
locals_values.name = num
time.sleep(2)
print(locals_values.name, current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
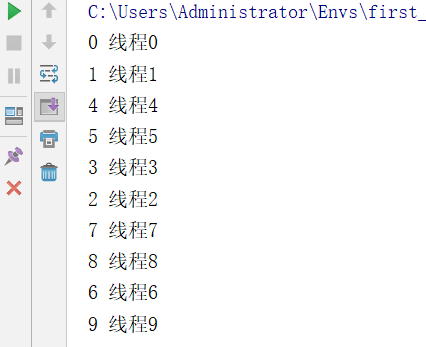
如上通过threading.local实例化的对象,实现了多线程修改同一个数据,每个线程都复制了一份数据,并且修改的也都是自己的数据。达到了我们想要的效果。
03 通过字典自定义threading.local
实例:
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
storage = {}# 初始化一个字典
get_ident = get_ident # 拿到get_ident的地址
def set(self,k,v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def get(self,k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
locals_values.set('KEY',num)
time.sleep(2)
print(locals_values.get('KEY'),current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
讲解:
利用get_ident()获取每个线程的唯一标记作为键,然后组织一个字典storage。
如:{线程1的唯一标记:{k:v},线程2的唯一标记:{k:v}…}
{
15088: {'KEY': 0},
8856: {'KEY': 1},
17052: {'KEY': 2},
8836: {'KEY': 3},
13832: {'KEY': 4},
15504: {'KEY': 5},
16588: {'KEY': 6},
5164: {'KEY': 7},
560: {'KEY': 8},
1812: {'KEY': 9}
}
运行效果:
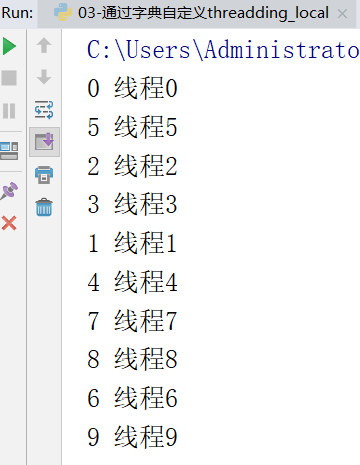
04 通过setattr和getattr实现自定义threthreading.local
实例:
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
storage = {}# 初始化一个字典
get_ident = get_ident # 拿到get_ident的地址
def __setattr__(self, k, v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def __getattr__(self, k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
locals_values.KEY=num
time.sleep(2)
print(locals_values.KEY,current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
提示:
05 每个对象有自己的存储空间(字典)
我们可以自定义实现了threading.local的功能,但是现在存在一个问题,如果我们想生成多个Local对象,但是会导致多个Local对象所管理的线程设置的内容都放到了类属性storage = {}里面,所以我们如果想实现每一个Local对象所对应的线程设置的内容都放到自己的storage里面,就需要重新设计代码。
实例:
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
def __init__(self):
# 千万不要按照注释里这么写,否则会造成递归死循环,死循环在__getattr__中,不理解的话可以全程使用debug测试。
# self.storage = {}
# self.get_ident =get_ident
object.__setattr__(self,"storage",{})
object.__setattr__(self,"get_ident",get_ident) #借用父类设置对象的属性,避免递归死循环。
def __setattr__(self, k, v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def __getattr__(self, k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
locals_values2 = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
# locals_values.set('KEY',num)
locals_values.KEY=num
time.sleep(2)
print(locals_values.KEY,current_thread().name)
# print('locals_values2.storage:',locals_values2.storage) #查看locals_values2.storage的私有的storage
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
显示效果我们就不做演示了,和前几个案例演示效果一样。
06 如果是你会如何设计flask的请求并发?
- 情况一:单进程单线程,基于全局变量就可以做
- 情况二:单进程多线程,基于threading.local对象做
- 情况三:单进程多线程多协程,如何做?
提示:协程属于应用级别的,协程会替代操作系统自动切换遇到IO的任务或者运行级别低的任务,而应用级别的切换速度远高于操作系统的切换
当然如果是自己来设计框架,为了提升程序的并发性能,一定是上诉的情况三,不光考虑多线程并且要多协程,那么该如何设计呢?
在我们的flask中为了这种并发需求,依赖于底层的werkzeug外部包,werkzeug实现了保证多线程和多携程的安全,werkzeug基本的设计理念和上一个案例一致,唯一的区别就是在导入的时候做了一步处理,且看werkzeug源码。
werkzeug.local.py部分源码
try:
from greenlet import getcurrent as get_ident # 拿到携程的唯一标识
except ImportError:
try:
from thread import get_ident #线程的唯一标识
except ImportError:
from _thread import get_ident
class Local(object):
...
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
...
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
讲解:
原理就是在最开始导入线程和协程的唯一标识的时候统一命名为get_ident,并且先导入协程模块的时候如果报错说明不支持协程,就会去导入线程的get_ident,这样无论是只有线程运行还是协程运行都可以获取唯一标识,并且把这个标识的线程或协程需要设置的内容都分类存放于__storage__字典中。
Flask框架——请求扩展、flask中间件、蓝图、分析线程和协程的更多相关文章
- Flask 的 请求扩展 与 中间件
Flask 的 请求扩展 与 中间件 flask 可以通过 扩展(装饰器)来实现类似于django 中间件的功能 类似于django 的中间件, 在执行视图函数之前, 之后的执行某些功能 1 @app ...
- flask之分析线程和协程
flask之分析线程和协程 01 思考:每个请求之间的关系 我们每一个请求进来的时候都开一个进程肯定不合理,那么如果每一个请求进来都是串行的,那么根本实现不了并发,所以我们假定每一个请求进来使用的是线 ...
- Flask 之分析线程和协程
目录 flask之分析线程和协程 01 思考:每个请求之间的关系 02 threading.local 03 通过字典自定义threading.local 04 通过setattr和getattr实现 ...
- Flask框架(三)—— 请求扩展、中间件、蓝图、session源码分析
Flask框架(三)—— 请求扩展.中间件.蓝图.session源码分析 目录 请求扩展.中间件.蓝图.session源码分析 一.请求扩展 1.before_request 2.after_requ ...
- 第二篇 Flask基础篇之(闪现,蓝图,请求扩展,中间件)
本篇主要内容: 闪现 请求扩展 中间件 蓝图 写装饰器,常用 functools模块,帮助设置函数的元信息 import functools def wrapper(func): @functools ...
- Flask框架 请求与响应 & 模板语法
目录 Flask框架 请求与响应 & 模板语法 简单了解Flask框架 Flask 框架 与 Django 框架对比 简单使用Flask提供服务 Flask 中的 Response(响应) F ...
- 分析Tornado的协程实现
转自:http://www.binss.me/blog/analyse-the-implement-of-coroutine-in-tornado/ 什么是协程 以下是Wiki的定义: Corouti ...
- Flaks框架(Flask请求响应,session,闪现,请求扩展,中间件,蓝图)
目录 一:Flask请求响应 1.请求相关信息 2.flask新手四件套 3.响应相关信息(响应response增加数据返回) 二:session 1.session与cookie简介 2.在使用se ...
- flask框架(六)——闪现(get_flashed_message)、请求扩展、中间件(了解)
message -设置:flash('aaa') -取值:get_flashed_message() -假设在a页面操作出错,跳转到b页面,在b页面显示a页面的错误信息 1 如果要用flash就必须设 ...
- Flask框架(二):路由与蓝图
一.路由 使用 route() 装饰器来把函数绑定到 URL: @app.route('/') def index(): return 'Index Page' @app.route("/h ...
随机推荐
- 【leetcode】# 7 整数翻转 Rust Solution
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转.示例 1:输入: 123输出: 321 示例 2:输入: -123输出: -321示例 3:输入: 120输出: 21注意:假设 ...
- 记一次加锁导致ECS服务器CPU飙高的处理
导航 火线告警,CPU飚了 版本回退,迅速救火 猜测:分布式锁是罪魁祸首 代码重构,星夜上线 防患未然,功能可开关 高度戒备,应对早高峰 实时调整方案,稳了 结语 参考 本文首发于智客工坊-<记 ...
- Helm实战案例二:在Kubernetes(k8s)上使用helm安装部署日志管理系统EFK
目录 一.系统环境 二.前言 三.日志管理系统EFK简介 四.helm安装EFK 4.1 helm在线安装EFK 4.2 helm离线安装EFK(推荐) 五.访问kibana 5.1 数据分片 六.卸 ...
- .NET7 for LoongArch64(国产龙芯)
目前龙芯通过自己的指令集LA64支持了.Net7.0.1版本,一同被支持的有Ruby,Nodejs,Java,Electron,Python等.原文:在此处 龙芯.Net7 sdk下载地址: http ...
- 第四章 VIVIM编辑器
1. 是什么 VI 是 Unix 操作系统和类 Unix 操作系统中最通用的文本编辑器. VIM 编辑器是从 VI 发展出来的一个性能更强大的文本编辑器. 2. 一般模式 以 vi/v ...
- 【原创】xenomai内核解析-xenomai实时线程创建流程
版权声明:本文为本文为博主原创文章,未经同意,禁止转载.如有错误,欢迎指正,博客地址:https://www.cnblogs.com/wsg1100/ 目录 问题概述 1 libCobalt中调用非实 ...
- CPU性能指标介绍及分析
CPU是计算机系统中最核心的组件之一,对系统性能起着至关重要的作用.以下是一些常见的CPU性能指标及其分析: 1. %user(用户态)和 %system(内核态) %user:表示CPU花费在用户进 ...
- Chrome浏览器,有道云笔记的网页剪报需要多次登录且收藏失败报错
报错代码 {"canTryAgain":false,"scope":"SECURITY","error":"2 ...
- jquery中for循环一共几种
$.each() 第一个参数是循环的对象 , 第二个参数对对象中的每一个元素 执行 function函数 ,function 的第一个参数 i 是索引,item 是 循环对象中的每一个元素.
- Magick.NET跨平台压缩图片的用法
//首先NuGet安装:Magick.NET.Core,Magick.NET-Q16-AnyCPUusing ImageMagick; /// <summary> /// 压缩图片 /// ...