pandas DataFrame内存优化技巧:让数据处理更高效
Pandas无疑是我们数据分析时一个不可或缺的工具,它以其强大的数据处理能力、灵活的数据结构以及易于上手的API赢得了广大数据分析师和机器学习工程师的喜爱。
然而,随着数据量的不断增长,如何高效、合理地管理内存,确保Pandas DataFrame在运行时不会因内存不足而崩溃,成为我们每一个人必须面对的问题。
在这个信息爆炸的时代,数据规模呈指数级增长,如何优化内存使用,不仅关乎到程序的稳定运行,更直接关系到数据处理的效率和准确性。通过本文,你将了解到一些实用的内存优化技巧,帮助你在处理大规模数据集时更加得心应手。
1. 准备数据
首先,准备一些包含各种数据类型的测试数据集。
封装一个函数(fake_data),用来生成数据集,数据集中包含后面用到的几种字段。
import pandas as pd
import numpy as np
def fake_data(size):
"""
根据测试数据集:
age:整数类型数值
grade:有限个数的字符串
qualified:是否合格
ability:能力评估,浮点类型数值
"""
df = pd.DataFrame()
df["age"] = np.random.randint(1, 30, size)
df["grade"] = np.random.choice(
[
"一年级",
"二年级",
"三年级",
"四年级",
"五年级",
"六年级",
],
size,
)
df["qualified"] = np.random.choice(["合格", "不合格"], size)
df["ability"] = np.random.uniform(0, 1, size)
return df
2. 检测内存占用
使用上面封装的函数(fake_data)先构造一个包含一百万条数据的DataFrame。
df = fake_data(1_000_000)
df.head()
看看优化前的内存占用情况:
df.info()
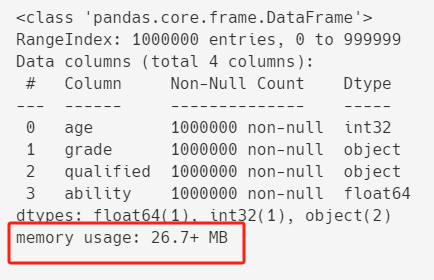
内存占用大约 26.7MB 左右。
3. 优化内存
接下来,我们开始一步步优化DataFrame的内存占用,
并测试每一步优化之后的内存使用情况和运行性能变化。
3.1. 优化整型数据
首先,优化整型数据的内存占用,也就是测试数据中的年龄(age)字段。
从上面df.info()的结果中,我们可以看出,age的类型是int32(也就是用32位,8个字节来存储整数)。
对于年龄来说,用不到这么大的整数,用int8(数值范围:-128~127)来存储绰绰有余。
df["age"] = df["age"].astype("int8")
df.info()
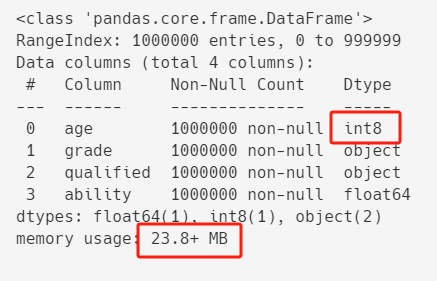
优化之后,内存占用从26.7+ MB减到23.8+ MB。
3.2. 优化浮点型数据
接下来优化浮点类型数据,也就是测试数据中的能力评估值(ability)。
测试数据中ability的值是6位小数,类型是float64,
转换成float16可能会改变值,所以这里转换成float32。
df["ability"] = df["ability"].astype("float32")
df.info()
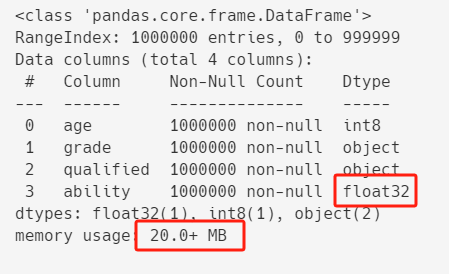
优化之后,内存占用进一步从23.8+ MB减到20.0+ MB。
3.3. 优化布尔型数据
接下来,优化测试数据中的是否合格(qualified),
这个值虽然是字符串类型,但是它的值只有两种(合格和不合格),所以可以转换成布尔类型。
df["qualified"] = df["qualified"].map({"合格": True, "不合格": False})
df.info()
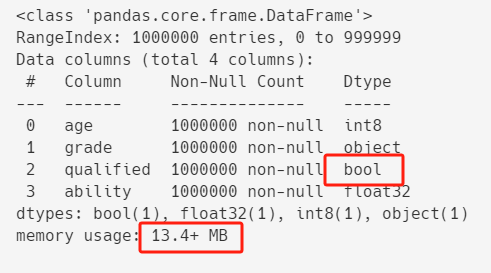
优化之后,内存占用进一步从20.0+ MB减到13.4+ MB。
3.4. 使用category类型
最后,我们再优化剩下的字段--年级(grade)。
这个字段也是字符串,不过它的值只有6个,虽然无法转换成布尔类型(布尔类型只有两种值True和False),但是它可以转换为pandas中的 category 类型。
df["grade"] = df["grade"].astype("category")
df.info()
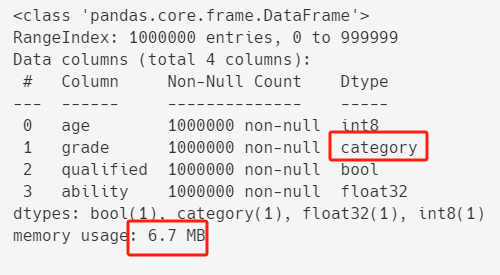
优化之后,内存占用进一步从13.4+ MB减到6.7+ MB。
4. 总结
各类字段优化之后,内存占用从刚开始的26.7+ MB减到6.7+ MB,优化的效果非常明显。
仅仅是数据类型的简单调整,就带来了如此之大的内存效率提升,
这也给我们带来启示,在数据分析的过程中,构造DataFrame时,也可以根据数值的范围,特点等,
来赋予它合适的类型,不要一味简单的使用字符串,或者默认的整数(int32),默认的浮点(float64)等类型。
pandas DataFrame内存优化技巧:让数据处理更高效的更多相关文章
- 内存管理 & 内存优化技巧 浅析
内存管理 浅析 下列行为都会增加一个app的内存占用: 1.创建一个OC对象: 2.定义一个变量: 3.调用一个函数或者方法. 如果app占用内存过大,系统可能会强制关闭app,造成闪退现象,影响用户 ...
- github 项目搜索技巧-让你更高效精准地搜索项目
目录 github 搜索技巧 案例 普通搜 搭配技巧搜 限定词 查找某个用户或组织的项目 辅助限定词 还没搞懂的(关于 forks.mirror.issues) 排序(放的是官网的链接) 使用指南 练 ...
- redis的内存优化【转】
Redis所有的数据都在内存中,而内存又是非常宝贵的资源.对于如何优化内存使用一直是Redis用户非常关注的问题.本文让我们深入到Redis细节中,学习内存优化的技巧.分为如下几个部分: 一.redi ...
- Impala内存优化(转载)
一. 引言 Hadoop生态中的NoSQL数据分析三剑客Hive.HBase.Impala分别在海量批处理分析.大数据列式存储.实时交互式分析各有所长.尤其是Impala,自从加入Hadoop大家庭以 ...
- [转]探索 Android 内存优化方法
前言 这篇文章的内容是我回顾和再学习 Android 内存优化的过程中整理出来的,整理的目的是让我自己对 Android 内存优化相关知识的认识更全面一些,分享的目的是希望大家也能从这些知识中得到一些 ...
- Redis之内存优化
Redis所有的数据都存在内存中,当前内存虽然越来越便宜,但跟廉价的硬盘相比成本还是比较昂贵,因此如何高效利用Redis内存变得非常重要.高效利用Redis内存首先需要理解Redis内存消耗在哪里,如 ...
- SQLServer 2014 内存优化表
内存优化表是 SQLServer 2014 的新功能,它是可以将表放在内存中,这会明显提升DML性能.关于内存优化表,更多可参考两位大侠的文章:SQL Server 2014新特性探秘(1)-内存数据 ...
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- IOS 内存优化和调试技巧
基础部分 1: 图片内存大小小结 a: 图片:是占用内存的大户,尤其是手机游戏图片资源众多.对图片资源在内存中占用量的计算成为J2ME游戏开发者的经常性工作,CoCoMo来解释一下如何计算图片在内存中 ...
- pandas DataFrame 数据处理常用操作
Xgboost调参: https://wuhuhu800.github.io/2018/02/28/XGboost_param_share/ https://blog.csdn.net/hx2017/ ...
随机推荐
- Spark源码修改环境搭建
过程中存在问题: maven编译scala工程报错java.lang.NoClassDefFoundError: scala/reflect/internal/Trees,解决方案看maven编译 1 ...
- centos编译安装tcpdump
环境 CentOS Linux release 7.9.2009 (Core) 准备安装包 libpcap-1.5.3.tar.gz tcpdump-4.9.2.tar.gz 下载地址:https:/ ...
- Windows配置PHP的MongoDB扩展
环境 Windows 10 PHP 5.6.40/8.1.11 配置 下载MongoDB扩展 下载地址:https://pecl.php.net/package/mongodb 下载PHP版本对应的扩 ...
- 【链表】链表的合并【经典面试OJ详解】【力扣21,力扣23】超详细的算法教程
链表的合并 导航小助手 说在前面 题目链接 链表结构 OJ21.合并两个有序链表 题目描述和算法分析 接口的完整实现代码 OJ23.合并K个升序链表 题目描述和算法分析 接口的完整实现代码 尾声 说在 ...
- CF1833F Ira and Flamenco
题目链接 题解 知识点:组合数学,枚举,双指针. 注意到,长度为 \(m\) 且数字各不相同的子序列,那么最大值与最小值的差至少为 \(m-1\) .因此,对于任意子序列,它是合法的,当且仅当,将其从 ...
- Swoole从入门到入土(26)——多进程[进程间锁]
多进程在Swoole中是一个很重要的话题,即是协程机制也是依赖于进程.所以Swoole\Lock让大家在PHP 代码中可以很方便地创建一个锁,用来实现数据同步.Lock 类支持以下 5 种锁的类型: ...
- virtualbox安装oracle linux后找不到eth0
用VirtualBox装oracle linux, ifconfig发现没有eth0: 按照以下步骤操作: 1 用ifconfig eth0 up启动网卡(默认未开启),执行ifconfig下看到et ...
- Redhat6更改yum源
最近虚拟机中安装了redhat6.3企业版,自带的yum用不起来,软件都找不到. 网上搜了一下说是没付钱...,需要改下yum源.操作步骤如下: 1.切换到yum源存放目录 [root@rhel6 ~ ...
- timeit测试函数执行时间
def list_append(): l = [] for i in range(5000): l.append(i) def list_insert(): l = [] for i in range ...
- ubuntu18.04下nginx配合fastdfs使用的安装和配置
前期准备 1.安装依赖包 # 新装的ubuntu缺少gcc编译,需要先安装这个 sudo apt-get install build-essential 1.解压缩 libfastcommon-mas ...