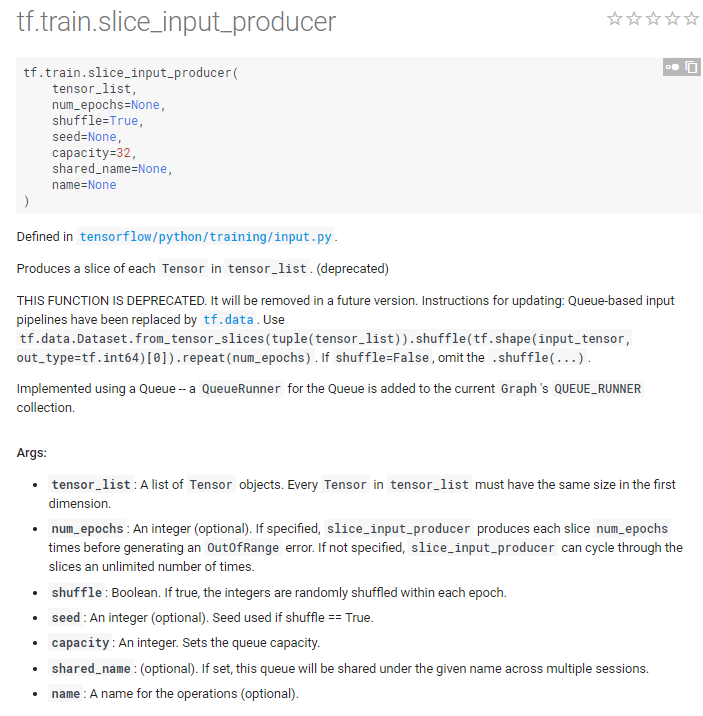
tf.train.slice_input_producer()
tf.train.slice_input_producer处理的是来源tensor的数据
转载自:https://blog.csdn.net/dcrmg/article/details/79776876 里面有详细参数解释
官方说明
简单使用
import tensorflow as tf images = ['img1', 'img2', 'img3', 'img4', 'img5']
labels= [1,2,3,4,5] epoch_num=8 f = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=True) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(epoch_num):
k = sess.run(f)
print (i,k) coord.request_stop()
coord.join(threads)
运行结果:

用tf.data.Dataset.from_tensor_slices调用,之前的会被抛弃,用法:https://blog.csdn.net/qq_32458499/article/details/78856530
结合批处理
import tensorflow as tf
import numpy as np # 样本个数
sample_num=5
# 设置迭代次数
epoch_num = 2
# 设置一个批次中包含样本个数
batch_size = 3
# 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size):
images, label = generate_data()
# 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=False) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64)
return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一轮迭代
print ('************')
for j in range(batch_total): #每一个batch
print ('--------')
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
# for k in
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)
运行结果:

tf.train.slice_input_producer()的更多相关文章
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- 【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址: https://blog.csdn.net/dcrmg/article/details/79776876 ----------------------------------------- ...
- 【转载】 tf.train.slice_input_producer()和tf.train.batch()
原文地址: https://www.jianshu.com/p/8ba9cfc738c2 ------------------------------------------------------- ...
- tensorflow|tf.train.slice_input_producer|tf.train.Coordinator|tf.train.start_queue_runners
#### ''' tf.train.slice_input_producer :定义样本放入文件名队列的方式[迭代次数,是否乱序],但此时文件名队列还没有真正写入数据 slice_input_prod ...
- tfsenflow队列|tf.train.slice_input_producer|tf.train.Coordinator|tf.train.start_queue_runners
#### ''' tf.train.slice_input_producer :定义样本放入文件名队列的方式[迭代次数,是否乱序],但此时文件名队列还没有真正写入数据 slice_input_pr ...
- tensorflow数据读取机制tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程 ...
- Tensorflow读取大数据集的方法,tf.train.string_input_producer()和tf.train.slice_input_producer()
1. https://blog.csdn.net/qq_41427568/article/details/85801579
- 深度学习原理与框架-Tfrecord数据集的读取与训练(代码) 1.tf.train.batch(获取batch图片) 2.tf.image.resize_image_with_crop_or_pad(图片压缩) 3.tf.train.per_image_stand..(图片标准化) 4.tf.train.string_input_producer(字符串入队列) 5.tf.TFRecord(读
1.tf.train.batch(image, batch_size=batch_size, num_threads=1) # 获取一个batch的数据 参数说明:image表示输入图片,batch_ ...
随机推荐
- JQuery--val()、html()、text()
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- springboot security 安全
spring security几个概念 “认证”(Authentication) 是建立一个他声明的主体的过程(一个“主体”一般是指用户,设备或一些可以在你的应用程序中执行动作的其他系统) . “授权 ...
- poj2987 最大权闭合图
基础题. 最小割后,与汇点相连的点都不要,然后从源点出发dfs一遍有多少相连的点即可. #include<stdio.h> #include<string.h> #includ ...
- oracle回滚机制深入研究
这篇文章主要描写叙述oracle的回滚机制,篇幅可能较长,由于对于oracle的回滚机制来说,要讨论和描写叙述的实在太多,仅仅能刷选自己觉得最有意义的一部分进行深入研究和分享 一.我们来看一个DML语 ...
- Java练习 SDUT-2749_区域内点的个数
区域内点的个数 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description X晚上睡不着的时候不喜欢玩手机,也不喜欢打游戏,他喜欢数 ...
- Nacos 发布 1.0.0 GA 版本,可大规模投入到生产环境
经过 3 个 RC 版本的社区体验之后,Nacos 正式发布 1.0.0 GA 版本,在架构.功能和 API 设计上进行了全方位的重构和升级. 1.0.0 版本的发布标志着 Nacos 已经可以大规模 ...
- 2019-1-9-WPF-最小的代码使用-DynamicRenderer-书写
title author date CreateTime categories WPF 最小的代码使用 DynamicRenderer 书写 lindexi 2019-1-9 14:7:26 +080 ...
- Python基础:11变量作用域和闭包
一:变量作用域 变量可以是局部域或者全局域.定义在函数内的变量有局部作用域,在一个模块中最高级别的变量有全局作用域. 全局变量的一个特征是除非被删除掉,否则它们的存活到脚本运行结束,且对于所有的函数, ...
- ocilib linux编译安装
1.首先下载ocilib到自己目录 github:https://github.com/vrogier/ocilib 2.在下载instantclient 11.2.2的文件: instantclie ...
- java根据年月获取当前月的每一天日期
public static List<String> getDayByMonth(int yearParam,int monthParam){ List list = ne ...