Flink sql 之 微批处理与MiniBatchIntervalInferRule (源码分析)
本文源码基于flink1.14
平台用户在使用我们的flinkSql时经常会开启minaBatch来优化状态读写
所以从源码的角度具体解读一下miniBatch的原理
先看一下flinksql是如何触发miniBatch的优化的
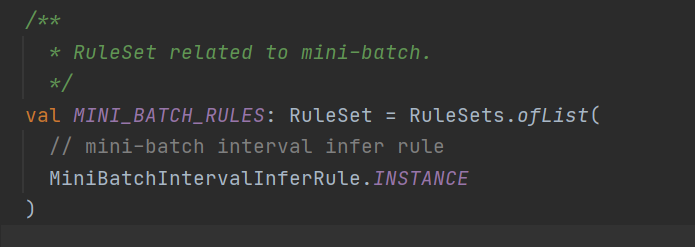
主要就是这个Calcite的rule了,来具体看一下
在对应的match方法中
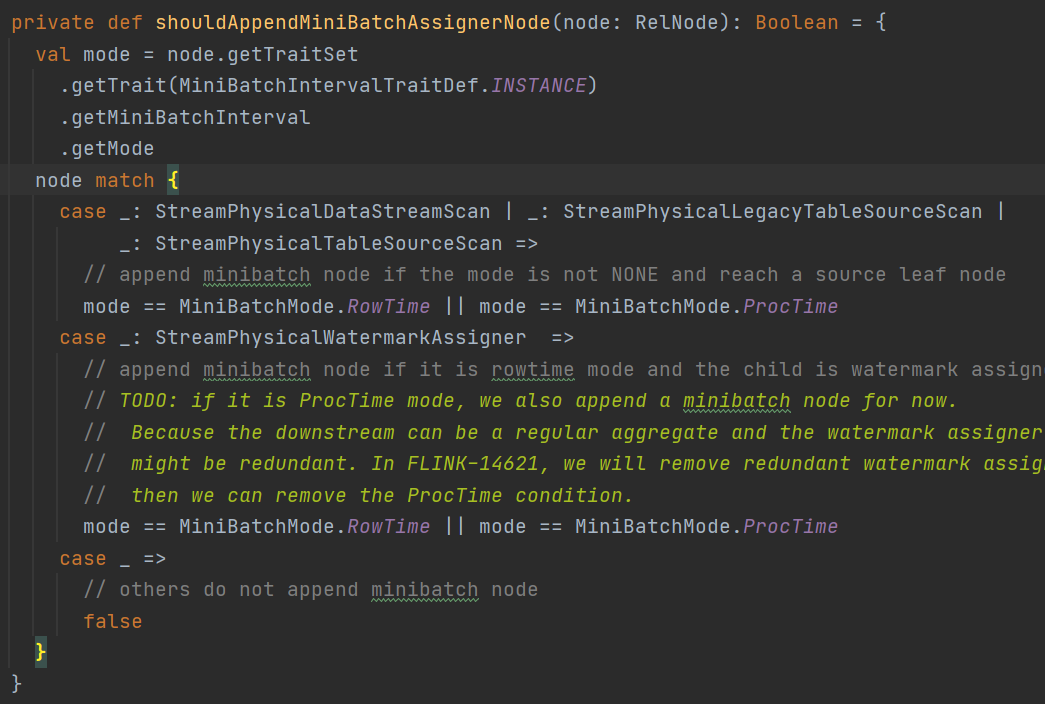
会根据miniBatch的类型判断,是否需要添加一个Assigner的节点
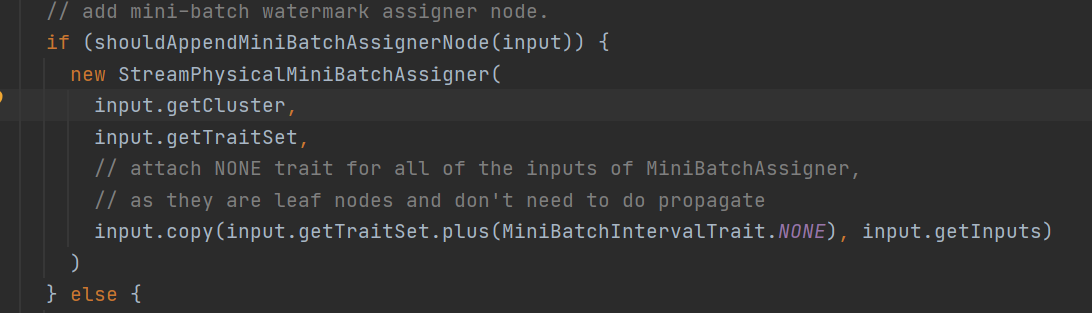
这个assigner是干嘛的呢?这个Assinger是一个execNode和窗口的assigner是不一样的,这里主要是为了发送水印的
没错,miniBatch攒一批的实现原理就是通过水印,来作为一批的标识
来具体看看

分为处理时间和事件时间
先看看处理时间
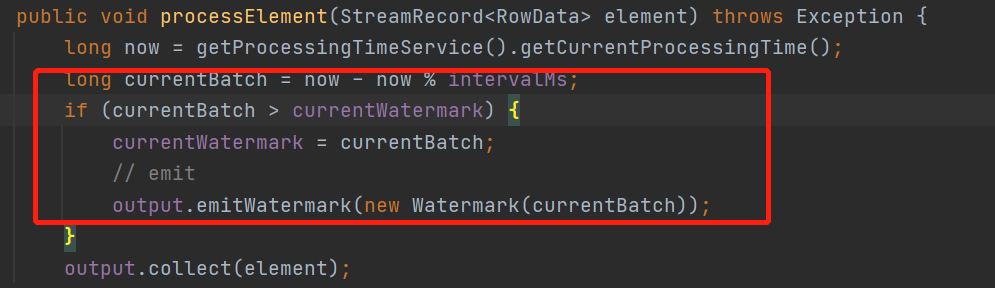
逻辑比较简单,就是当前微批的开始时间大于当前水印,就发送一个当前的微批的开始时间的水印
然后,事件时间的没什么意思,就是水印直接往下游转发了
接着,攒微批已经将完了,来看下具体聚合算子怎么优化微批计算的吧
来看个StreamExecGroupAggregate这个聚合ExecNode的逻辑
既然是execNode来直接看它的translateToPlanInternal()方法
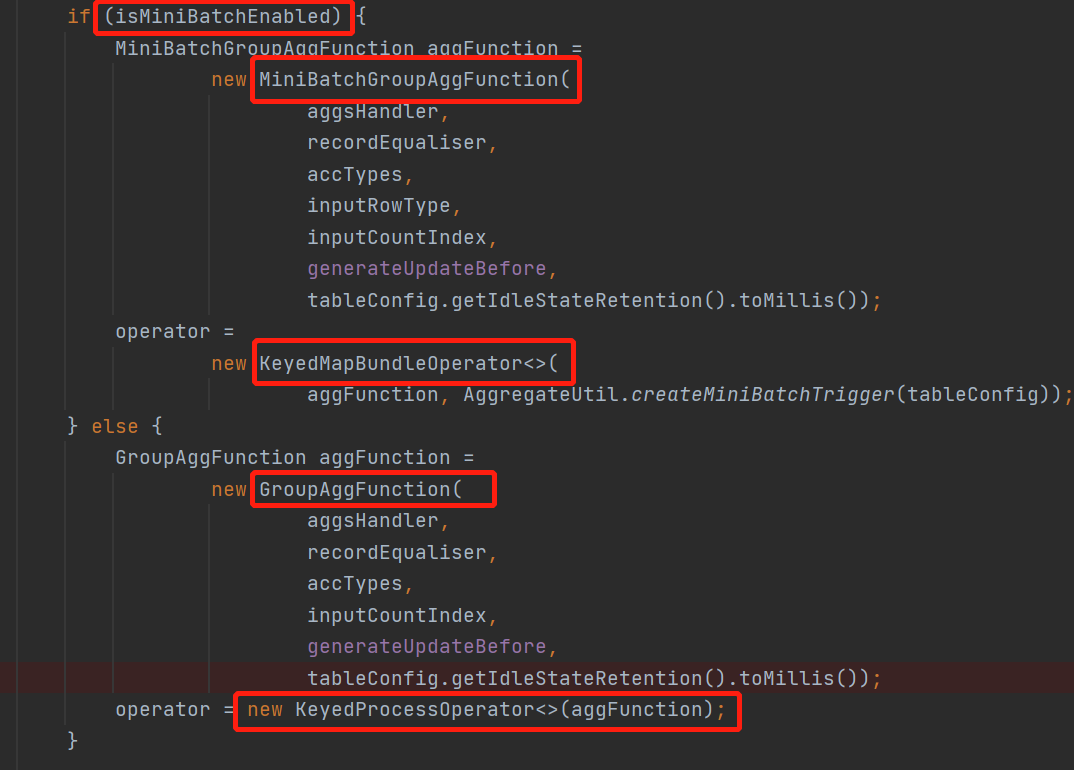
原来是直接在execNode里面做了特殊处理,不过也是,每个算子的优化都不一样也不太好抽象出来
这里还是 先看看不使用微批的时候是怎么处理的,然后来对比一下
没用微批这里是封装成了一个KeyedProcessOperator的算子,里面传的aggFunction直接就是一个KeyedProcessFunction
看下具体处理groupAggFunction
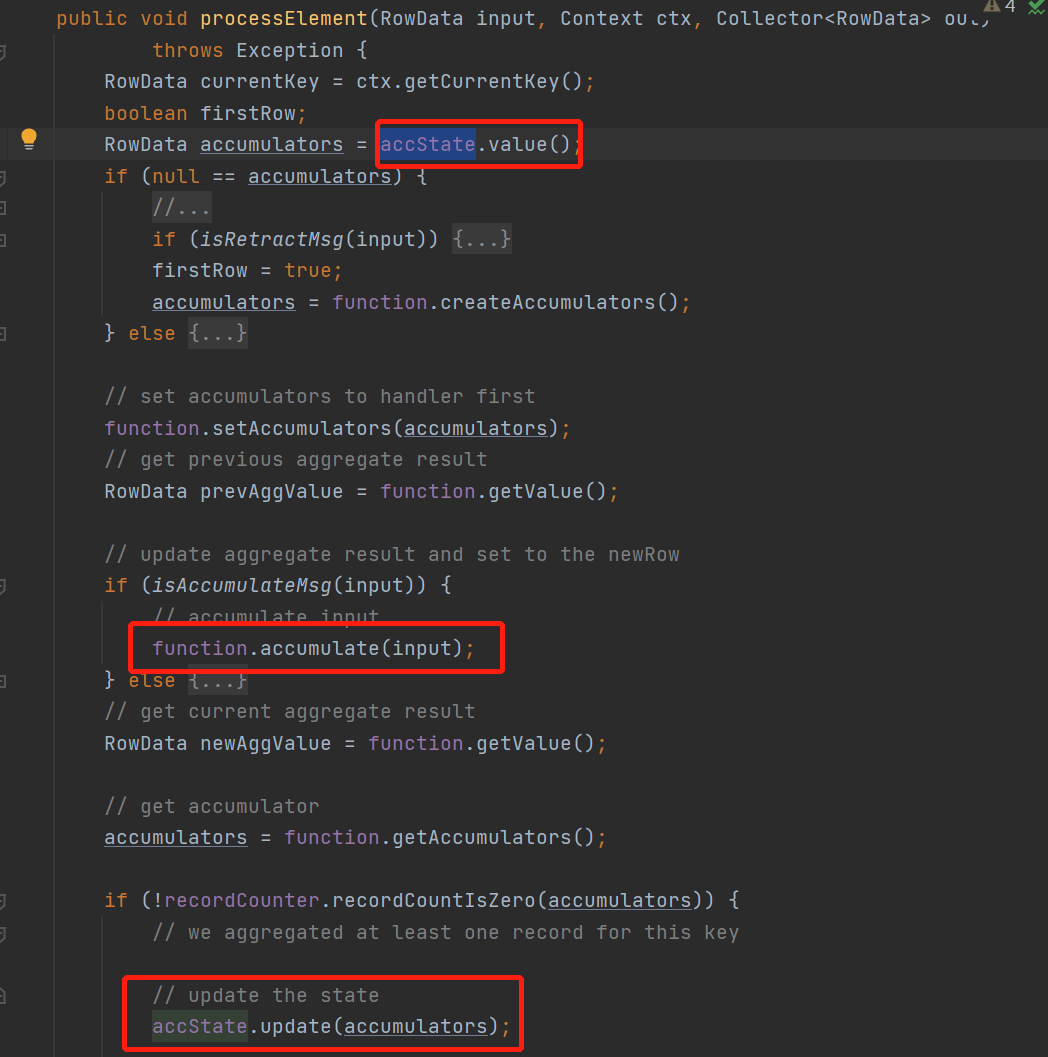
这里没有开minibatch的逻辑比较简单
每来一条数据,先读状态accState是一个valueState然后,调用聚合函数的accumlate来计算,然后用新得到的累加器更新状态
可以看到这样做的问题还是比较大的
第一,每一条数据都要读写状态开销很大
第二,每条数据都要调用计算,有很多虚函数的调用
因此,让我们看看MIniBatch是如何做的吧
回到上面,我们看到MiniBatch是创建的一个KeyedMapBundleOperator,里面的参数是MiniBatchGroupAggFunction
看下KeyedMapBundleOperator
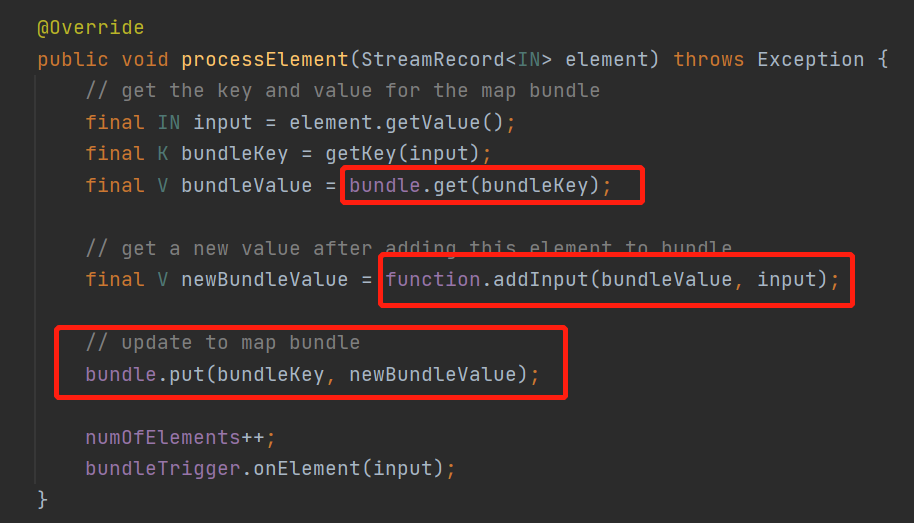
先从一个bundle获取和数据同key的数据,来看下这个bundle是什么

ok,就是一个本地map,然后走addInput()
来看下MiniBatchGroupAggFunction的addInput方法

其实就是把,来的数据加到map对应key的Value是一个list里面去了
最后来看当微批攒够触发onTrigger会走到finishBundle()方法

先从buffer获取每一个key对应的value是一个list
然后读取状态state数据
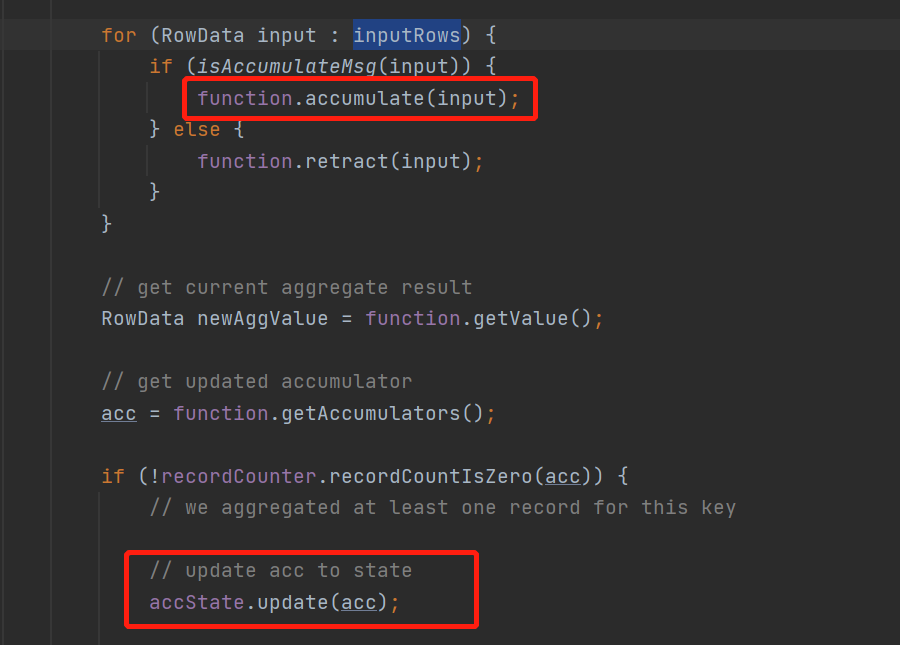
直接for循环遍历微批的数据
然后调用聚合函数的accumulate不停计算
最后将计算好的累加器accumulator存到状态里面去
是不是很简单
这样微批处理就完成了,减少了状态的频繁访问,是一个很不错的优化
Flink sql 之 微批处理与MiniBatchIntervalInferRule (源码分析)的更多相关文章
- Flink sql 之 join 与 StreamPhysicalJoinRule (源码解析)
源码分析基于flink1.14 Join是flink中最常用的操作之一,但是如果滥用的话会有很多的性能问题,了解一下Flink源码的实现原理是非常有必要的 本文的join主要是指flink sql的R ...
- Flink 非对齐Unaligned的checkpoint(源码分析)
本文源码基于flink1.14 在帮助用户排查任务的时候,经常会发现部分task处理的慢,在Exactly once语义时需要等待快照的对齐而白白柱塞的情况 在flink1.11版本引入了非对齐的ch ...
- Flink中watermark为什么选择最小一条(源码分析)
昨天在社区群看到有人问,为什么水印取最小的一条?这里分享一下自己的理解 首先水印一般是设置为:(事件时间 - 指定的值) 这里的作用是解决迟到数据的问题,从源码来看一下它如何解决的 先来看下wind ...
- 从flink-example分析flink组件(1)WordCount batch实战及源码分析
上一章<windows下flink示例程序的执行> 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar),那么我们为什么要使用fli ...
- 【springcloud】1.微服务之springcloud-》eureka源码分析之请叫我灵魂画师。。。
- Flink sql 之 两阶段聚合与 TwoStageOptimizedAggregateRule(源码分析)
本文源码基于flink1.14 上一篇文章分析了<flink的minibatch微批处理>的源码 乘热打铁分析一下两阶段聚合的源码,因为使用两阶段要先开启minibatch,至于为什么后面 ...
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- Flink中Idle停滞流机制(源码分析)
前几天在社区群上,有人问了一个问题 既然上游最小水印会决定窗口触发,那如果我上游其中一条流突然没有了数据,我的窗口还会继续触发吗? 看到这个问题,我蒙了???? 对哈,因为我是选择上游所有流中水印最小 ...
- MyBatis 源码分析 - 插件机制
1.简介 一般情况下,开源框架都会提供插件或其他形式的拓展点,供开发者自行拓展.这样的好处是显而易见的,一是增加了框架的灵活性.二是开发者可以结合实际需求,对框架进行拓展,使其能够更好的工作.以 My ...
随机推荐
- 集合类——Collection、List、Set接口
集合类 Java类集 我们知道数组最大的缺陷就是:长度固定.从jdk1.2开始为了解决数组长度固定的问题,就提供了动态对象数组实现框架--Java类集框架.Java集合类框架其实就是Java针对于数据 ...
- Git上项目代码拉到本地方法
1.先在本地打开workspace文件夹,或者自定义的文件夹,用来保存项目代码的地方. 2.然后登陆GitHub账号,点击复制项目路径 3.在刚才文件夹下空白处点击鼠标右键,打开Git窗口 4.在以下 ...
- soapui pro 5.1.2 的破解方法
Protection-4.6,和scz.key这两个文件能破解5.1.2的SoapUI 的Pro版本,mac 和 windows均可.1.拷贝Protection-4.6.jar到soapui安装的l ...
- 小程序的事件 bindtap bindinput
一.bindtap事件 在wxml文件里绑定: <view class='wel-list' bindtap='TZdown'> <image src="/images/w ...
- 并行Louvain社区检测算法
因为在我最近的科研中需要用到分布式的社区检测(也称为图聚类(graph clustering))算法,专门去查找了相关文献对其进行了学习.下面我们就以这篇论文IPDPS2018的文章[1]为例介绍并行 ...
- <转>企业应用架构 --- 分层
系统架构师-基础到企业应用架构-分层[上篇] 一.前言 大家好,接近一年的时间没有怎么书写博客了,一方面是工作上比较忙,同时生活上也步入正轨,事情比较繁多,目前总算是趋于稳定,可以有时间来完善以前没有 ...
- [BUUCTF]REVERSE——[WUSTCTF2020]level1
[WUSTCTF2020]level1 附件 步骤: 下载下来的附件有两个,output.txt里是一堆数字 64位ida打开第一个附件,检索字符串,发现了flag字样 双击跟进,ctrl+x交叉引用 ...
- 又拿奖了!腾讯云原生数据库TDSQL-C斩获2021PostgreSQL中国最佳数据库产品奖
日前,开源技术盛会PostgresConf.CN & PGconf.Asia2021大会(简称2021 PG亚洲大会)在线上隆重召开,腾讯云作为业内领先的云数据库服务商受邀出席,多位专家深入数 ...
- word文档打钩记录快捷键
先按住键盘上的 Alt 键不放,然后在小键盘区(数字键区)输入 9745 ,最后松开 Alt键.
- powerdesigner 连接数据库
powerdesigner 连接数据库如图: