Spark环境搭建(中)——Hadoop安装
1. 下载Hadoop
1.1 官网下载Hadoop
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz
打开上述链接,进入到下图,可以随意下载一个完整的hadoop-2.9.0版本,如下图所示:
2. 安装Hadoop
把hadoop-2.9.0.tar.gz文件进行操作,分三大步骤:
- 配置前的准备,包括上传到主节点,解压缩并迁移到/opt/app目录,在hadoop目录下创建tmp、name和data目录;
- 配置,包括hadoop-env.sh、yarn-env.sh(前两者为启动文件的JAVA_HOME和PATH配置)、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、Slaves(后面5个文件为核心组件和集群配置),共7个文件需要配置。配置完成需要向另外的集群机器节点分发hadoop程序;
- 启动部署,包括格式化NameNode、启动HDFS、启动YARN。
2.1 准备
2.1.1 上传并解压Hadoop安装包
1. 把hadoop-2.9.0.tar.gz通过Xfpt工具上传到主节点的/opt/uploads目录下

2. 在主节点上解压缩,如果解压缩出来的文件拥有者和用户组不是hadoop,则需要使用sudo chown -R hadoop:hadoop hadoop-2.9.0命令
# cd /opt/uploads/
# tar -zxvf hadoop-2.9.0.tar.gz

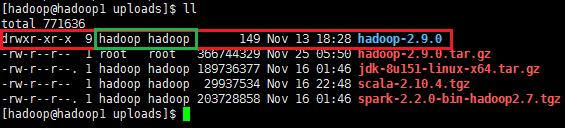
有时解压出来的文件夹,使用命令 ll 查看用户和用户组有可能不是hadoop时,即上图绿框显示,则需要使用如下命令更换为hadoop用户和用户组:
# sudo chown hadoop:hadoop hadoop-2.9.0
3. 把hadoop-2.9.0目录移到/opt/app目录下
# mv hadoop-2.9.0 /opt/app/
# ll /opt/hadoop
2.1.2 在Hadoop目录下创建子目录
以hadoop用户在/opt/app/hadoop-2.9.0目录下创建tmp、name和data目录。tmp为缓存文件,name用于NameNode存放文件,data用于DataNode存放文件
# cd /opt/app/hadoop-2.9.0/
# mkdir tmp && mkdir name && mkdir data
# ll

2.2 配置7大文件
2.2.1 配置hadoop-env.sh
1. 以hadoop用户打开配置文件hadoop-env.sh
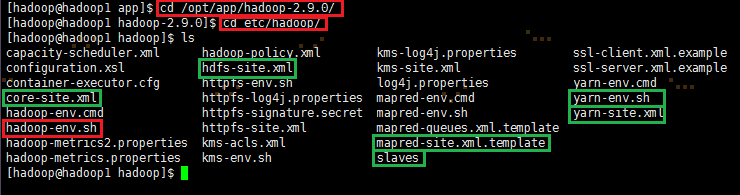
# cd /opt/app/hadoop-2.9.0/etc/hadoop
# vi hadoop-env.sh
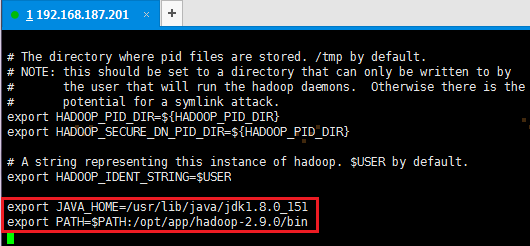
2. 加入配置内容,设置JAVA_HOME和PATH路径
export JAVA_HOME=/usr/lib/java/jdk1.8.0_151
export PATH=$PATH:/opt/app/hadoop-2.9.0/bin
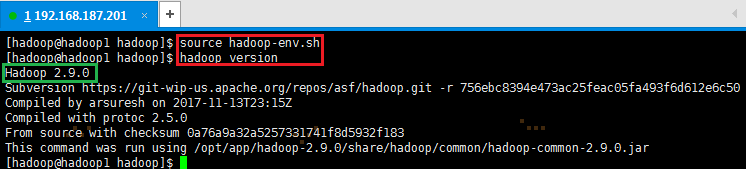
3. 编译配置文件hadoop-env.sh,并确认生效
# source hadoop-env.sh
# hadoop version
2.2.2 配置yarn-env.sh
1. 以hadoop用户在/opt/app/hadoop-2.9.0/etc/hadoop打开配置文件yarn-env.sh
# cd /opt/app/hadoop-2.9.0/etc/hadoop 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# vi yarn-env.sh
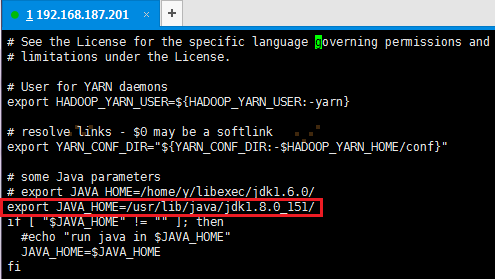
2. 加入配置内容,在如下位置设置JAVA_HOME路径
export JAVA_HOME=/usr/lib/java/jdk1.8.0_151
3. 编译配置文件yarn-env.sh,并确认生效
source yarn-env.sh
2.2.3 配置core-site.xml
1. 以hadoop用户,使用如下命令打开core-site.xml配置文件
# cd /opt/app/hadoop-2.9.0/etc/hadoop/ 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# vi core-site.xml
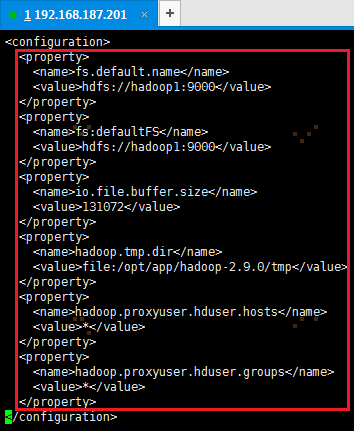
2. 在配置文件中,按照如下内容进行配置
配置的点有fs默认名字、默认FS、IO操作的文件缓冲区大小、tmp目录、代理用户hosts、代理用户组,共6点。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>fs:defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/app/hadoop-2.9.0/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
2.2.4 配置hdfs-site.xml
1. 使用如下命令打开hdfs-site.xml配置文件
# cd /opt/app/hadoop-2.9.0/etc/hadoop/ 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# vi hdfs-site.xml

2. 在配置文件中,按照如下内容进行配置
hdfs-site.xml配置的点有namenode的secondary、name目录、data目录、备份数目、开启webhdfs,共5点
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/app/hadoop-2.9.0/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/app/hadoop-2.9.0/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>

【注意】:namenode的hdfs-site.xml是必须将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的。
2.2.5 配置mapred-site.xml
1. 默认情况下不存在mapred-site.xml文件,可以从模板拷贝一份。然后,使用vi命令打开mapred-site.xml配置文件
# cd /opt/app/hadoop-2.9.0/etc/hadoop/ 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# cp mapred-site.xml.template mapred-site.xml
# vi hdfs-site.xml
2. 在配置文件中,按照如下内容进行配置
mapred-site.xml配置的点有mapreduce的框架、jobhistory的地址、jobhistory的webapp地址,共3点。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>

2.2.6 配置yarn-site.xml
1. 使用如下命令打开yarn-site.xml配置文件
# cd /opt/app/hadoop-2.9.0/etc/hadoop/ 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# vi hdfs-site.xml
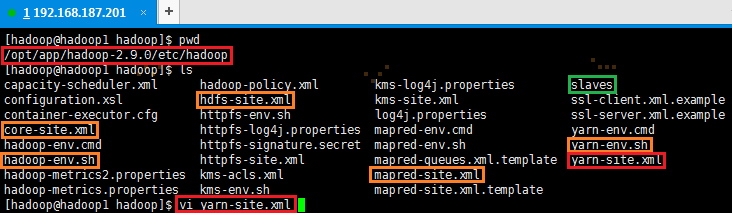
2. 在配置文件中,按照如下内容进行配置
yarn-site.xml配置的点有①nodemanager的aux-services及其类;②resourcemanager的地址、其sheduler地址、其resource-tracker地址、其admin地址以及webapp地址,共7点。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>
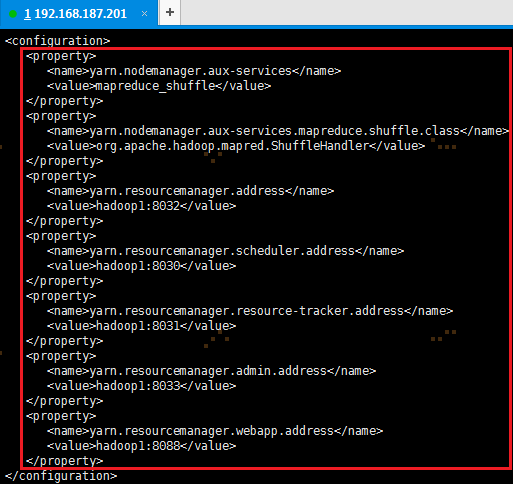
2.2.7 配置Slaves文件
1. 使用# vi slaves打开从节点配置文件
# cd /opt/app/hadoop-2.9.0/etc/hadoop/ 如果不在/opt/app/hadoop-2.9.0/etc/hadoop目录下,则使用该命令
# vi slaves

2. 在配置文件中加入如下内容:
hadoop1
hadoop2
hadoop3
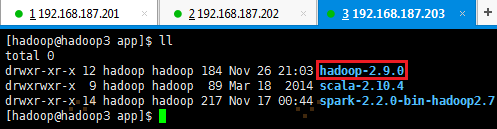
2.2.8 向各节点分发Hadoop程序
1. 在hadoop1机器/opt/app/hadoop-2.9.0使用如下命令把hadoop文件夹复制到hadoop2和hadoop3机器
# cd /opt/app
# scp -r hadoop-2.9.0 hadoop@hadoop2:/opt/app/
# scp -r hadoop-2.9.0 hadoop@hadoop3:/opt/app/


2. 在从节点查看是否复制成功

2.3 启动部署
启动部署,包括格式化NameNode、启动HDFS、启动YARN。
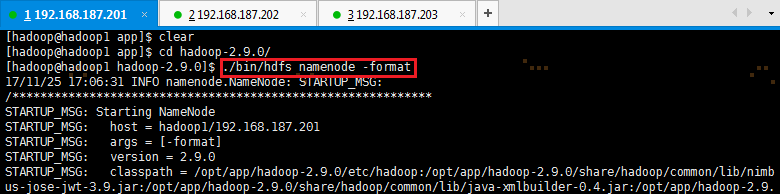
2.3.1 格式化NameNode
# cd /opt/app/hadoop-2.9.0
# ./bin/hdfs namenode -format

2.3.2 启动HDFS
1. 使用如下命令启动HDFS:
# cd /opt/app/hadop-2.9.0/sbin 如果不在/opt/app/hadoop-2.9.0/sbin目录下,则使用该命令
# ./start-dfs.sh

2. 验证HDFS启动
此时在hadoop1上面运行的进程有:NameNode、SecondaryNameNode和DataNode
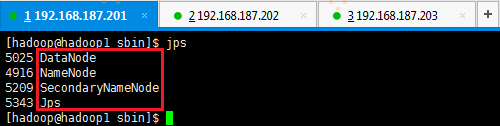
hadoop2和hadoop3上面运行的进程有:NameNode和DataNode


【注意】:jps命令出现—— xxxx--process information unavailable解决方法(有可能出现)
解决方法:根目录/tmp中找到hsperfdata_前缀的目录,并找出PID(即xxxx)对应的文件并且删除即可。如果/tmp文件不重要的话,全部删除也行。
2.3.3 启动YARN
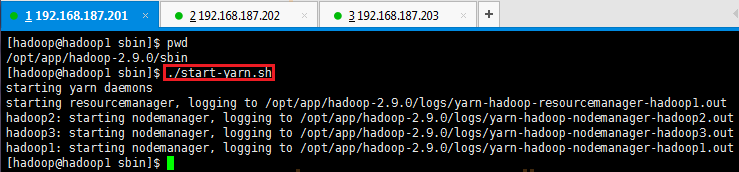
1. 使用如下命令启动YARN
# cd /opt/app/hadoop-2.9.0/sbin 如果不在/opt/app/hadoop-2.9.0/sbin目录下,则使用该命令
# ./start-yarn.sh
2. 验证YARN启动
此时在hadoop1上运行的进程有:NameNode、SecondaryNameNode、DataNode、NodeManager和ResourceManager
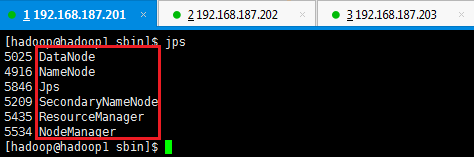
hadoop2和hadoop3上面运行的进程有:NameNode、DataNode和NodeManager


参考资料:
http://www.ttlsa.com/linux/jps-process-information-unavailable/ jps命令出现xxxx--process information unavailable解决方法
http://www.cnblogs.com/shishanyuan/p/4701646.html 石山园大神的讲解

Spark环境搭建(中)——Hadoop安装的更多相关文章
- Spark入门到精通--(第八节)环境搭建(Hadoop搭建)
上一节把Centos的集群免密码ssh登陆搭建完成,这一节主要讲一下Hadoop的环境搭建. Hadoop下载安装 下载官网的Hadoop 2.4.1的软件包.http://hadoop.apache ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- LNMP环境搭建:Nginx安装、测试与域名配置
Nginx作为一款优秀的Web Server软件同时也是一款优秀的负载均衡或前端反向代理.缓存服务软件 2.编译安装Nginx (1)安装Nginx依赖函数库pcre pcre为“perl兼容正则表达 ...
- Tesseract环境搭建及编译安装
Tesseract环境搭建及编译安装 Tesseract源码都是C++源码:对于不咋会C++的人来说,这真是...虽然说语言有相通性,但是...哎!!!!! 分享出来,也希望对大家有所帮助. 环境:w ...
- Python环境搭建和pycharm安装
Python环境搭建和pycharm安装 本人安装环境为Windows10系统,下载的Python版本为3.4社区版本,可参考 1.下载Python3.4版本 官网:https://www.pytho ...
- LNMP环境搭建之php安装,wordpress博客搭建
LNMP环境搭建之php安装,wordpress博客搭建 一.介绍: 1.什么是CGI CGI全称是"通用网关接口"(Common Gateway Interface),HTTP服 ...
- Mybatis环境搭建中的案例分析 及 如果自己编写DAO接口的实现类
Mybatis环境搭建中的案例分析public static void main (String[] args) throws Exception { //读配置文件 //第一个: 使用类加载器,只能 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- 如何在MQ中实现支持任意延迟的消息?
什么是定时消息和延迟消息? 定时消息:Producer 将消息发送到 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消 ...
- java应用的jar包多合一
之前开发的java程序由于依赖比较多的jar包,启动命令为" java -classpath .:lib/*.jar 主类名",这种启动方式需要指定类路径.入口类名称,并存在jar ...
- css3整理-方便查询使用
最近详细地研究了CSS3的相关内容,并整理了这个文档,方便以后查询使用,分享给大家. 案例代码大家可以下载参考下:https://gitee.com/LIULIULIU8/CSS3 1.边框属性bor ...
- springMVC(6)---处理模型数据
springMVC(6)---处理模型数据 之前一篇博客,写个怎么获取前段数据:springMVC(2)---获取前段数据,这篇文章写怎么从后端往前端传入数据. 模型数据类型 ...
- Spring加载XML机制
转载自跳刀的兔子 http://www.cnblogs.com/shipengzhi/articles/3029872.html 加载文件顺序 情形一:使用classpath加载且不含通配符 这是 ...
- Excel数据导入至Dataset中
public static DataSet ExcelToDataSet(string ppfilenameurl,string pptable) { string strConn = "P ...
- webstorm方向键与电脑快捷键冲突
1.桌面上,单击鼠标右键,选择"图形属性" 2.单击"选项和支持" 3.在图示框框中,修改电脑上的快捷键
- CSS制作波浪线
建议先去了解清楚了径向渐变,线性渐变的用法先 这个作者的css制作波浪线讲解很不错额:https://www.jianshu.com/p/8570433e3669不理解的可以看看这个链接的额 可以去菜 ...
- 我的Python学习笔记(二):浅拷贝和深拷贝
在Python中,对象赋值,拷贝(浅拷贝和深拷贝)之间是有差异的,我们通过下列代码来介绍其区别 一.对象赋值 对象赋值不会复制对象,它只会复制一个对象引用,不会开辟新的内存空间 如下例所示,将test ...
- Maven 环境配置
1. 解压maven 2. 配置MAVEN_HOME环境变量 MAVEN_HOME D:\maven\apache-maven-3.0.5-bin\apache-maven-3.0.5 path ...