python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了。
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
response = requests.get('http://www.baidu.com')
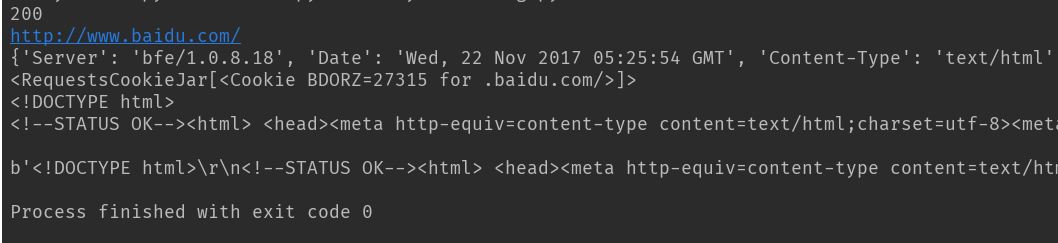
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
运行结果:
状态码:200
url:www.baidu.com
headers信息
各种请求方式:
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
基本的get请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
结果

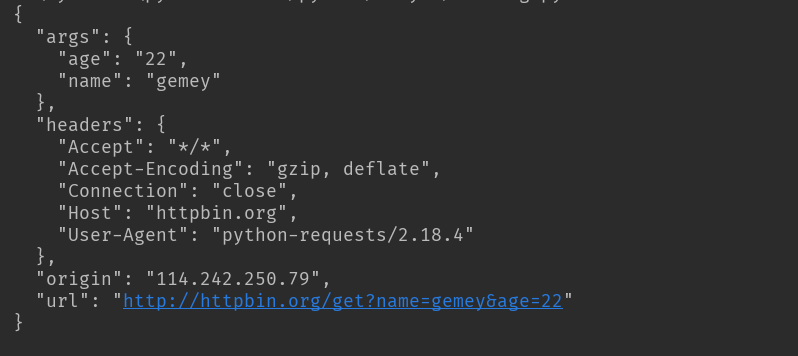
带参数的GET请求:
第一种直接将参数放在url内
import requests response = requests.get(http://httpbin.org/get?name=gemey&age=22)
print(response.text)
结果
另一种先将参数填写在dict中,发起请求时params参数指定为dict
import requests
data = {
'name': 'tom',
'age': 20
}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text)
结果同上
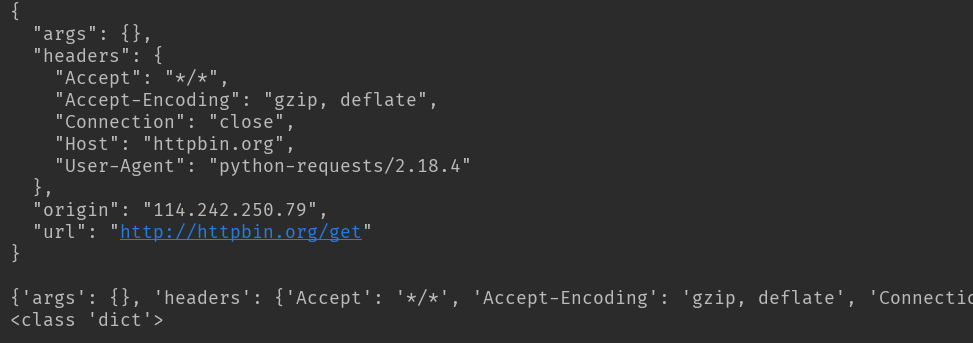
解析json
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))
结果
简单保存一个二进制文件
二进制内容为response.content
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为你的请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
使用代理
同添加headers方法,代理参数也要是一个dict
这里使用requests库爬取了IP代理网站的IP与端口和类型
因为是免费的,使用的代理地址很快就失效了。
import requests
import re def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray) if __name__ == '__main__':
url = 'http://www.kuaidaili.com/free/'
get_ipport(get_html(url))
结果:

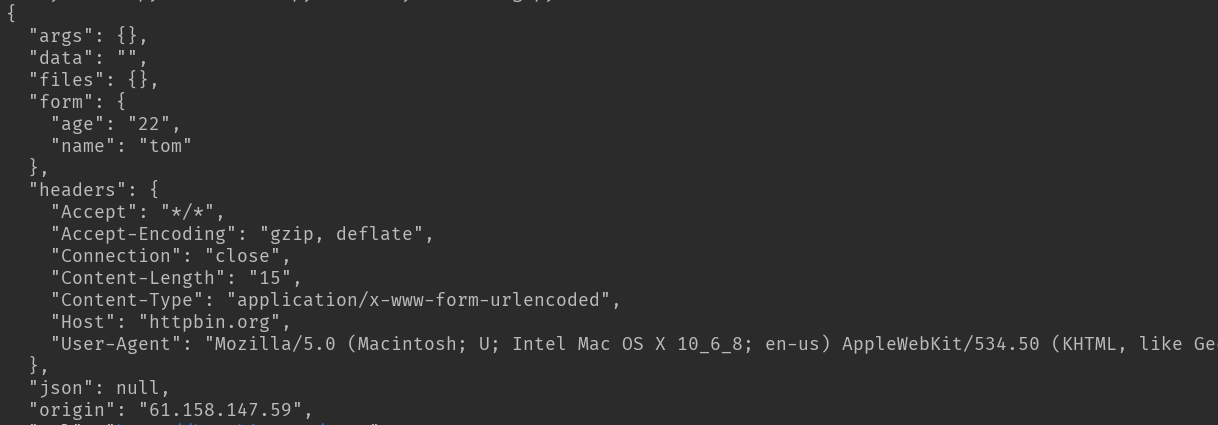
基本POST请求:
import requests
data = {'name':'tom','age':''}
response = requests.post('http://httpbin.org/post', data=data)
获取cookie
#获取cookie
import requests response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)
结果:

会话维持
import requests session = requests.Session()
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
结果:

证书验证设置
import requests
from requests.packages import urllib3 urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code) 打印结果:200
超时异常捕获
import requests
from requests.exceptions import ReadTimeout try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
在你不确定会发生什么错误时,尽量使用try...except来捕获异常
所有的requests exception:
Exceptions
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
python爬虫---requests库的用法的更多相关文章
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- Python爬虫--Requests库
Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,requests是python实现的最简单易用的HTTP库, ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- Python爬虫---requests库快速上手
一.requests库简介 requests是Python的一个HTTP相关的库 requests安装: pip install requests 二.GET请求 import requests # ...
- python爬虫——requests库使用代理
在看这篇文章之前,需要大家掌握的知识技能: python基础 html基础 http状态码 让我们看看这篇文章中有哪些知识点: get方法 post方法 header参数,模拟用户 data参数,提交 ...
- Python 爬虫-Requests库入门
2017-07-25 10:38:30 response = requests.get(url, params=None, **kwargs) url : 拟获取页面的url链接∙ params : ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
随机推荐
- Latex: extra alignment tab has been changed to cr
参考: Error: extra alignment tab has been changed to \cr Latex: extra alignment tab has been changed t ...
- Vs Code搭建 TypeScript 开发环境
一.npm install -g typescript 全局安装TypeScript 二.使用Vs Code打开已创建的文件夹,使用快捷键Ctrl+~启动终端输入命令 tsc --init 创建t ...
- IIS发布静态页面配置
第一步:按照正常网站发布添加网站: 第二步:修改该网站的默认文档: 第三步:添加默认文档,把静态页的名称添加进去: 第四步:重启网站,浏览:
- 【BZOJ】1830: [AHOI2008]Y型项链
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1830 直接枚举目标串是什么,目标串一定是三个字符串的某一个前缀(注意可能为空),然后判断一 ...
- 获取指定tag的代码
git checkout v1.0.3 再使用ls查看就可以了
- String,StringBuilder区别,一个是常量,一个是可变量
String str="这就是爱的呼唤,这就是爱的奉献!!"; //这个str是不可变的字符串序列,要变会生成新的字符串,原字符串不变,是常量 StringBuilder sBui ...
- 网页常见单位: px em pt % rem vw、vh、vmin、vmax , rem 使用
1.网页常见单位: px em pt vw\vh rem 1.1 px单位名称为像素,相对长度单位,像素(px)是相对于显示器屏幕分辨率而言 (最终解析单位) em单位名称为相对长度 ...
- 牛客网NOIP赛前集训营-普及组(第一场)C 括号
括号 思路: dp 状态:dp[i][j]表示到i位置为止未匹配的 '(' 个数为j的方案数 状态转移: 如果s[i] == '(' dp[i][j] = dp[i-1][j] + dp[i-1][j ...
- python paramiko 模块简单介绍
背景,公司的很多服务包括数据库访问都需要通过跳板机访问,为日常工作及使用带来了麻烦,特别数python直接操作数据更是麻烦了,所以一直想实现python 通过跳板机访问数据库的操作. 首先了解到了 p ...
- Linux-Ubuntu16.0.4相关命令
1.更新软件源 sudo apt-get update 2.shell命令 基本格式:命令 [-选项] [-命令参数] ls #查看当前文件夹下的文件 ls -l XXXX #查看XXXX文件夹下的 ...