python爬虫——requests库使用代理
在看这篇文章之前,需要大家掌握的知识技能:
- python基础
- html基础
- http状态码
让我们看看这篇文章中有哪些知识点:
- get方法
- post方法
- header参数,模拟用户
- data参数,提交数据
- proxies参数,使用代理
- 进阶学习
安装上requests库
pip install requests
先来看下帮助文档,看看requests的介绍,用python自带的help命令
import requests
help(requests)
output:
Help on package requests: NAME
requests DESCRIPTION
Requests HTTP Library
~~~~~~~~~~~~~~~~~~~~~ Requests is an HTTP library, written in Python, for human beings. Basic GET
usage: >>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True ... or POST: >>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('https://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
} The other HTTP methods are supported - see `requests.api`. Full documentation
is at <http://python-requests.org>. :copyright: (c) 2017 by Kenneth Reitz.
:license: Apache 2.0, see LICENSE for more details.
这里解释下,requests库是由python编写的对人类友好的http库,并且举例了GET与POST的方法。
GET方法
好的,那我们自己来测试下,就以请求百度为例吧,,,(谁让百度这么耐抗的)
import requests
r = requests.get('https://www.baidu.com')
print(r.status_code) #打印返回的http code
print(r.text) #打印返回结果的text
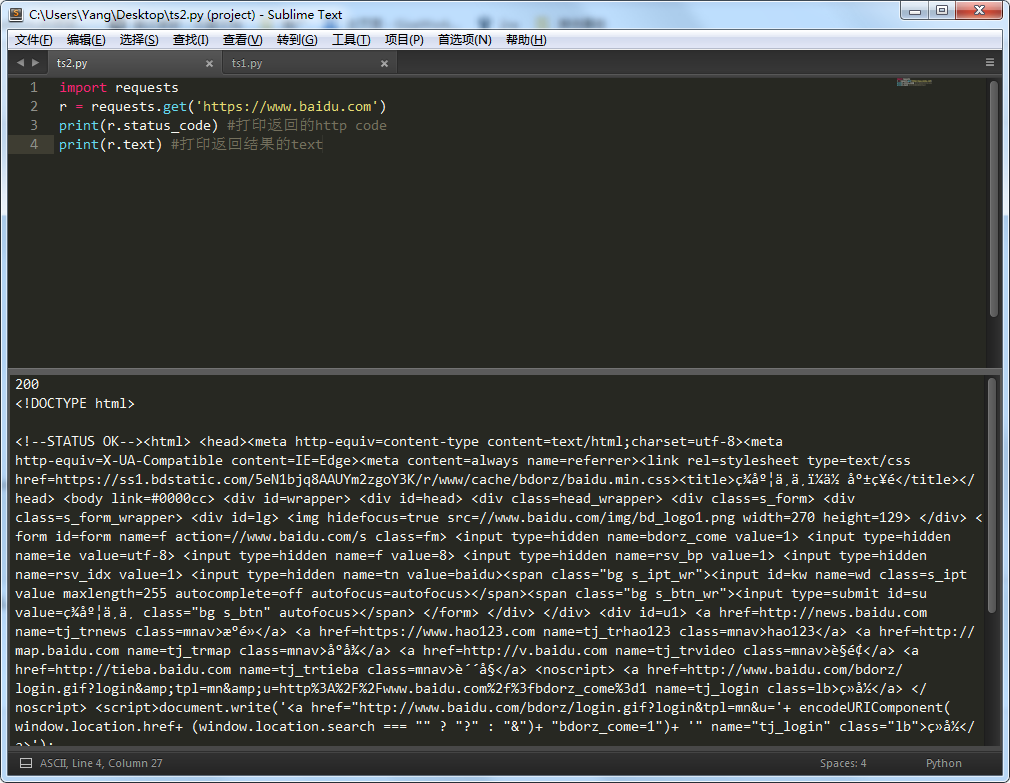
方便点,截了个图给大家看,返回的code是200,说明请求正常拉回网页了。
看下返回的text,有点不对头,少了一些html标签,最起码百度两个字得有吧。嗯,这是什么原因,,,
相信有些同学已经想到了,是没有真实模拟用户的请求,你去爬数据,还不模拟用户请求,那肯定限制你啊。这个时候需要加一个header参数来搞定,至少要加一个user-agent吧。好,那咋们去找一个ua吧。别百度了,自己动手,丰衣足食。教大家一个办法,用谷歌或者火狐的开发者工具。
谷歌浏览器的开发者工具
打开新标签 —— 按F12——访问下百度——找到NetWork——随便点开一个——往下翻——看到ua了吧,复制上。

import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://www.baidu.com', headers=headers)
print(r.status_code)
print(r.text)
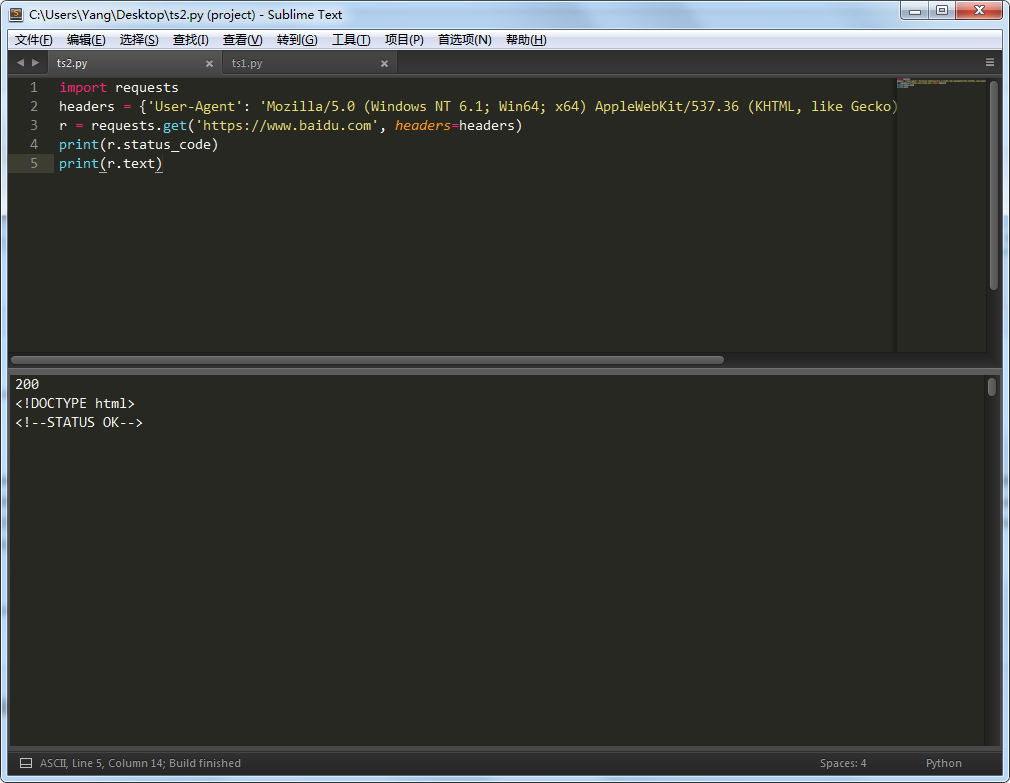
嗯~~~数据有点多,往下翻翻,这下就正常了嘛,数据都有了。。。PS:不信?可以自己输出一个html文件,浏览器打开看看呗
POST方法
只需要把get改成post就好了
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.post('https://www.baidu.com', headers=headers)
print(r.status_code)
print(r.text)
运行下试试看。一般post都是用来提交表单信息的,嗯,这里找一个能提交数据的url,去post下。
用我自己写的接口(PS:django写的,挺方便),大家复制过去就好了。注意看代码,data是要post的数据,post方法里加了一个data参数。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# post的数据
data = {"info": "biu~~~ send post request"}
r = requests.post('http://dev.kdlapi.com/testproxy', headers=headers, data=data) #加一个data参数
print(r.status_code)
print(r.text)
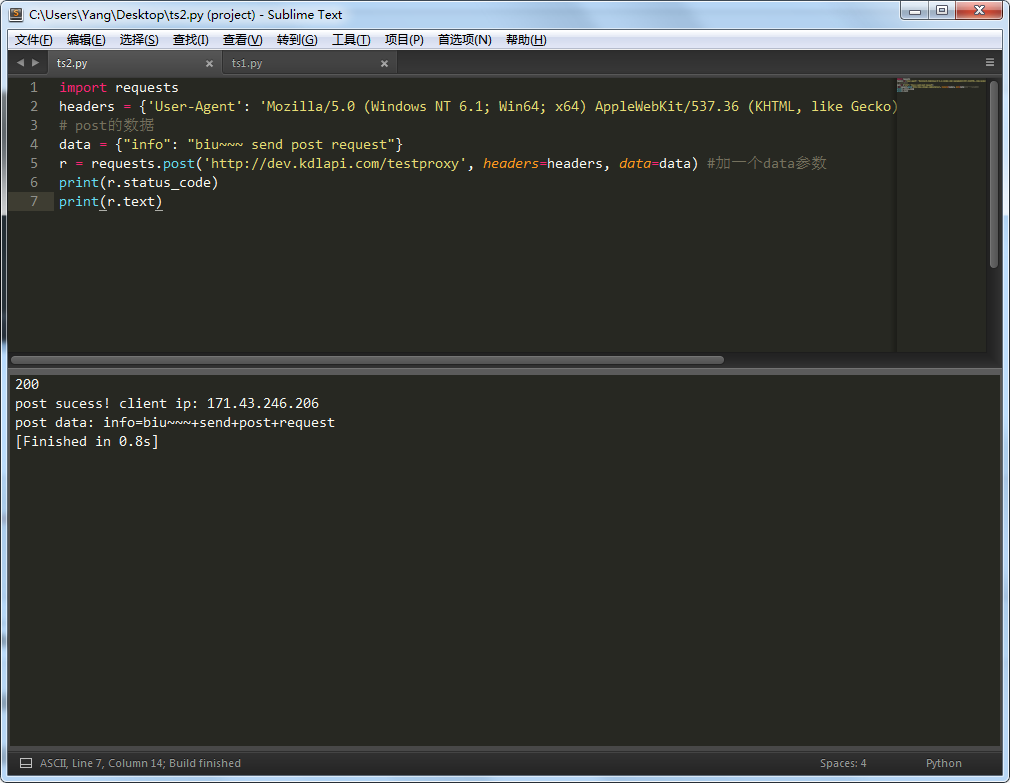
截个图给大家看下,http code 200,body信息说的post成功,并且返回的了我自己的IP信息以及post的数据
使用代理
为什么用代理?一般网站都有屏蔽的限制策略,用自己的IP去爬,被封了那该网站就访问不了,这时候就得用代理IP来解决问题了。封吧,反正封的不是本机IP,封的代理IP。
既然使用代理,得先找一个代理IP。PS:自己写个代理服务器太麻烦了,关键是我也不会写啊,,,哈哈哈
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# post的数据
data = {"info": "biu~~~ send post request"}
# 代理信息,由快代理赞助
proxy = '115.203.28.25:16584'
proxies = {
"http": "http://%(proxy)s/" % {'proxy': proxy},
"https": "http://%(proxy)s/" % {'proxy': proxy}
}
r = requests.post('http://dev.kdlapi.com/testproxy', headers=headers, data=data, proxies=proxies) #加一个proxies参数
print(r.status_code)
print(r.text)
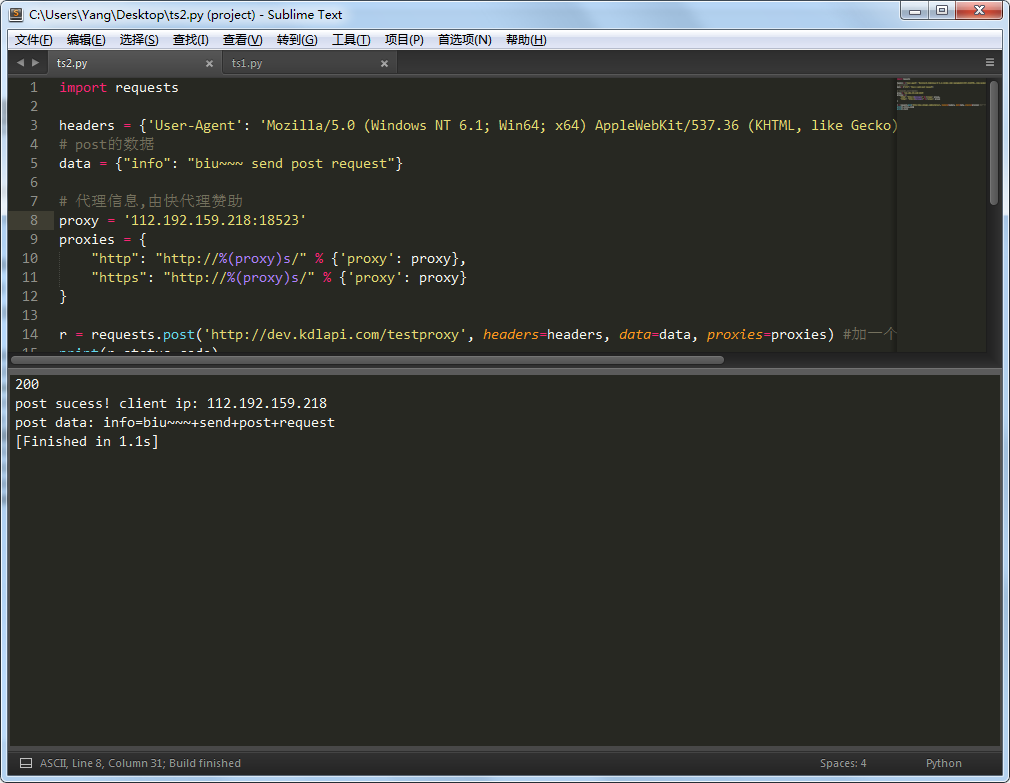
主要方法里加个proxies参数,这就用上代理IP了。
进阶学习
python爬虫——requests库使用代理的更多相关文章
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下 ...
- Python爬虫---requests库快速上手
一.requests库简介 requests是Python的一个HTTP相关的库 requests安装: pip install requests 二.GET请求 import requests # ...
- Python爬虫--Requests库
Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,requests是python实现的最简单易用的HTTP库, ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- Python 爬虫-Requests库入门
2017-07-25 10:38:30 response = requests.get(url, params=None, **kwargs) url : 拟获取页面的url链接∙ params : ...
- 解决python的requests库在使用过代理后出现拒绝连接的问题
在使用过代理后,调用python的requests库出现拒绝连接的异常 问题 在windows10环境下,在使用代理(VPN)后.如果在python中调用requests库来地址访问时,有时会出现这样 ...
- python中requests库使用方法详解
目录 python中requests库使用方法详解 官方文档 什么是Requests 安装Requests库 基本的GET请求 带参数的GET请求 解析json 添加headers 基本POST请求 ...
随机推荐
- P1093 铺地毯
题目描述 为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯.一共有 \(n\) 张地毯,编号从 \(1\) 到 \(n\) .现在将这些地毯按 ...
- C# 简单读取文件
本文告诉大家如何使用最少的代码把一个文件读取二进制,读取为字符串 现在写了一些代码,想使用最少代码来写简单的读文件,所以我就写了这个文章 读取文件为二进制 private byte[] ReadFil ...
- JavaSE基础知识---常用对象API之String类
一.String类 Java中用String类对字符串进行了对象的封装,这样的好处在于对象封装后可以定义N多属性和行为,就可以对字符串这种常见的数据进行方便的操作. 格式:(1)String s1 = ...
- ABP在MultipleDbContext也就是多库的场景下发布后异常“Could not find content root folder”问题处理
ABP多库支持 ABP支持多库的方案在abp的案例中aspnetboilerplate-samples中给了现成的demo,其中MultipleDbContextDemo是EF的相关针对dotnet的 ...
- 【Repo】repo sync:error.GitError: cannot initialize work tree
1.Error Fetching projects: 100% (725/725), done. Checking out files: 100% (4605/4605), done.out file ...
- boostrap-非常好用但是容易让人忽略的地方【3】:clearfix
代码 显示结果 代码 结果
- 西游记之孙悟空三打白骨精(IMAX)
短评:看了20分钟就有玩手机的冲动.剧情还差点意思,不能达到吸引人目不转睛的程度
- C++重载、覆盖与隐藏——转载
http://www.cnblogs.com/qlee/archive/2011/07/04/2097055.html 成员函数的重载.覆盖与隐藏成员函数的重载.覆盖(override)与隐藏很容易混 ...
- eclipse中竖行选择代码的快捷键
Alt+Shift+A (竖行选择代码)
- 【题解】P5462 X龙珠
[题解]P5462 X龙珠 赛题 #B: P5462 X龙珠 | 满分: 100分 发一个set做法 维护两个set,一个按照顺序排序,一个按照值排序. 每次从大往小取,问题就变成了判断这个最大值后面 ...