python中RabbitMQ的使用(工作队列)
消息可以理解为任务,消息发送者可以看成任务派送者(sender),消息接收者可以看成工作者(worker)。
当工作者接收到一个任务,还没完任务时分配者又发一个任务,此时需要多个工作者来共同处理这些任务。
任务分派结构图如下:
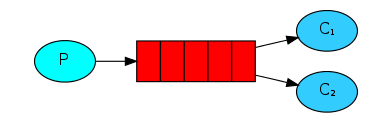
注:此时有一个任务派送人P,两个工作接收者C1和C2。
现在我们来模拟该情况:
1.首先打开三个终端:


2.分别在前两个终端运行receive1.py

3.在第三个终端多次运行send1.py

此时将会轮流向worker1和worker2分派任务。
问题:
在以上任务分配和完成情况中,有几个问题将会产生:
1.工作者任务是否完成?
2.工作者挂掉后,如何防止未完成的任务丢失,并且如何处理这些任务?
3.RabbitMQ自身出现问题,此时如何防止任务丢失?
4.任务有轻重之分,如何实现公平调度?
方案:
1.消息确认(Message acknowledgment)
当任务完成后,工作者(receiver)将消息反馈给RabbitMQ:
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
#停顿5秒,方便ctrl+c退出
time.sleep(5)
print " [x] Done"
#当工作者完成任务后,会反馈给rabbitmq
ch.basic_ack(delivery_tag=method.delivery_tag)
2.保留任务(no_ack=False)
当工作者挂掉后,防止任务丢失:
# 去除no_ack=True参数或者设置为False后可以实现
# 一个工作者ctrl+c退出后,正在执行的任务也不会丢失,rabbitmq会将任务重新分配给其他工作者。
channel.basic_consume(callback, queue='task_queue', no_ack=False)
3.消息持久化存储(Message durability)
声明持久化存储:
# durable=True即声明持久化存储
channel.queue_declare(queue='task_queue', durable=True)
在发送任务时,用delivery_mode=2来标记任务为持久化存储:
# 用delivery_mode=2来标记任务为持久化存储:
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2,
))
4.公平调度(Fair dispatch)
使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,即只有工作者完成任务之后,才会再次接收到任务
channel.basic_qos(prefetch_count=1)
完整代码如下:
receive1.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pika
import time hostname = '192.168.1.133'
parameters = pika.ConnectionParameters(hostname)
connection = pika.BlockingConnection(parameters) # 创建通道
channel = connection.channel()
# durable=True后将任务持久化存储,防止任务丢失
channel.queue_declare(queue='task_queue', durable=True) # ch.basic_ack为当工作者完成任务后,会反馈给rabbitmq
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep(5)
print " [x] Done"
ch.basic_ack(delivery_tag=method.delivery_tag) # basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,
# 即只有工作者完成任务之后,才会再次接收到任务。
channel.basic_qos(prefetch_count=1) 27 # 去除no_ack=True参数或者设置为False后可以实现
28 # 一个工作者ctrl+c退出后,正在执行的任务也不会丢失,rabbitmq会将任务重新分配给其他工作者。
channel.basic_consume(callback, queue='task_queue', no_ack=False)
# 开始接收信息,按ctrl+c退出
print ' [*] Waiting for messages. To exit press CTRL+C'
channel.start_consuming()
send1.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pika
import random hostname = '192.168.1.133'
parameters = pika.ConnectionParameters(hostname)
connection = pika.BlockingConnection(parameters) # 创建通道
channel = connection.channel()
# 如果rabbitmq自身挂掉的话,那么任务会丢失。所以需要将任务持久化存储起来,声明持久化存储:
channel.queue_declare(queue='task_queue', durable=True) number = random.randint(1, 1000)
message = 'hello world:%s' % number # 在发送任务的时候,用delivery_mode=2来标记任务为持久化存储:
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2,
))
print " [x] Sent %r" % (message,)
connection.close()
示例如下:
首先启动三个终端,两个先执行receive1.py,第三个多次执行rend1.py:
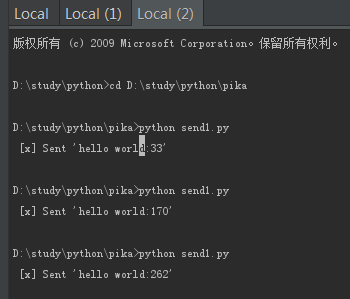
终端3:
此时分配三个任务,33分配给worker1,170分配给worker2,262分配给worker1
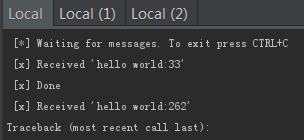
终端1:
worker1完成任务33后,开始任务262,我们在任务完成前使用(CRTL+C)使worker1挂掉
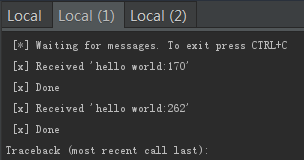
终端2:
worker2完成任务170,本来没有任务,但是worker1挂掉,此时接收他的任务262
python中RabbitMQ的使用(工作队列)的更多相关文章
- python中RabbitMQ的使用(安装和简单教程)
1,简介 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从"生产者"接收消息 ...
- python中RabbitMQ的使用(远程过程调用RPC)
在RabbitMQ消息队列中,往往接收者.发送者不止是一个身份.例如接接收者收到消息并且需要返回给发送者. 此时接收者.发送者的身份不再固定! 我们来模拟该情形: 假设有客户端client,服务端se ...
- python中RabbitMQ的使用(交换机,广播形式)
简介 如果要让每个接收端都能收到消息,此时需要将消息广播出去,需要使用交换机. 工作原理 消息发送端先将消息发送给交换机,交换机再将消息发送到绑定的消息队列,而后每个接收端都能从各自的消息队列里接收到 ...
- python中RabbitMQ的使用(路由键模糊匹配)
路由键模糊匹配 使用正则表达式进行匹配.其中“#”表示所有.全部的意思:“*”只匹配到一个词. 匹配规则: 路由键:routings = [ 'happy.work', 'happy.life' , ...
- python中RabbitMQ的使用(路由键)
1.简介 当我们希望每个接收端接收各自希望的消息时,我们可以使用路由键,此时交换机的类型为direct. 2.工作原理 每个接收端的消息队列在绑定交换机的时候,可以设定相应的路由键. 发送端通过交换机 ...
- rabbitmq(中间消息代理)在python中的使用
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法.但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程.进程队列便不再适用了:此种情况便只能使用socke ...
- 十一天 python操作rabbitmq、redis
1.启动rabbimq.mysql 在""运行""里输入services.msc,找到rabbimq.mysql启动即可 2.启动redis 管理员进入cmd, ...
- python操作rabbitmq、redis
1.启动rabbimq.mysql 在“”运行“”里输入services.msc,找到rabbimq.mysql启动即可 2.启动redis 管理员进入cmd,进入redis所在目录,执行redis- ...
- Python操作RabbitMQ
RabbitMQ介绍 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消 ...
随机推荐
- 【使用指南】WijmoJS 前端开发工具包
为方便广大前端开发人员更好的使用 WijmoJS 前端开发工具包,葡萄城专门推出了 WijmoJS 使用指南,该指南详细地介绍了如何把 WijmoJS 各种强大的功能应用到您自己的 Web 项目中,助 ...
- java核心问题总结
Java 核心概念 equals 与 hashCode 的异同点在哪里?Java 的集合中又是如何使用它们的. Math.Integer.Double等这些封装类在使用equals()方法时,已经覆盖 ...
- 轮播图(jQuery)
效果图: -----------------------------------------html------------------------------------------------- ...
- [从零开始搭网站七]CentOS上安装Mysql
点击下面连接查看从零开始搭网站全系列 从零开始搭网站 通过前面6章,我们买好了服务器,配置了服务器连接,服务器上配置了JDK和Tomcat,准备了域名(这个我没教,自己去阿里/百度/腾讯买,买东西我相 ...
- ERP系统知识笔记
中心思想: 1.不管哪一家的ERP系统,都是以“平衡供需”为目的.以计划为中心思想的,并将各管理职能作紧密的集成 2.手工管理方式下,对库存量的掌握是不完整的.手工方式下,我们的数据只有现存量,无法记 ...
- 关于Oracle 12C pdb用户无法登录的问题
新装了oracle12c,对新的CDB和PDB用户如何登录一直一头雾水,经过一晚上的查找,终于解决. sqlplus /nolog -> conn /as sysdba 登录到oracle 将s ...
- C++ Web 编程
C++ Web 编程 什么是 CGI? 公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的. CGI 规范目前是由 NCSA 维护的,NCSA 定义 CG ...
- 扩展EF的Fluent API中的 OnModelCreating方法 实现全局数据过滤器
1.生成过滤的表达式目录树 protected virtual Expression<Func<TEntity, bool>> CreateFilterExpression&l ...
- lua --- __newindex
-- __newindex 对表进行更新 MyMetatable = {} MyTable = }, {__newindex = MyMetatable}) MyTable.newKey1 = pri ...
- 【转载】LINUX下安装wget命令(SFTP实现法)
如何安装wget命令. 方法一:通过yum 命令行为:yum install wget 完成.此操作很简单,但是我安装的linux是centos的最小版本,运行上述命令时会出现无法连接到源网站(大概是 ...