一个基于Scrapy框架的pixiv爬虫
源码 https://github.com/vicety/Pixiv-Crawler,功能什么的都在这里介绍了
说几个重要的部分吧
登录部分
困扰我最久的部分,网上找的其他pixiv爬虫的登录方式大多已经不再适用或者根本就没打算登录……
首先,登录时显然要提交FormData,一开始我请求的是 https://accounts.pixiv.net/login?lang=zh 这个页面
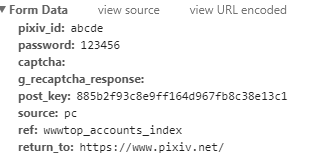
这个postkey可以发现和网页代码中的这个部分(下图)中是一样的,但是用这个postKey是登录不上去的,结果见下图


登录可以成功(收到异常登录邮件),但无论你访问什么页面,它都会无限重定向回这个页面,一开始以为是header填得不完整,可是怎么改都不对
后来发现request请求 http://www.pixiv.net 得到的页面中也有一个postKey(不太明白上一个postKey的含义,难道是特意骗我们一下……)

改用这个,成功登录,剩下应该不是什么问题了
日榜部分
对于日榜的获取(虽然还没有写进去)也值得提一下,日榜的展现是下拉到底端自动获取下一页式的,分析网络请求,发现这一条的链接应该指向的就是下一页,并且去除后面的&tt=96a6bd8c731d3a46a9388f1e8cd90edf也是一样可以访问的

我们进入链接,发现是一个json文件,对于我们来说其实更加易于处理
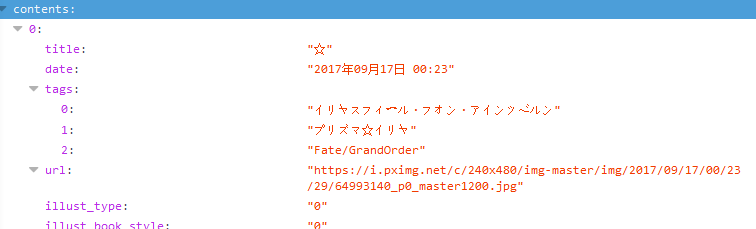
另外说一下,这里推荐Chrome浏览器的JSONView插件,自动解析JSON成方便看的模式,火狐似乎自带这个功能
import json js = json.loads(response.text) url = js["content"][""]["url”]
可以使用类似这样的代码方便地读取json文件
另外注意load和loads函数的区别,loads用于处理字符串而load用于处理文件,对于将文件或是字符串转为json则有dump和dumps函数,就像下面这个例子
import json
data = {
'a': '',
'b': True,
'c': None,
'd': 456,
}
with open("test.json", 'w') as f:
json.dump(data, f) # test.json 内容
# {"a": "123", "b": true, "c": null, "d": 456}
搜索部分
在完成按tag搜索的部分时发现,图片div的class都是这种奇怪的格式,尽管在我的电脑上搜索了其他几个tag这些class的名字都是一样的,但是看这种class的名字就有种莫名的不安啊……可能在换个环境class也是会动态变化的
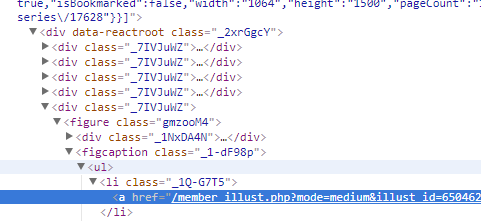
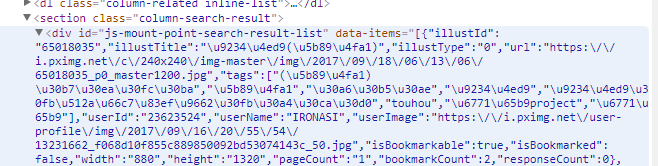
另外发现网页中的这个部分data-items的结构就是json,于是剩下的部分又变得方便很多了
图片获取
在pipeline中获取图片时header中一定要记得带referer,否则会触发p站的防盗链机制,返回403
重要的部分差不多就这些,其他按scrapy的套路走就行
最后,本来想做个GUI的,尝试用pyqt5,发现分离GUI线程和爬虫线程好像挺难解决的,两个线程间用signal通信也很困难,毕竟临时学的qypt,解决不了也正常,于是放弃做GUI的打算……
渣代码,轻喷,欢迎交流指教
一个基于Scrapy框架的pixiv爬虫的更多相关文章
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- python基于scrapy框架的反爬虫机制破解之User-Agent伪装
user agent是指用户代理,简称 UA. 作用:使服务器能够识别客户使用的操作系统及版本.CPU 类型.浏览器及版本.浏览器渲染引擎.浏览器语言.浏览器插件等. 网站常常通过判断 UA 来给不同 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 基于scrapy框架的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. scrapy 框架 高性能的网络请求 高性能的数据解析 高性能的 ...
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- 基于Scrapy的B站爬虫
基于Scrapy的B站爬虫 最近又被叫去做爬虫了,不得不拾起两年前搞的东西. 说起来那时也是突发奇想,想到做一个B站的爬虫,然后用的都是最基本的Python的各种库. 不过确实,实现起来还是有点麻烦的 ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别: 库可以直接拿来就用, 框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令: 创建一个 项目 : cd 到需 ...
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
随机推荐
- redis列表和有序集合
redis中的list数据类型是可以插入重复数据的,有去重的需求的话可以用redis有序集合数据类型 Redis Zadd 命令用于将一个或多个成员元素及其分数值加入到有序集当中. 如果某个成员已经是 ...
- SQLAlchemy相关文档
目录 参考文档 一.执行原生SQL语句 1.实例一 2.实例二 2.实例三 二.ORM操作 1.创建数据库表 (1)创建单表 (2)创建多个表并包含FK.M2M关系 2.操作数据库表 (1)基于sco ...
- sonar:api/ce/submit接口上传失败
https://blog.csdn.net/weixin_34185320/article/details/87115268 https://ask.helplib.com/others/post_1 ...
- Docker 容器的通信(十二)
目录 一.容器间通信 1.IP 通信 2.Docker DNS Server 3.joined 容器 二.容器访问外部网络 三.外部网络访问容器 1.随机端口 2.指定端口 3.不指定任何端口. 4. ...
- 机器学习笔记——k-近邻算法(一)(摘抄于《机器学习实战》)
k-近邻算法 k-近邻算法(kNN),它的工作原理是:存在一个样本数 据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系.输入没有标签的新数据后 ...
- React中的setState到底发生了什么?
https://yq.aliyun.com/ziliao/301671 https://segmentfault.com/a/1190000014498196 https://blog.csdn.ne ...
- Airflow怎么删除系统自带的DAG任务
点击这个按钮 找到dag文件所在路径,并进入路径将其文件删除即可
- centos7配置hadoop
hadoop压缩包下载: 链接:https://pan.baidu.com/s/1dz0Hh75VNKEebcYcbN-4Hw 提取码:g2e3 java压缩包下载: 链接:https://pan.b ...
- P3205 [HNOI2010]合唱队
题目点这里 题面: 为了在即将到来的晚会上有更好的演出效果,作为AAA合唱队负责人的小A需要将合唱队的人根据他们的身高排出一个队形.假定合唱队一共N个人,第i个人的身高为Hi米(1000<=Hi ...
- Java+Tomcat 环境部署
Java+Tomcat 环境部署 下面在Centos7进行安装Java+Tomcat,网上的很多文章,我在部署中都有些问题,下面是我自己总结的一个安装过程! 安装Java环境 首先,我们先到Java官 ...