LevelDB SSTable文件
【LevelDB SSTable文件】
LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。上节介绍Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。
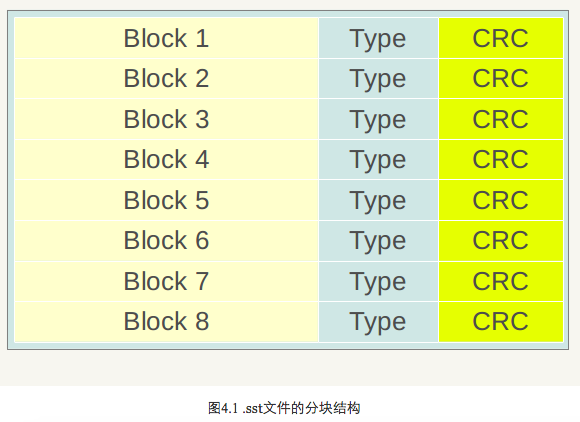
图4.1展示了一个.sst文件的物理划分结构,同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分,红色部分是数据存储区, 蓝色的Type区用于标识数据存储区是否采用了数据压缩算法(Snappy压缩或者无压缩两种),CRC部分则是数据校验码,用于判别数据是否在生成和传输中出错。
以上是.sst的物理布局,下面介绍.sst文件的逻辑布局,所谓逻辑布局,就是说尽管大家都是物理块,但是每一块存储什么内容,内部又有什么结构等。图4.2展示了.sst文件的内部逻辑解释。log系统中,所有block的功能都相同。

从图4.2可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:紫色的Meta Block,红色的MetaBlock 索引和蓝色的数据索引块以及一个文件尾部块。
LevelDb 1.2版对于Meta Block尚无实际使用,只是保留了一个接口,估计会在后续版本中加入内容,下面我们看看数据索引区和文件尾部Footer的内部结构。
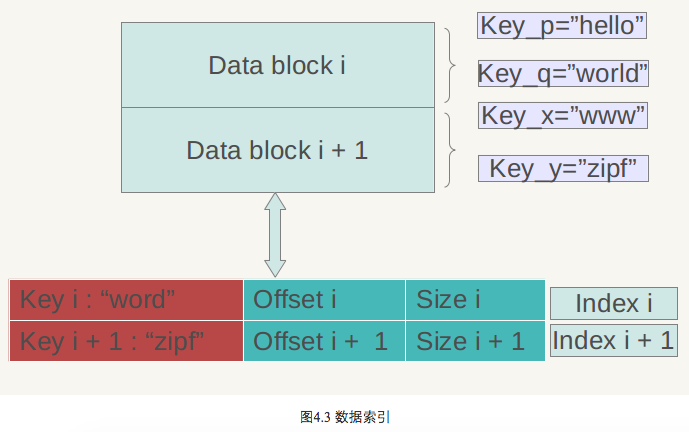
图4.3是数据索引的内部结构示意图。再次强调一下,Data Block内的KV记录是按照Key由小到大排列的,数据索引区的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容,以图4.3所示的数据块i的索引Index i来说:红色部分的第一个字段记载大于等于数据块i中最大的Key值的那个Key,第二个字段指出数据块i在.sst文件中的起始位置,第三个字段指出Data Block i的大小(有时候是有数据压缩的)。后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key,以图4.3的例子来说,假设数据块i的最小Key=“samecity”,最大Key=“the best”;数据块i+1的最小Key=“the fox”,最大Key=“zoo”,那么对于数据块i的索引Index i来说,其第一个字段记载大于等于数据块i的最大Key(“the best”)同时要小于数据块i+1的最小Key(“the fox”),所以例子中Index i的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块i+1的最大Key。
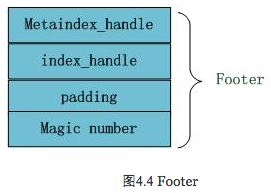
文件末尾Footer块的内部结构见图4.4,metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。
上面主要介绍的是数据管理区的内部结构,下面我们看看数据区的一个Block的数据部分内部是如何布局的(图4.1中的红色部分),图4.5是其内部布局示意图。
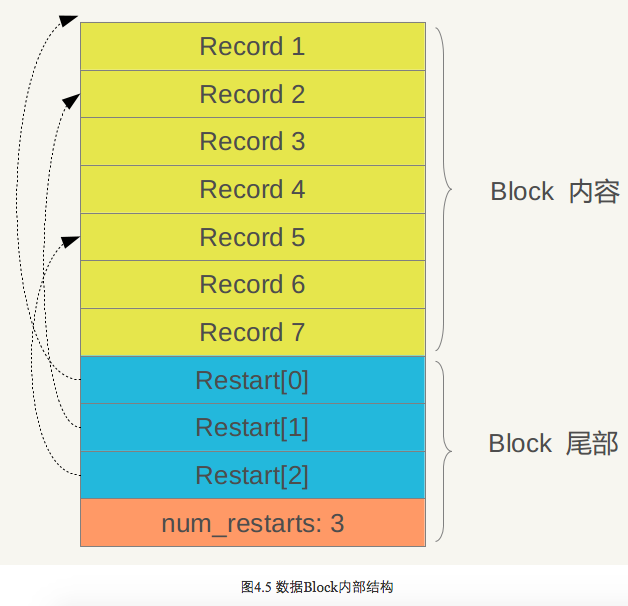
从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
“重启点”是干什么的呢?我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the Car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。Block尾部就是指出哪些记录是这些重启点的。
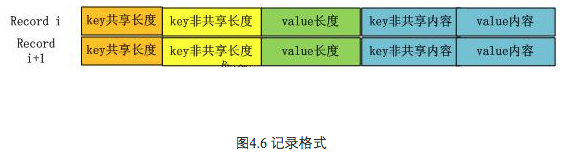
在Block内容区,每个KV记录的内部结构是怎样的?图4.6给出了其详细结构,每个记录包含5个字段:key共享长度,比如上面的“olor”记录, 其key和上一条记录共享的Key部分长度是“the c”的长度,即5;key非共享长度,对于“olor”来说,是4;value长度指出Key:Value中Value的长度,在后面的Value内容字段中存储实际的Value值;而key非共享内容则实际存储“olor”这个Key字符串。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB SSTable文件的更多相关文章
- leveldb - sstable格式
整体上,sstable文件分为数据区与索引区,尾部的footer指出了meta index block与data index block的偏移与大小,data index block指出了各data ...
- LevelDB Log文件
[LevelDB Log文件] log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据.因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Me ...
- Caffe学习系列(11):图像数据转换成db(leveldb/lmdb)文件
在深度学习的实际应用中,我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格式的,而且有可能图片的大小还不一致.而在caffe中经常使用的数据类型是lmdb或leveldb,因此就 ...
- 图像数据转换成db(leveldb/lmdb)文件(转)
参考网站:http://www.cnblogs.com/denny402/p/5082341.html 在深度学习的实际应用中,我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格 ...
- caffe学习系列(1):图像数据转换成db(leveldb/lmdb)文件
参考:http://www.cnblogs.com/denny402/p/5082341.html 上述博文用caffe自带的两张图片为例,将图片转为db格式.博主对命令参数进行了详细的解释,很赞. ...
- LevelDB/Rocksdb 特性分析
LevelDb是Google开源的嵌入式持久化KV 单机存储引擎.采用LSM(Log Structured Merge)tree的形式组织持久化存储的文件sstable.LSM会造成写放大.读放大的问 ...
- LevelDB系列之SSTable(Sorted Strings Table)文件
SSTable是Bigtable中至关重要的一块,对于LevelDb来说也是如此,对LevelDb的SSTable实现细节的了解也有助于了解Bigtable中一些实现细节. 本节内容主要讲述SSTab ...
- LevelDb简单介绍和原理——本质:类似nedb,插入数据文件不断增长(快照),再通过删除老数据做更新
转自:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html 有时间再好好看下整个文章! 说起LevelDb也许您不清楚,但是如果作 ...
- LevelDB源码之五Current文件\Manifest文件\版本信息
版本信息有什么用?先来简要说明三个类的具体用途: Version:代表了某一时刻的数据库版本信息,版本信息的主要内容是当前各个Level的SSTable数据文件列表. VersionSet:维护了一份 ...
随机推荐
- linux 网络测试命令 长期更新
一.网络测试命令 1.测试 网络连接 发送两包后停发 [oracle@hadoop ~]$ PING www.a.shifen.com (() bytes of data. bytes from tt ...
- Python基础学习----拆包
拆包,多用在多值参数种. 1.多值参数. 有时候,在函数的参数转递时,不单只传输单个字符的参数,比如有元组和字典的参数,这时候我们就使用多值参数. *args 代表元组的多值参数 *kwargs 代表 ...
- 2018.12.25 SOW
1. Understanding Customer Requirements 11.1. Project Overview 21.2. System Requirements 21.3. Indust ...
- OMAP4之DSP核(Tesla)软件开发学习(二)Linux内核驱动支持OMAP4 DSP核
注:必须是Linux/arm 3.0以上内核才支持RPMSG,在此使用的是.config - Linux/arm 3.0.31 Kernel Configuration.(soure code fro ...
- PyalgoTrade 绘图(七)
PyAlgoTrade使得绘制策略执行变得非常简单 from pyalgotrade import strategy from pyalgotrade.technical import ma from ...
- 各种Java加密算法
如基本的单向加密算法: BASE64 严格地说,属于编码格式,而非加密算法 MD5(Message Digest algorithm 5,信息摘要算法) SHA(Secure Hash Algorit ...
- [UOJ300][CTSC2017]吉夫特
uoj bzoj luogu sol 根据\(Lucas\)定理,\(\binom nm \mod 2=\binom{n\%2}{m\%2}\times\binom{n/2}{m/2}\mod 2\) ...
- Hystrix已经停止开发,官方推荐替代项目Resilience4j
随着微服务的流行,熔断作为其中一项很重要的技术也广为人知.当微服务的运行质量低于某个临界值时,启动熔断机制,暂停微服务调用一段时间,以保障后端的微服务不会因为持续过负荷而宕机.本文介绍了新一代熔断器R ...
- bzoj 4006 [JLOI2015]管道连接——斯坦纳树
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=4006 除了模板,就是记录 ans[ s ] 表示 s 合法的最小代价.合法即保证 s 里同一 ...
- oracle数据库启动时出现ORA-01157和ORA-01110问题
sql>startup mount; sql>alter database open; RA-01157: 无法标识/锁定数据文件 10 - 请参阅 DBWR 跟踪文件ORA-01110: ...