scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写。
在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流
本篇目标:让拉勾网爬虫能跑起来
分析:我们要通过拉勾网的起始url,通过设定一些规则,跟进我们需要的网页,提取出详情页的某些字段,如:岗位,薪酬,公司名称,地址等
编写lagou_c.py文件
原始代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class LagouCSpider(CrawlSpider):
name = 'lagou_c'
allowed_domains = ['lagou.com']
start_urls = ['http://lagou.com/'] rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
) def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
解释:
LagouCSpider继承自CrawlSpider类,内部定义了4个属性和一个函数
name:代表的是爬虫的名称
allowed_domains:代表的是跟进页面后允许爬取的referer,类型是一个列表,举个例子,如果我要爬取www.baidu.com首页,无论allowed_domains设置成什么我都能爬取到首页,但是如果我要爬取的是百度页面首页的其他链接,如果设置allowed_domains =['baidu.com/']可以继续爬取,然鹅换成allowed_domains=['lagou.com‘],跟进的页面就无法爬取了
start_urls:代表的是初始的urls地址,也就是初始请求url的一个列表
rules:是一个元组类型,里面存放的是一个个Rule对象,也就是规则,这些规则用来限定要跟进的页面,
- LinkExtractor链接提取器:allow参数代表允许跟进的页面url,这里是allow=r'Items/',也就是说对于lagou.com/items/的页面它是会继续跟进爬取的,这个我们后续需要修改为我们需要的。
- callback:回调函数使用parse_item,也就是说这个页面返回的response,使用这个函数来进行解析。另外注意,使用crawl模板生成爬虫时,不要使用parse作为回调函数,否则爬虫可能运行不起来。
- follow:这个字面很好理解,就是跟进,如果没有指定callback函数的话,默认就是跟进,否则的话就是不跟进。也就是说没有到详情页的时候,默认都是跟进的,到了详情页我们需要设置回调函数进行解析了,那默认就不再跟进了,但是如果详情页还有详情页,也有我们需要提取的信息的话,那就设置follow=True。follow不要都设置为True,这样可能导致重复请求。
parse_item:作为回调函数存在,主要做一些页面解析工作
现在先把rules修改下跟进首页的职业方向标签url(zhaopin/.*),在setting.py下修改ROBOTSTXT_OBEY = False(不遵守robots协议)
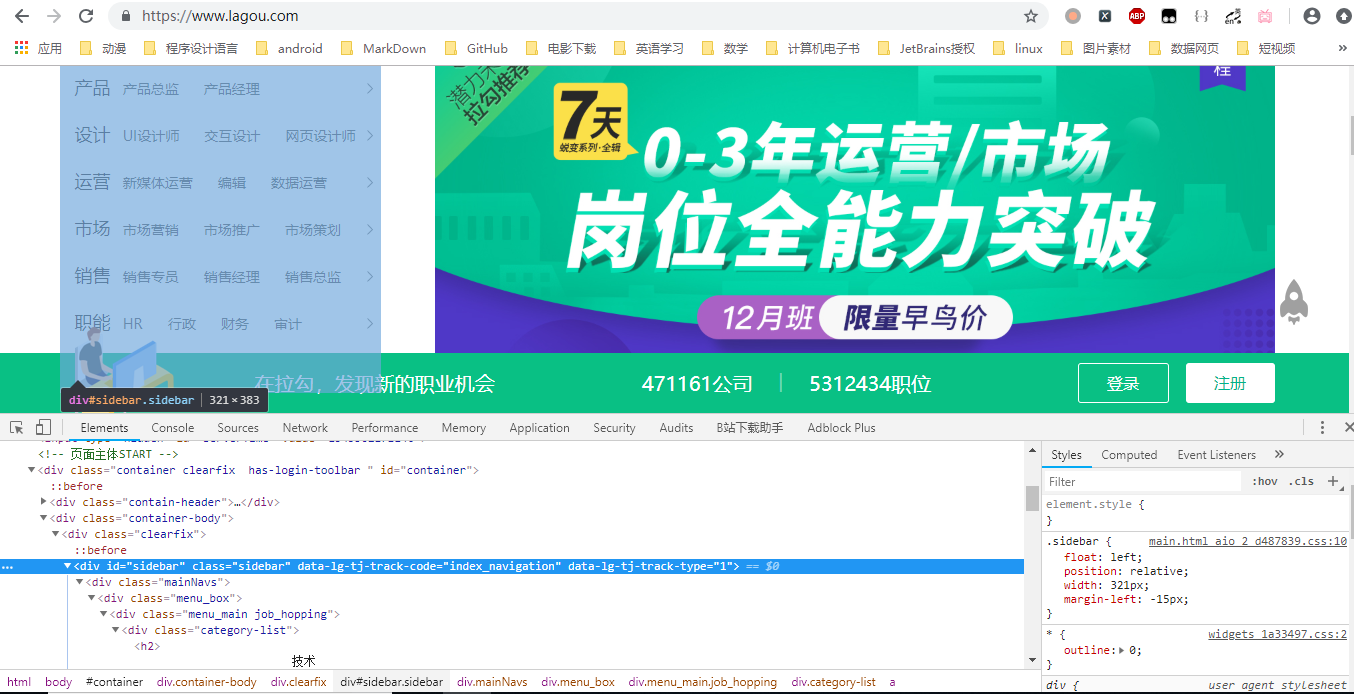
修改的rules代码如下:
rules = (
Rule(LinkExtractor(allow=r'zhaopin/.*',restrict_css='.sidebar')), #restrict_css就是用css选择器对页面进行限制,我这里限制为只只跟进上图中的选定部分
)
在项目根目录下运行一下爬虫,scrapy crawl lagou_c:
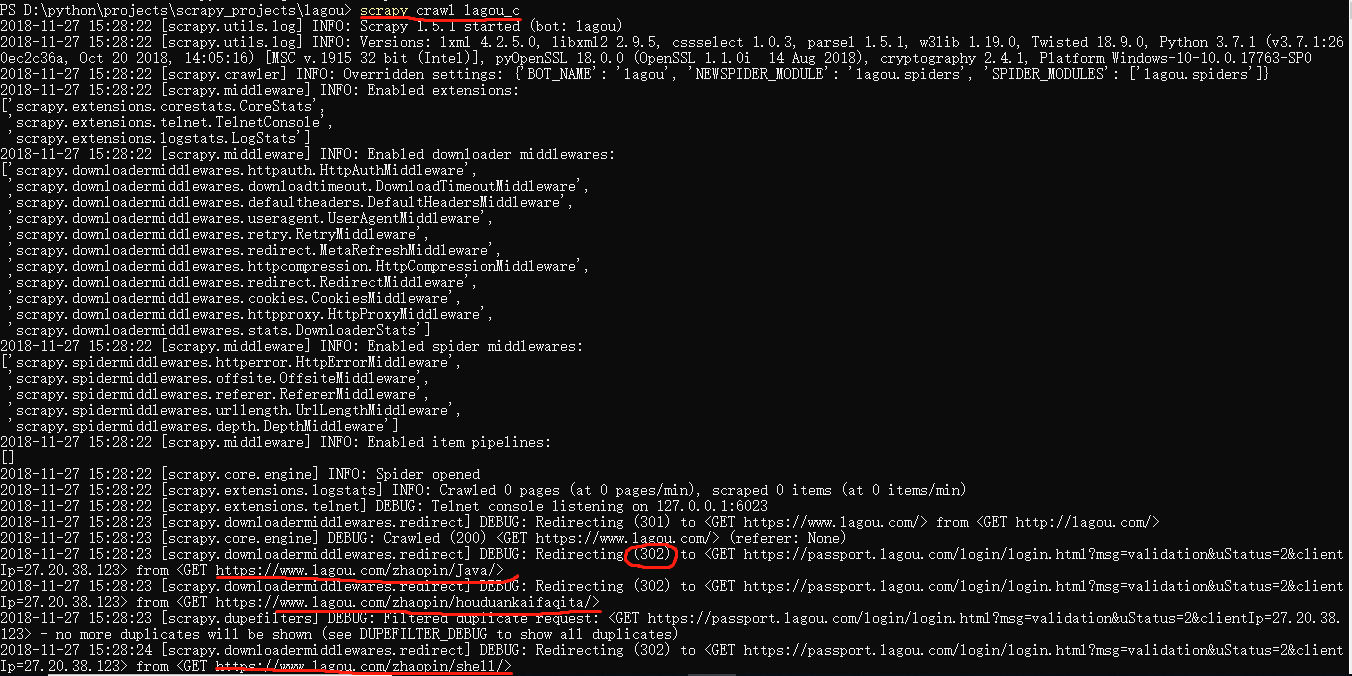
控制台输出的信息显示可以看出来我们确定跟进了哪些标签页,比如java,shell等,但是这些页面的url都重定向到一个网页,而这个网页其实就是拉勾网的登陆页面。
那是不是要登录爬取呢?
大家应该经常听过一句话:可见即可爬。也就是说只要在浏览器能看到的东西都是能爬的,我们在拉勾网查询职位的时候没有登陆也能查询,所以使用爬虫爬取同样不用登录。我们这里增加一个cookie然后进行爬取。对于cookie很多人有误区,认为登录了才会产生cookie,这是不正确的。
在lagou_c.py文件,rules和parse_item函数之间加入custom_settings属性如下(里面的cookie我是网上直接找的一个,当然你也可以自己抓包获取)
custom_settings = {
"COOKIES_ENABLED": False,
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': 'user_trace_token=20171015132411-12af3b52-3a51-466f-bfae-a98fc96b4f90; LGUID=20171015132412-13eaf40f-b169-11e7-960b-525400f775ce; SEARCH_ID=070e82cdbbc04cc8b97710c2c0159ce1; ab_test_random_num=0; X_HTTP_TOKEN=d1cf855aacf760c3965ee017e0d3eb96; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DsXIrWUxpNGLE2g_bKzlUCXPTRJMHxfCs6L20RqgCpUq%26wd%3D%26eqid%3Dee53adaf00026e940000000559e354cc; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_hotjob; login=false; unick=""; _putrc=""; JSESSIONID=ABAAABAAAFCAAEG50060B788C4EED616EB9D1BF30380575; _gat=1; _ga=GA1.2.471681568.1508045060; LGSID=20171015203008-94e1afa5-b1a4-11e7-9788-525400f775ce; LGRID=20171015204552-c792b887-b1a6-11e7-9788-525400f775ce',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
}
再次运行爬虫,首页能正确的抓取了,状态码返回200

我们要对每一个标签页进行跟进,得到详情页
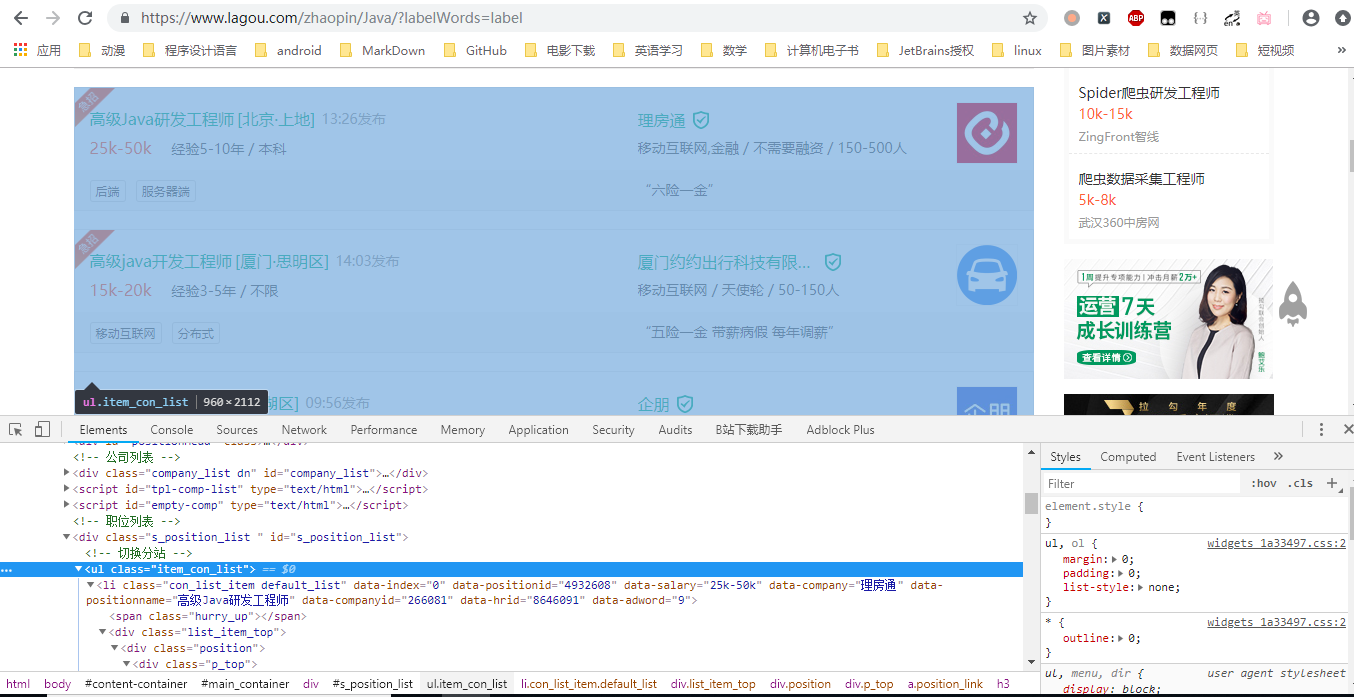
rules变成如下:
rules = (
Rule(LinkExtractor(allow=r'zhaopin/.*',restrict_css='.sidebar')),
Rule(LinkExtractor(allow=r'jobs/\d+.html',restrict_css='.item_con_list')) #同样用restrict_css限制跟进范围
)
再次运行爬虫scrap'y crawl lagou_c,可以看到详情页也陆续显示出来了
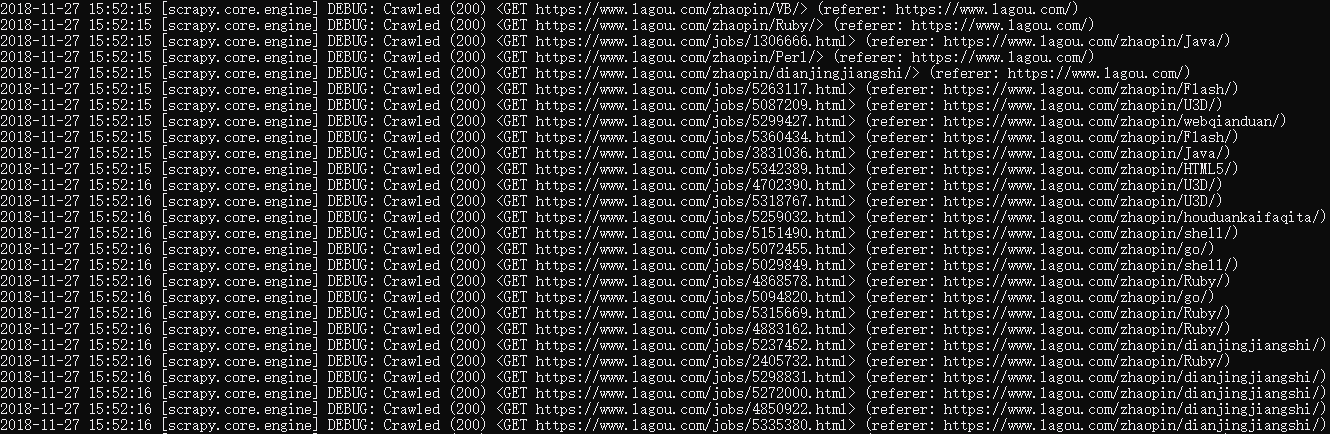
得到的详情页已经是我们所需要的了,我们需要对页面进行解析,并且不再follow(设置follow为False),当然这个rules目前只做了首页的跟进,还有公司页的跟进和校园的跟进需要进行定义,这一部分因为和首页的分析过程差不多,就不详细说了,我们就以首页标签的提取项为目标,rules如下:
rules = (
Rule(LinkExtractor(allow=r'zhaopin',restrict_css='.sidebar')),
Rule(LinkExtractor(allow=r'jobs',restrict_css='.s_position_list'),callback='parse_item',follow=False),
)
对详情页的链接提取后,不再进行跟进,并且使用一个回调函数对页面进行解析,当然解析前需要对我们要提取的字段进行定义。
2、编写items.py文件(还是那句话,实际写代码进行必要的注释就好,不要每条都写,我这里为了更详细解释,全写了)
原始代码如下:
import scrapy class LagouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
我们增加字段后代码如下:
import scrapy class LagouspiderItem(scrapy.Item):
url = scrapy.Field() #详情页面的url地址
name = scrapy.Field() #岗位名称
salary = scrapy.Field() #薪水
location = scrapy.Field() #地址
work_exp = scrapy.Field() #工作经验
edu_background = scrapy.Field() #学历要求
type = scrapy.Field() #工作类型
tags = scrapy.Field() #标签
release_time = scrapy.Field() #发布时间
advantage = scrapy.Field() #职位诱惑
job_desc = scrapy.Field() #职位描述
work_addr = scrapy.Field() #工作地址
company = scrapy.Field() #公司名称
scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- 简单的异步HTTP服务端和客户端
/// <summary> /// 异步Http服务器 /// </summary> class AsyncHttpServer { readonly HttpListener ...
- Windows下端口占用查看
假如我们需要确定谁占用了我们的80端口 1.Windows平台在windows命令行窗口下执行:C:\>netstat -aon|findstr "80" TCP 1 ...
- js获取摄像头视频流
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- Spring与MyBatis的整合(山东数漫江湖)
首先看一下项目结构图: 具体步骤如下: 1.建立JDBC属性文件 jdbc.properties (文件编码修改为 utf-8 ) driver=com.mysql.jdbc.Driver url=j ...
- flask函数已定义参数却出现takes 0 positional arguments but 1 was given的问题
在flask中定义了一个简单的删除数据库内容的路由 测试却发现一直报错 说delete_history函数定义时没有接受参数,但是检查delete_history函数却发现没有问题 后来想了半天才发现 ...
- ES6数组去重及ES5数组去重方法
ES6中新增了Set数据结构,类似于数组,但是 它的成员都是唯一的 ,其构造函数可以接受一个数组作为参数,如: let array = [1, 1, 1, 1, 2, 3, 4, 4, 5, 3]; ...
- hdu 4190 Distributing Ballot Boxes(贪心+二分查找)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4190 Distributing Ballot Boxes Time Limit: 20000/1000 ...
- GNU Readline 库及编程简介【转】
转自:https://www.cnblogs.com/hazir/p/instruction_to_readline.html 用过 Bash 命令行的一定知道,Bash 有几个特性: TAB 键可以 ...
- 51/52单片机 TCON控制字及TMOD寄存器
转载:http://blog.csdn.net/u010698858/article/details/44118157 TCON:定时器控制寄存器 寄存器地址88H,位寻址8FH-88H. 位地址 8 ...
- 网络知识===关于MAC地址和IP不能互相替代,缺一不可的原因
最近在看书<图解TCP/IP>书中分别谈到了IP和MAC地址.于是我就有两个疑惑, 为什么有了IP地址,我们还要获取MAC地址? 为什么我们初始不直接使用MAC地址作为终点地址?还要那么复 ...