大数据系列之Kafka安装

先简单说下安装kafka的流程。。(可配置多个zookeeper,这篇文只说一个zookeeper场景)
1.环境配置:jdk1.7+ (LZ用的是jdk1.8)
2.资料准备:下载 kafka_2.10-0.10.1.1.tgz ,官网链接为https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.1.1/kafka_2.10-0.10.1.1.tgz
3.单机版安装步骤:
a.将tgz放入目录: /app/
b.解压:
tar -xzvf kafka_2.-0.10.1.1.tgz
c.修改配置:(暂时可不修改)
d.启动zookeeper:在kafka文件夹下操作命令
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties &
e.验证启动状态: jps,出现红色尖头部分表示启动成功

f.启动kafka
bin/kafka-server-start.sh -daemon config/server.properties &
g.验证kafka启动状态: jps
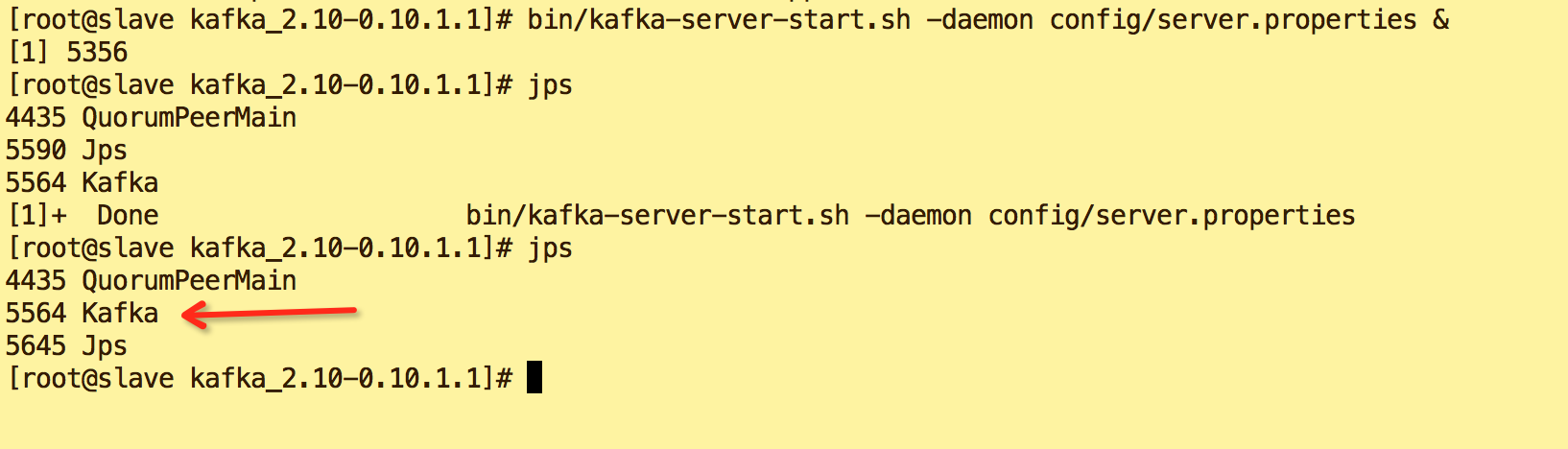
h.创建topic,名为slavetest
bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic slavetest

i.topic为slavetest ,生产数据
bin/kafka-console-producer.sh --broker-list localhost: --topic slavetest

j.另打开一个终端连接操作,消费数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic slavetest --from-beginning
k.验证(Producer-Consumer)


l.End
4.分布式版安装步骤:
与单机版不同的是在于
注意事项
1.修改配置:config/server.properties
a.master节点上
broker.id=0
zookeeper.connect=master:2181
b.slave节点上
broker.id=1
zookeeper.connect=master:2181
2.slave不启动zk,可直接启动kafka
3.slave节点上开启消费命令时将localhost改为master
bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic slavetest --from-beginning
验证:
1.master 节点生产者
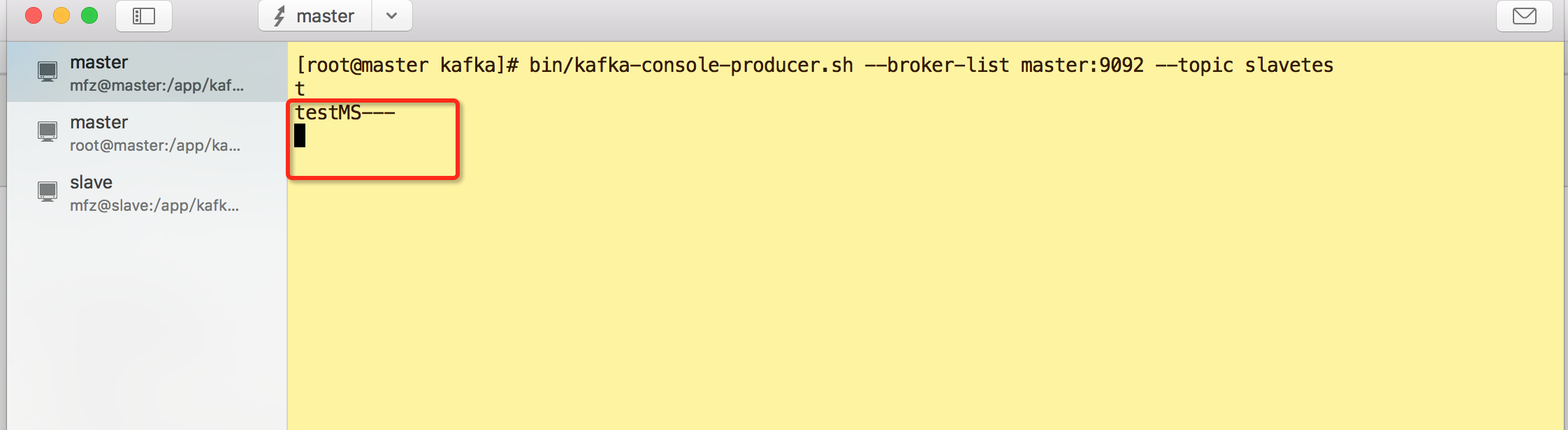
2.master节点上消费者

3.slave节点上消费者

大数据系列之Kafka安装的更多相关文章
- 大数据系列之kafka监控kafkaoffsetmonitor安装
1.下载kafkaoffsetmonitor的jar包,可以到github搜索kafkaoffsetmonitor,第一个就是,里面可以下载编译好了的包. KafkaOffsetMonitor-ass ...
- 【大数据系列】Hive安装及web模式管理
一.什么是Hive Hive是建立在Hadoop基础常的数据仓库基础架构,,它提供了一系列的工具,可以用了进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在Hadoop中的按规模数据的 ...
- 【大数据系列】hive安装及启动
一.安装好jdk和hadoop 二.下载apache-hive https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.0/ 三.解压到安装 ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- SWERC2015-I Text Processor
题意 给一个长度为\(n\)的字符串\(s\),再给定一个\(w\),问对于所有的\(i\in [1,n-w+1]\),\(s[i..i+w-1]\)有多少个不同字串.\(n,w\le 10^5\). ...
- 洛谷 P2574 XOR的艺术
刚刚学了,线段树,一道线段树入门题试试水 下面是题面 题目描述 AKN觉得第一题太水了,不屑于写第一题,所以他又玩起了新的游戏.在游戏中,他发现,这个游戏的伤害计算有一个规律,规律如下 1. 拥有一个 ...
- 一些noip模拟题一句话题解
Problem A: 序列 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 12 Solved: 9[Submit][Status][Web Boar ...
- [学习笔记]FHQ-Treap及其可持久化
感觉范浩强真的巨 博主只刷了模板所以就讲基础 fhq-treap 又形象的称为非旋转treap 顾名思义 保留了treap的随机数堆的特点,并以此作为复杂度正确的条件 并且所有的实现不用旋转! 思路自 ...
- Qt实现截屏并保存(转载)
原博地址:http://blog.csdn.net/qinchunwuhui/article/details/52869451?_t_t_t=0.28889142944202306 目前对应用实现截屏 ...
- [Java多线程]-线程池的基本使用和部分源码解析(创建,执行原理)
前面的文章:多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类) 多线程爬坑之路-Thread和Runable源码解析 多线 ...
- Kubernetes - Deploy Containers Using YAML
In this scenario, you'll learn how to use Kubectl to create and launch Deployments, Replication Cont ...
- 关于NUL
问题:正常的order by不起作用了,如下图 分析:使用notepad++打开,发现 NUL以字符'\0'作为字符串结束标志.'\0'是一个ASCII码为0的字符,从ASCII码表中可以看到ASCI ...
- 前端PHP入门-025-数组-重中之重
数组是PHP中一个 很很很很很很很很很很重要 的一个 数据类型 . 学习数组,大家主要学习两部份的知识: 1.数组的定义,定义中的一些注意的坑 2.数组的函数使用 认识数组 数组定义 数组在之前我们让 ...
- 子序列 sub sequence问题,例:最长公共子序列,[LeetCode] Distinct Subsequences(求子序列个数)
引言 子序列和子字符串或者连续子集的不同之处在于,子序列不需要是原序列上连续的值. 对于子序列的题目,大多数需要用到DP的思想,因此,状态转移是关键. 这里摘录两个常见子序列问题及其解法. 例题1, ...