Python入门,以及简单爬取网页文本内容
最近痴迷于Python的逻辑控制,还有爬虫的一方面,原本的目标是拷贝老师上课时U盘的数据。后来发现基础知识掌握的并不是很牢固。便去借了一本Python基础和两本爬虫框架的书。便开始了自己的入坑之旅
言归正传
前期准备
Import requests;我们需要引入这个包。但是有些用户环境并不具备这个包,那么我们就会在引入的时候报错

这个样子相信大家都不愿意看到那么便出现了一下解决方案
我们需要打开Cmd 然后进入到我们安装Python的Scripts目录下输入指令
pip install requests
当然还会出现下面的情况
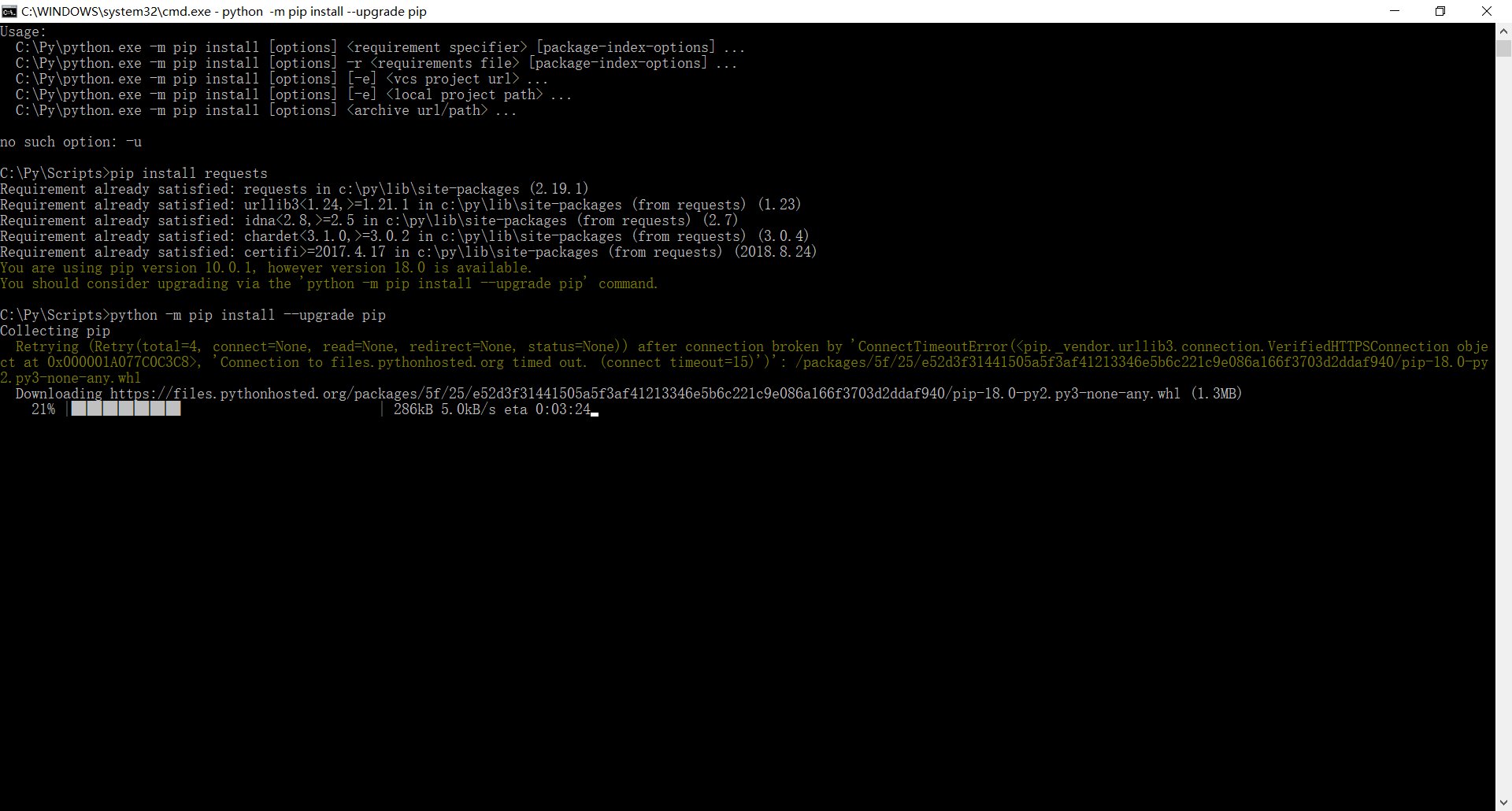
又是一个报错是不是很烦 那么我们按它的提示升级一下组件 输入命令 python -m pip install --upgrade pip 安装成功后我们便可以正常的导入 requests 那么我们是不是就可以做一下什么了?比如说爬取一个网站的所有信息爬取下来?
import requests;
//导入我们需要的库 def GetName(url):
//定义一个函数并且传入参数Url
resp=requests.get(url);
//获取网页上的所有信息 //以文本的模型返回
return resp.text; //定义一个字符串也就是我们要爬取的地址
url="https:xxxxxxxxxx"; //函数方法
def xieru():
//打开一个文本,以写入的方式写入二级制文本
fi=open('E://1.txt',"wb+");
//接受
con = GetName(url);
//返还的文本转换编码格式
ss=con.encode('utf-8')
//写入打开的文本中
fi.write(ss);
return 0; xieru(); 哈哈 上面的网址就打码了哦,大家自己脑补。
这是我爬取的内容

Python入门,以及简单爬取网页文本内容的更多相关文章
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
- python爬取网页文本、图片
从网页爬取文本信息: eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称) 注:如果要爬取的内容是多页的话,网址 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
- Python -- 网络编程 -- 简单抓取网页
抓取网页: urllib.request.urlopen(url).read().decode('utf-8') --- (百度是utf-8,谷歌不是utf-8,也不是cp936,ascii也不行 ...
- java实现多线程使用多个代理ip的方式爬取网页页面内容
项目的目录结构 核心源码: package cn.edu.zyt.spider; import java.io.BufferedInputStream; import java.io.FileInpu ...
- MVC爬取网页指定内容到数据库
控制器 //获取并插入 //XPath获取 public JsonResult Add(string url) { HtmlWeb web = new HtmlWeb(); HtmlDocument ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
随机推荐
- hash(2018年CSUST省赛选拔赛第一场B题+hash+字典树)
题目链接:http://csustacm.com:4803/problem/1006 题目: 思路:正如题目一样,本题是一个hash,比赛的时候用的字典树,但是不知道为什么一直RE(听学长说要动态开点 ...
- 爬虫实战--基于requests和beautifulsoup的妹子网图片爬取(福利哦!)
#coding=utf-8 import requests from bs4 import BeautifulSoup import os all_url = 'http://www.mzitu.co ...
- SpringMVC可以配置多个拦截后缀*.action和.do等
首先介绍一下.do和.action的区别: struts早期的1版本,以.do为后缀. 同时spring的MVC也是以.do为后缀. 几年前struts收购鼎鼎大名的webwork2和开发团队后,将w ...
- ogg数据初始化历程记录
之前,源端数据表结构发生改变,不知道前面的同事是怎么搞得(生成的数据定义文件不对,还是没有把进程启动),造成进程停止20天,然后重启复制进程,对比源端和目标端数据有差异(总共差10000多条数据),问 ...
- Linux sqlite3基本命令
简介sqlite3一款主要用于嵌入式的轻量级数据库,本文旨在为熟悉sqlite3基本命令提供技术文档. 备注:本文所有操作均在root用户下进行. 1.安装sqlite3 ubuntu下安装sqlit ...
- Linux内核中的Cache段
Linux内核中的Cache段 原文地址:http://blogold.chinaunix.net/u2/85263/showart_1743693.html 最近移植LEON3的内核时,了解了一些简 ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- DAG blockchain (byteball)
转载参考自: https://www.jinse.com/bitcoin/116184.html https://www.jinse.com/blockchain/116175.html https: ...
- Dubbo使用
[注:本文参考<Dubbo入门---搭建一个最简单的Demo框架>,感谢原创作者的知识探索与奉献] 一.Dubbo背景和简介 Dubbo开始于电商系统,因此在这里先从电商系统的演变讲起. ...
- AWS 使用总结
A.升配置的流程: 1.新开一台配置较高的机器; 2.将新机器和老机器的磁盘都取消关联,注意需要记录下老机器的磁盘分区设备名,如:/dev/sda1: 3.将老机器的磁盘挂载到新机器上,磁盘分区设备名 ...