Python入门,以及简单爬取网页文本内容
最近痴迷于Python的逻辑控制,还有爬虫的一方面,原本的目标是拷贝老师上课时U盘的数据。后来发现基础知识掌握的并不是很牢固。便去借了一本Python基础和两本爬虫框架的书。便开始了自己的入坑之旅
言归正传
前期准备
Import requests;我们需要引入这个包。但是有些用户环境并不具备这个包,那么我们就会在引入的时候报错

这个样子相信大家都不愿意看到那么便出现了一下解决方案
我们需要打开Cmd 然后进入到我们安装Python的Scripts目录下输入指令
pip install requests
当然还会出现下面的情况
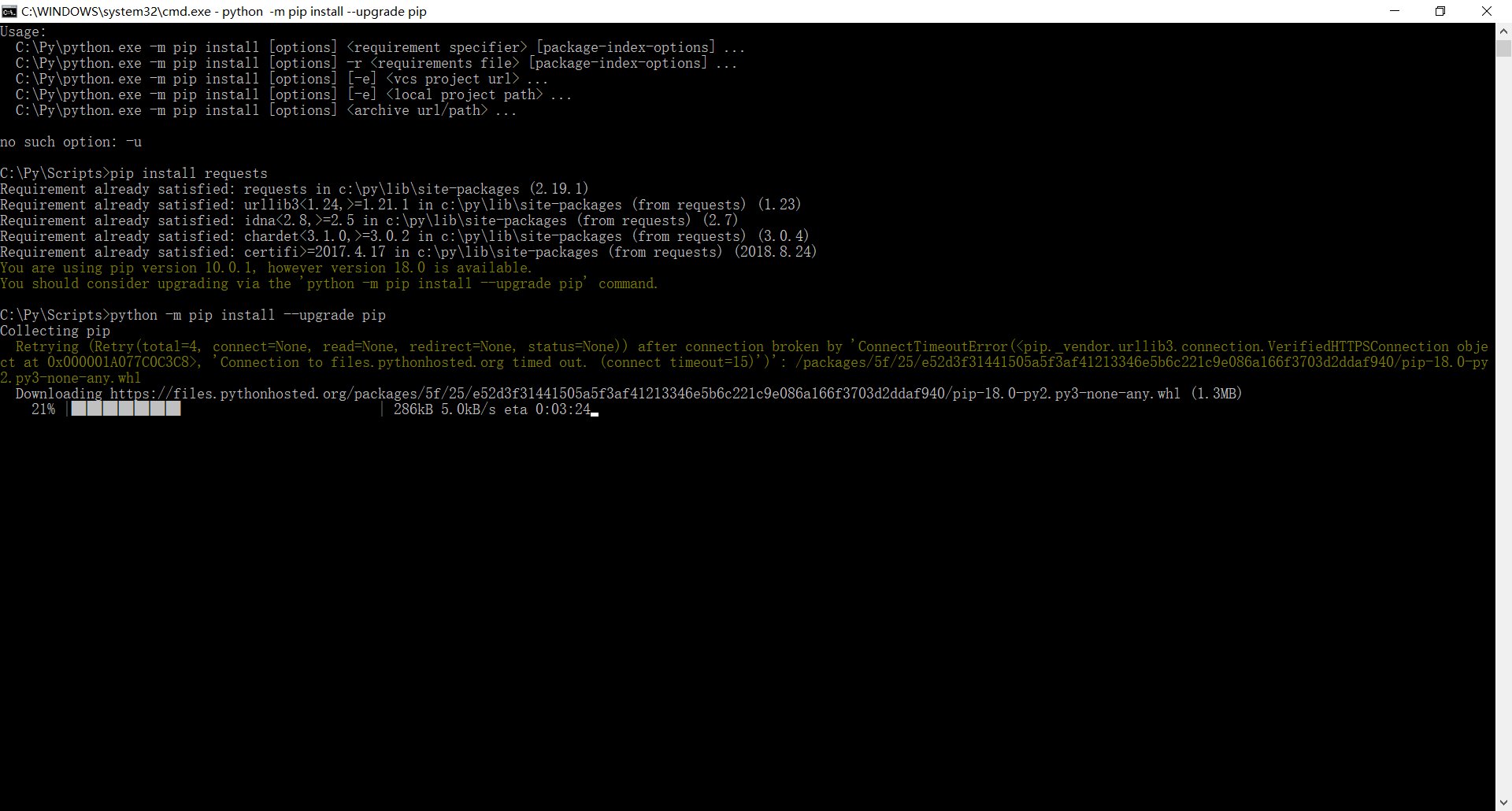
又是一个报错是不是很烦 那么我们按它的提示升级一下组件 输入命令 python -m pip install --upgrade pip 安装成功后我们便可以正常的导入 requests 那么我们是不是就可以做一下什么了?比如说爬取一个网站的所有信息爬取下来?
import requests;
//导入我们需要的库 def GetName(url):
//定义一个函数并且传入参数Url
resp=requests.get(url);
//获取网页上的所有信息 //以文本的模型返回
return resp.text; //定义一个字符串也就是我们要爬取的地址
url="https:xxxxxxxxxx"; //函数方法
def xieru():
//打开一个文本,以写入的方式写入二级制文本
fi=open('E://1.txt',"wb+");
//接受
con = GetName(url);
//返还的文本转换编码格式
ss=con.encode('utf-8')
//写入打开的文本中
fi.write(ss);
return 0; xieru(); 哈哈 上面的网址就打码了哦,大家自己脑补。
这是我爬取的内容

Python入门,以及简单爬取网页文本内容的更多相关文章
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
- python爬取网页文本、图片
从网页爬取文本信息: eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称) 注:如果要爬取的内容是多页的话,网址 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
- Python -- 网络编程 -- 简单抓取网页
抓取网页: urllib.request.urlopen(url).read().decode('utf-8') --- (百度是utf-8,谷歌不是utf-8,也不是cp936,ascii也不行 ...
- java实现多线程使用多个代理ip的方式爬取网页页面内容
项目的目录结构 核心源码: package cn.edu.zyt.spider; import java.io.BufferedInputStream; import java.io.FileInpu ...
- MVC爬取网页指定内容到数据库
控制器 //获取并插入 //XPath获取 public JsonResult Add(string url) { HtmlWeb web = new HtmlWeb(); HtmlDocument ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
随机推荐
- python mysql参数化查询防sql注入
一.写法 cursor.execute('insert into user (name,password) value (?,?)',(name,password)) 或者 cursor.execut ...
- vue.js devtools-------调试vue.js的开发者插件
vue.js devtools插件: 作用: 以往我们在进行测试代码的时候,直接在console进行查看,其实这个插件雷同于控制台,只不过在vue里面,将需要查看的数据存放在一个变量里面了~ 效果图: ...
- 35、def func(a,b=[]) 这种写法有什么坑?
那我们先通过程序看看这个函数有什么坑吧! def func(a,b=[]): b.append(a) print(b) func(1) func(1) func(1) func(1) 看下结果 [1] ...
- Unity MMO 参考数值
贴图格式: iOS :RGBA 32 (pvrtc 4 ) Android : RGB Compresed ETC 4 或 RGBA 32 . DrawCall: 总计Drawcall 平均 100 ...
- JDK1.8新特性
1.Lambda Lambda的语法目前仅对于只有一个抽象方法的接口. 在Lamb ...
- 在ubuntu中安装puppeteer
https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md 早些时候puppeteer刚出来,在vps上 ...
- python的sorted函数对字典按value进行排序
场景:词频统计时候,我们往往要对频率进行排序 sorted(iterable,key,reverse),sorted一共有iterable,key,reverse这三个参数.其中iterable表示可 ...
- NFS挂载报如下错误信息:mount.nfs: Stale NFS file handle解决
1)用fuser杀掉占用那个目录的进程 linux:~ # fuser -k /home/msgplus/msgplus/remote_dir 2)强制umount linux:~ # umount ...
- 产生唯一的临时文件mkstemp()
INUX下建立临时的方法(函数)有很多, mktemp, tmpfile等等. 今天只推荐最安全最好用的一种: mkstemp. mkstemp (建立唯一临时文件)头文件: #include < ...
- 1.第一个hello word
1.生产者 #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParamete ...