深入浅出聊Taier—大数据分布式可视化DAG任务调度系统

导读:
上周,袋鼠云数栈全新技术开源规划——DTMO(DTstack Meetup Online)的第一场直播圆满完成。袋鼠云数栈大数据开发专家、Taier项目主导人偷天为大家带来了《Taier入门介绍》的分享,我们将直播精华部分做了整理,带大家再次回顾内容,加深技术细节的了解。
你能看到
Taier发展历程
Taier架构设计和功能详解
Taier具体应用和未来规划
点击链接,查看直播视频回放
https://www.bilibili.com/video/BV13L4y1L71w?spm_id_from=333.1007.top_right_bar_window_history.content.click
欢迎加入开源框架技术交流群
(钉钉群:30537511)
开源项目技术交流
ChunJun
https://github.com/DTStack/chunjun
https://gitee.com/dtstack_dev_0/chunjun
Taier
https://github.com/DTStack/Taier
https://gitee.com/dtstack_dev_0/taier
MoleCule
https://github.com/DTStack/molecule
https://gitee.com/dtstack_dev_0/molecule
演讲 / 偷天
整理 / 向山
Taier发展历程
Taier是袋鼠云数栈大数据家族的开源项目之一 ,于2022年2月22日正式在github上开源,它是一个分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,让大数据开发人员可以在Taier直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
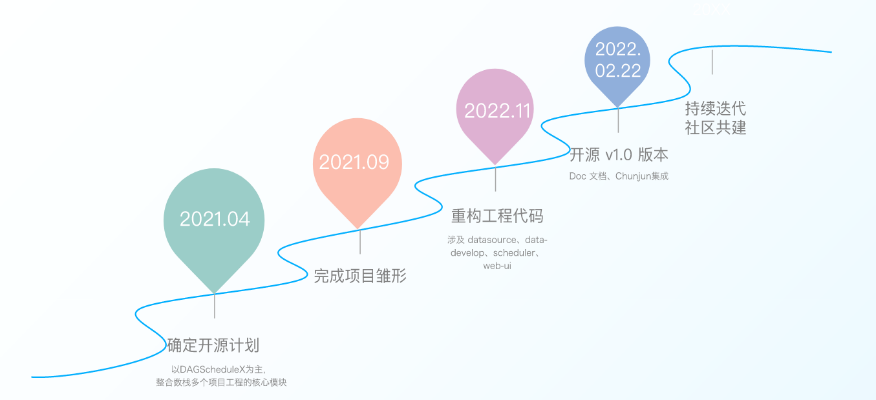
2021年4月,数栈技术团队确定了以DAGScheduleX为主,复合多个项目工程的核心板块的开源计划;
2021年9月,技术团队完成了项目雏形;
2021年11月,我们重构了DAGScheduleX的工程代码,并将之正式命名为Taier;
2022年2月22日,经过不断的打磨和不懈的努力,Taier终于正式开源1.0版本。
开源并不意味着项目的结束,恰恰是项目的开始,未来Taier将持续自我迭代,积极吸取社区力量,不断优化,推出更优越的版本。
Taier的前世与雏形
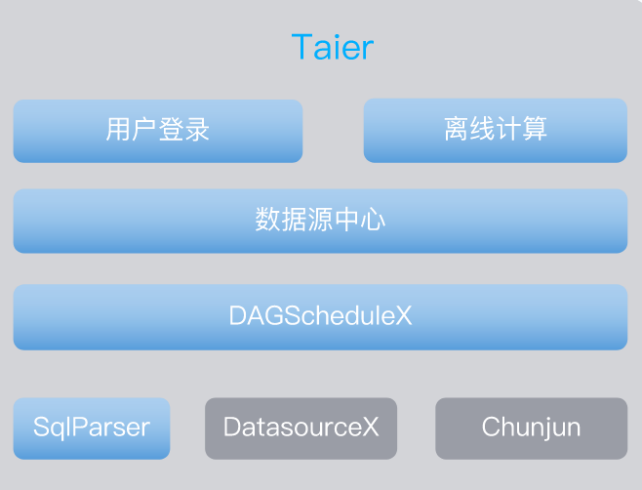
Taier最早之前在数栈内的雏形是当时负责数栈“承上启下”的基础组件DAGScheduleX。
它承上对接各个上层应用(离线开发、实时开发、算法开发、标签引擎、数据服务、数据质量、数据资产),启下兼容多集群多版本(Hadoop、CDH、TDH、HDP、MRS),实现任务实例的分布式调度运行。在作为数栈的基础组件服务过程中,DAGScheduleX累计为数百家企业提供了大数据任务调度能力,在前期为后续的更新整合积累了大量的实战经验。
DAGScheduleX可以做到很多,但还远远不够。数栈边运用边迭代,渐渐地看见围绕着它开发更多功能,一体化解决问题的可能性。这时,Taier雏形已经具备清晰的构想,作为一个任务调度系统,Taier初步设计具备以下这些模块。
v1.0的里程碑意义
回头看,Taier的开发之路是由4组具有里程碑意义的数据铺成的:
- Taier开发团队累计解决了70+个大大小小的 issue ;
- 总共311次代码commit ;
- 90w+代码修改行数
- 初始的9位Contributor。
道阻且长,我们却已经走了这么远。
架构设计和功能详解
在架构设计与功能特点上,Taier整体架构是使用插件式的开发模式,在任务开发下面有调度模块和各项组件,也包括数栈开源家族的Chunjun等等。
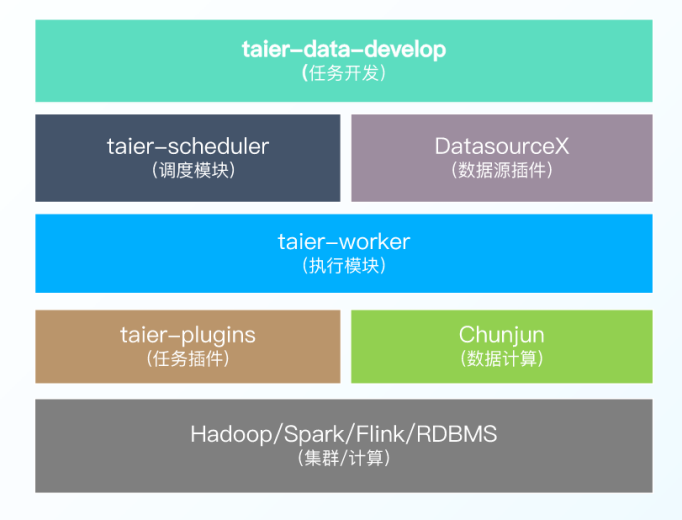
Taier功能特点
Taier的功能特点有下面几个比较重要的方面:
1.任务类型:Spark SQL、数据同步(流计算任务);
2.控制台:包括队列管理、资源管理、多集群管理等;
3.运维中心:比如任务管理、周期调度、补数据等;
4.插件化开发:具体包括 taier-plugin、、DatasourceX、Chunjun等几个插件。

Taier功能特征
随着不断更新完善,现在的Taier已经具有以下的几种特性:
稳定性
单点故障:去中心化的分布式模式
高可用方式:Zookeeper
过载处理∶分布式节点+两级存储策略+队列机制。每个节点都可以处理任务调度与提交;任务多时会优先缓存在内存队列,超出可配置的队列最大数量值后会全部落数据库;任务处理以队列方式消费,队列异步从数据库获取可执行实例
实战检验:得到数百家企业客户生产环境实战检验
易用性
支持大数据作业Spark、Flink的调度;
支持众多的任务类型,目前支持Spark SQL、Chunjun
可视化工作流配置︰支持封装工作流、支持单任务运行,不必封装工作流、支持拖拽模式绘制;
DAG监控界面:运维中心、支持集群资源查看,了解当前集群资源的剩余情况、支持对调度队列中的任务批量停止、任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然;
调度时间配置:可视化配置;
多集群连接:支持一套调度系统连接多套Hadoop集群。
多版本引擎
支持Spark 、Flink等引擎的多个版本共存,例如可同时支持Flink1.10、Flink1.12(后续开源)
Kerberos支持Spark、Flink
丰富,支持3种时间基准,且可以灵活设置输出格式。
扩展性
设计之处就考虑分布式模式,目前支持整体Taier 水平扩容方式;调度能力也随集群线性增长。
Taier重要概念
下面从原理和操作层面给大家进一步介绍Taier,还有一些具体概念的解释。
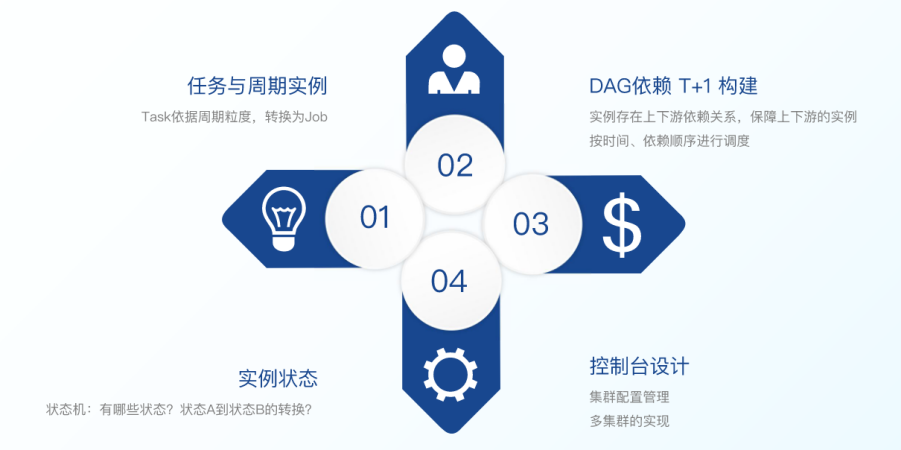
任务与实例
方便起见,数栈在Taier中提出“任务”和“实例”两个概念,例如数据开发的数据同步这项工作称之为“任务”,而已经提交并且配置了周期属性的任就称之为“实例”。
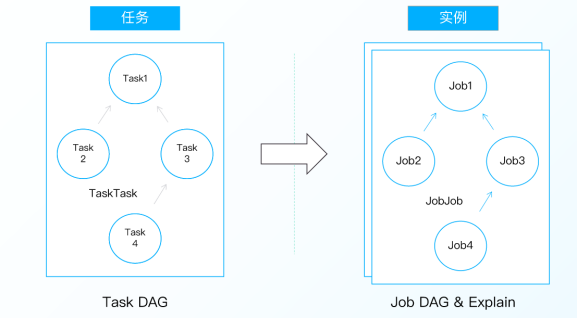
实例具体操作
在Taier中,实例有这几种构建的方式:
1.基于Zookeeper选举Master节点参与Job 实例构建,T+1构建JobGraph
2. JobGraph构建前check &clean DirtyData
3.依据Task、TaskTask的数据(JobGraph)生成Job .JobJob实例数据
4.Master节点控制实例数据的负载均衡持久化入数据库

构建完毕后,实例处理的几种方式如下图所示:
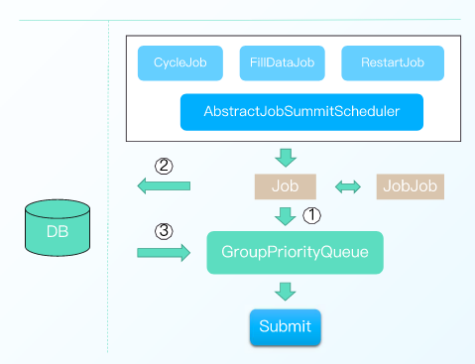
其中:
1.三种任务类型:周期任务、补数据任务、重跑任务,统一调度方式
2. Job 优先入队列(1),队列容量不足入DB (2)
3.当队列容量空余时,异步线程从DB加载数据入队列(3)
4. Job出队列后进行任务提交
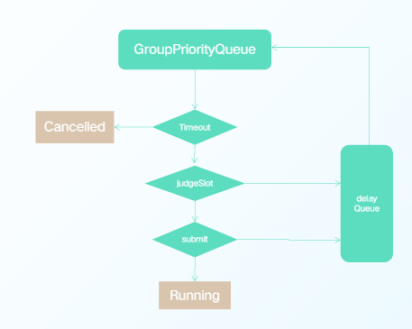
处理完成后,实例提交我们也做了思考,具体设计:
1.内存优先级队列,控制Job有序执行
2.多线程并发提交(可配置)
3. Job 执行超时判断(可配置)
4. Job资源不足/失败重试进入延迟队列(可配置)﹔避免长时间占用提交权
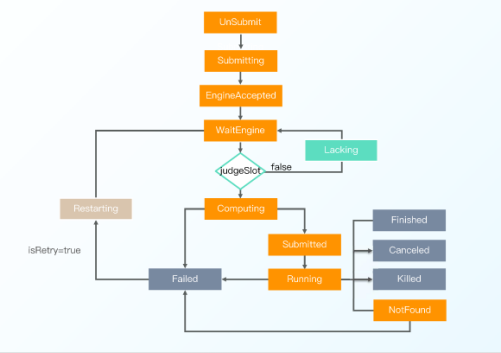
Taier 的实例状态大家主要应该关注标志停止的几个,具体有下面几种:
1. WaitEngine:内存队列中的Job、内存容量不足存储在DB中的Job(默认500 )
2. Lacking:资源不足暂时等待的Job(默认2min)
3. Restarting:失败重试的Job(默认2min )
4. Finshed、Failed、Canceled、Killed:结束状态
Taier的整个控制台设计分为公共组件、调度组件、存储组件和计划组件。通过一个租户ID,拿到这个集群下common, YARN-conf等的四个配置信息,组成包含一个任务插件所有信息的pluginlnfo。将它解析之后,一些资源初始化上传,以便我们缓存对应的客户端。


Taier Client Plugin这里,要快速开发一个插件要注意以下几点:
- 一种任务类型对应一个插件,即一个jar包
- 自定义类加载器(Classloader) 破坏双亲委派优先加载( Child-First)插件
- 插件实现IClient接口方法
- SPI: 在classpath 下的META-INF/services/目录下,创建以接口IClient 全限定名命名的文件,内容是上一步中实现类的全限定名

具体应用
Taier 部署环境依赖
- 大数据组件:Flink、Spark (ThriftServer)、Hive
- 三方框架:Datasourcex (4.3.0)、Chunjun(1.10.5)
- 基础组件: JDK版本:JDK 1.8 + 、MySQL版本:MySQL 5.7.33+、Zookeeper版本:Zookeeper 3.5.7
- Hadoop 2.7.3 :HDFS、Yarn
环境依赖配置完毕之后,Taier编译&启动按下面流程操作:
- 后端: /build/mvn-build.sh,检查lib、pluginLibs目录
DB初始化,sql/create.sql、sql/insert.sql、Datasourcex、Chunjun插件、配置conf/application.properties
- 前端:安装Node、yarn、mini-cup 和pm2、yarn build、检查dist目录、cup.config.js
编译启动之后,Taier应用的具体操作的步骤如下:
- 登录、新建租户
- 依次配置集群组件、公共组件、调度组件,上传hadoop zip配置·存储组件,同上
- 计算组件:Spark相关(Spark SQL)、Hive相关(Hive sQL)、Flink相关(数据同步)
- 租户绑定:资源使用情况
- 任务开发&运行操作界面如下图:
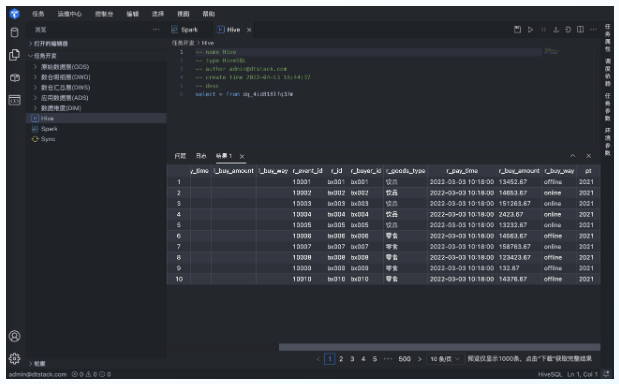
未来规划
目前袋鼠云开源家族已经汇齐Taier与Chunjun双剑,未来我们计划集成Chunjun,丰富数据同步支持的数据源、实时采集、FlinkSQL;同时加入Docker 部署,使用docker使Taier能进一步简化,轻量化部署依赖;集成OceanBase v1.2版本中,预计对OceanBase插件高优集成;
未来,Taier会持续在实战中自我迭代,也会积极汲取社区的力量,我们的开发计划已经在路上,每月也会有固定一到两场的线上直播分享,线下meetup也在积极计划中。大家保持关注,数栈希望与大家一起进步。
深入浅出聊Taier—大数据分布式可视化DAG任务调度系统的更多相关文章
- ElasticSearch大数据分布式弹性搜索引擎使用
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- ElasticSearch大数据分布式弹性搜索引擎使用—从0到1
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据Web可视化分析系统开发
下载地址 https://tomcat.apache.org/download-70.cgi 打开我们的idea 这些的话都可以按照自己的需求来修改 在这里新建包 新建一个java类 package ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 大数据时代的新BI系统架构发展趋势
商业智能(BI,Business Intelligence).它是一套完整的解决方式,用来将企业中现有的数据进行有效的整合,高速准确的提供报表并提出决策根据.帮助企业做出明智的业务经营决策. ...
- 大数据学习路线之linux系统基础搭建
学习大数据是必须掌握一定Linux知识的,工欲善其事,必先利其器.在学习之前,首先需要搭建Linux系统,本节将讲解VMware Workstation的安装和CentOS 7系统的安装. 1.2.1 ...
随机推荐
- 说说&和&&的区别?
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false.
- SpringBoot DevTools 的用途是什么?
SpringBoot 开发者工具,或者说 DevTools,是一系列可以让开发过程变得简便的工具.为了引入这些工具,我们只需要在 POM.xml 中添加如下依赖: 1 <dependency&g ...
- elasticsearch 了解多少,说说你们公司 es 的集群架构,索 引数据大小,分片有多少,以及一些调优手段 ?
面试官:想了解应聘者之前公司接触的 ES 使用场景.规模,有没有做过比较大 规模的索引设计.规划.调优. 解答: 如实结合自己的实践场景回答即可. 比如:ES 集群架构 13 个节点,索引根据通道不同 ...
- 为什么需要消息系统,mysql 不能满足需求吗?
1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据 丢失风险.许多消息队列所采用的& ...
- it-术语
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准. 因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS. 对应fetches/sec,即每秒的 ...
- MyBatis 实现一对多有几种方式,怎么操作的?
有联合查询和嵌套查询.联合查询是几个表联合查询,只查询一次,通过在 resultMap 里面的 collection 节点配置一对多的类就可以完成:嵌套查询是先查 一个表,根据这个表里面的 结果的外键 ...
- 为什么HTTP/3要基于UDP?可靠吗?
目录 前言 为什么转用UDP? HTTP/3解决了那些问题? 队头阻塞问题 QPACK编码 Header 参考 推荐阅读: 计算机网络汇总 HTTP/3竟然是基于UDP的!开始我也很疑惑,UDP传输不 ...
- 详解Mysql事务隔离级别与锁机制
一.概述 我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能 就会导致我们说的脏写. 胀读和不可重复读.幻读这些问题. 这些问题的本质都是数据库的多事务并 ...
- CAN总线系列讲座第六讲——SJA1000的滤波器设置
CAN总线的滤波器设置就像给总线上的节点设置了一层过滤网,只有符合要求的CAN信息帧才可以通过,其余的一概滤除. 在验收滤波器的帮助下,只有当接收信息中的识别位和验收滤波器预定义的值相等时,CAN 控 ...
- JavaScript の 内容属性(HTML属性attribute)和 DOM 属性(property)
[博文]内容属性(HTML属性)和 DOM 属性 标签: 博文 JavaScript 粗略解读(与jQuery做对比) 内容属性(HTML属性) : attribute DOM 属性(Element属 ...