新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置
1)设置ip地址
使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0 来修改ip地址,然后重启网络服务service network restart即可。
2)创建用户
大数据项目开发中,一般不直接使用root用户,需要我们创建新的用户来操作,比如kfk。
a)创建用户命令:adduser kfk
b)设置用户密码命令:passwd kfk
3)文件中设置主机名
Linux系统的主机名默认是localhost,显然不方便后面集群的操作,我们需要手动修改Linux系统的主机名。
a)查看主机名命令:hostname
b)修改主机名称
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=bigdata-pro01.kfk.com
4)主机名映射
如果想通过主机名访问Linux系统,还需要配置主机名跟ip地址之间的映射关系。
vi /etc/hosts
192.168.31.151 bigdata-pro01.kfk.com
配置完成之后,reboot重启Linux系统即可。
如果需要在windows也能通过hostname访问Linux系统,也需要在windows下的hosts文件中配置主机名称与ip之间的映射关系。在windows系统下找到C:\WINDOWS\system32\drivers\etc\路径,打开HOSTS文件添加如下内容:
192.168.31.151 bigdata-pro01.kfk.com
5)root用户下设置无密码用户切换
在Linux系统中操作是,kfk用户经常需要操作root用户权限下的文件,但是访问权限受限或者需要输入密码。修改/etc/sudoers这个文件添加如下代码,即可实现无密码用户切换操作。
vi /etc/sudoers
#添加如下内容即可
kfk ALL=(root)NOPASSWD:ALL
6)关闭防火墙
我们都知道防火墙对我们的服务器是进行一种保护,但是有时候防火墙也会给我们带来很大的麻烦。 比如它会妨碍hadoop集群间的相互通信,所以我们需要关闭防火墙。 那么我们永久关闭防火墙的方法如下:
vi /etc/sysconfig/selinux
SELINUX=disabled
保存、重启后,验证机器的防火墙是否已经关闭。
a)查看防火墙状态:service iptables status
b)打开防火墙:service iptables start
c)关闭防火墙:service iptables stop
7)卸载Linux本身自带的jdk
一般情况下jdk需要我们手动安装兼容的版本,此时Linux自带的jdk需要手动删除掉,具体操作如下所示:
a)查看Linux自带的jdk
rpm -qa|grep java
b)删除Linux自带的jdk
rpm -e --nodeps [jdk进程名称1 jdk进程名称2 ...]
2.克隆虚拟机并进行相关的配置
前面我们已经做好了Linux的系统常规设置,接下来需要克隆虚拟机并进行相关的配置。
1)kfk用户下创建我们将要使用的各个目录
#软件目录
mkdir /opt/softwares
#模块目录
mkdir /opt/modules
#工具目录
mkdir /opt/tools
#数据目录
mkdir /opt/datas
2)jdk安装
大数据平台运行环境依赖JVM,所以我们需要提前安装和配置好jdk。 前面我们已经安装了64位的centos系统,所以我们的jdk也需要安装64位的,与之相匹配
a)将jdk安装包通过工具上传到/opt/softwares目录下
b)解压jdk安装包
#解压命令
tar -zxf jdk-7u67-linux-x64.tar.gz /opt/modules/
#查看解压结果
ls
jdk1.7.0_67
c)配置Java 环境变量
vi /etc/profile
export JAVA_HOME=/opt/modules/jdk1.7.0_67
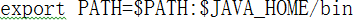
d)查看Java是否安装成功
java -version
java version "1.7.0_67"
Java(TM) SE Runtime Environment (build 1.7.0_67-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
3)克隆虚拟机
在克隆虚拟机之前,需要关闭虚拟机,然后右键选中虚拟机——》选择管理——》选择克隆——》选择下一步——》选择下一步——》选择创建完整克隆,下一步——》选择克隆虚拟机位置(提前创建好),修改虚拟机名称为Hadoop-Linux-pro-2,然后选择完成即可。
然后使用同样的方式创建第三个虚拟机Hadoop-Linux-pro-3。
4)修改克隆虚拟机配置
克隆完虚拟机Hadoop-Linux-pro-2和Hadoop-Linux-pro-3之后,可以按照Hadoop-Linux-pro-1的方式配置好ip地址、hostname,以及ip地址与hostname之间的关系。
新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置的更多相关文章
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
随机推荐
- 「题解」「2014 NOI模拟赛 Day7」冒泡排序
目录 题目 考场思考 正解 题目勾起了我对我蒟蒻时代的回忆,虽然我现在也蒟蒻 题目 点这里 可能链接会挂,在网上搜题目就有. 毕竟 \(BZOJ\) 有点老了... 考场思考 本来以为十分友善的一道题 ...
- java 抛出异常与finally的混用对于语句块的执行顺序的影响
代码如下: package test1; public class EmbededFinally { public static void main(String args[]) { int resu ...
- nikic / PHP-Parser 包的简单实用
解析PHP文件: <?php require 'vendor/autoload.php'; use PhpParser\ParserFactory; $code = file_get_conte ...
- docker运行安装mysql postgres
安装mysql [root@host1 ~]# docker images -a REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/mysql 5.7 4d ...
- C语言-断言
1 作用: 断言常做语言处理的高级形式,自动处理软件隐藏很深其且它手段不易发现的错误,快速进行异常定位.同时这也是软件单元测试必须的技术. 2 使用范围: 2.1放在函数入口对入口参数进行合法性检查( ...
- Nginx正则及 Location匹配!
1:Nginx location 规则匹配 ^~ 标识符匹配后面跟一个字符串.匹配字符串后将停止对后续的正则表达式进行匹配. 如:location ^~ /images/, 在匹配 ...
- python2.7 安装 Scipy
Numpy.scikit-learn可以直接 pip install xxx 但Scipy不能,在官网找到了安装方法: python -m pip install --user numpy scipy ...
- Interesting丨当我们用蚂蚁的视角看待世界
分享一组很有意思的图片~
- hdoj6703 2019 CCPC网络选拔赛 1002 array
题意 description You are given an array a1,a2,...,an(∀i∈[1,n],1≤ai≤n). Initially, each element of the ...
- git pull 之后怎么找回别覆盖掉的内容
[半夜吓出冷汗,git这个原理还真得好好学学] 不小心把本地写的东西pull了下,然后,全部覆盖掉了,以为就这样没了. 后面想到有“时光穿梭机”,“历史回滚”,在各大群友的帮助下,终于找回了. git ...