索引深入浅出(5/10):非聚集索引的B树结构在堆表
在“索引深入浅出:非聚集索引的B树结构在聚集表”里,我们讨论了在聚集表上的非聚集索引,这篇文章我们讨论下在堆表上的非聚集索引。
非聚集索引可以在聚集表或堆表上创建。当我们在聚集表上创建非聚集索引时,聚集索引键担当为行指针。在堆表里,文件号,页号和槽号(file id , page number and slot number)的组合在非聚集索引里担当为行指针。
我们来看下手头的一个例子。我们创建salesorderdetail表的副本,并在上面的productid和salesorderid 列创建创建非聚集索引。
DROP TABLE SalesOrderDetailHeap SELECT * INTO dbo.SalesOrderDetailHeap FROM AdventureWorks2008r2.Sales.SalesOrderDetail
GO
CREATE UNIQUE INDEX Ix_ProductId ON SalesOrderDetailHeap(ProductId,Salesorderid)
收集非聚集索引相关信息:
TRUNCATE TABLE dbo.sp_table_pages
INSERT INTO sp_table_pages EXEC('DBCC IND(IndexDB,SalesOrderDetailHeap,2)')
GO SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3720,3) DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页 DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3908,3)--叶子节点/索引页
SELECT * FROM dbo.sp_table_pages WHERE IndexLevel=0 --叶子节点/索引页
根据上述信息进行非聚集索引逻辑示意图的绘制:
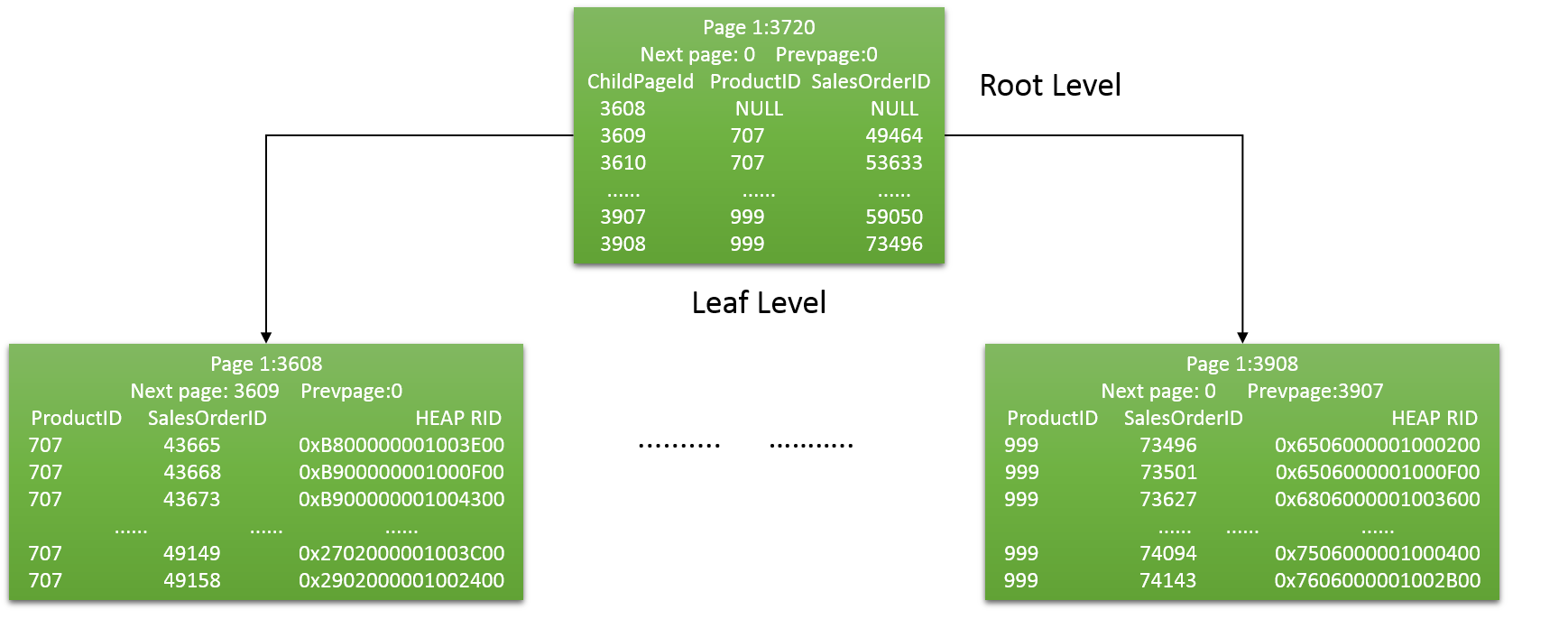
现在我们来分析下SQL Server如何存储堆表的非聚集索引,首先我们通过DBCC IND命令查看非聚集索引的页分配情况,最后一个参数,2是Ix_ProductId的索引号。
DBCC ind('IndexDB','SalesOrderDetailHeap',2)
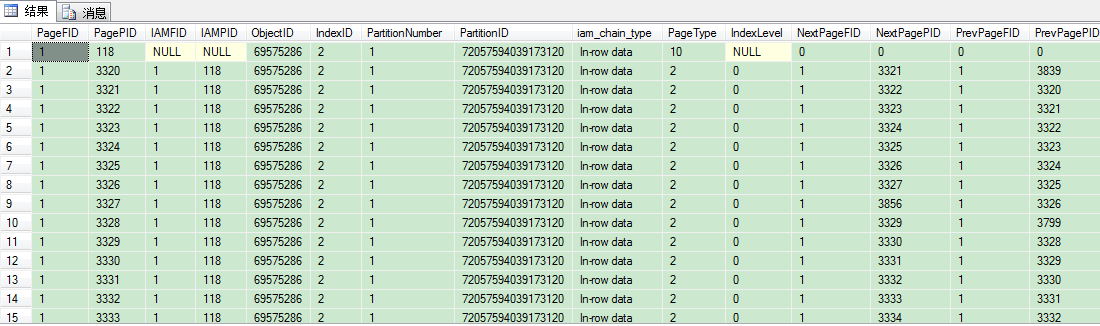

一共返回298条记录,包括1个IAM页,288个索引页,我们用下列语句找下根层的页号:
SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC

可以看到,indexlevel列最大值1的页号是3270,这个页就是根页,因为indexlevel列最大值是1,所以这个堆表的非聚集索引的B树结构只有2层,即根层和叶子层,也就是说288个索引页中,1个页是根层的根页(也是索引页),287个页是叶子层的索引页。我们来看看3270页的信息。
DBCC TRACEON(3604)
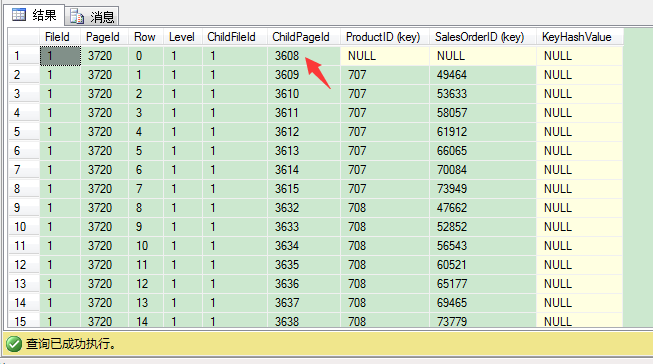
DBCC PAGE(IndexDB,1,3720,3)
输出结果,和聚集表里的非聚集索引的根页结构是一样的。
我们来看看叶子层的3608页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页
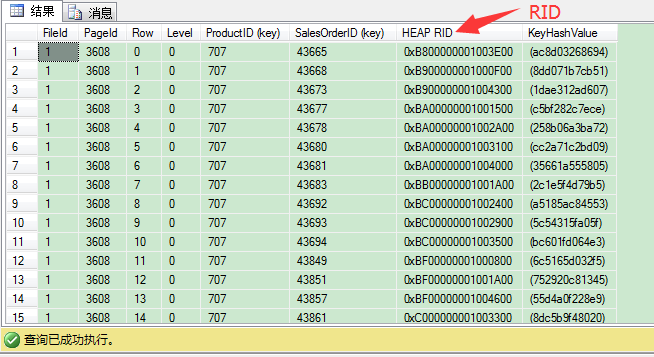
在聚集表的非聚集索引的叶子层,聚集键与非聚集键一齐加入了叶子层的页。这里我们没有聚集索引,索引SQL Server加了个行标识号(8 bytes大小),由文件号(2 bytes),页号(4 bytes)和槽号(2 bytes)组合而成。
从上图我们可以清楚看出,productid值为707,salesorderid值为43665的记录完整信息,可以在HeapRID 0xB800000001003E00位置找到。下面的查询可以帮我们把RID转为文件号:页号:槽号(FileId:PageId:SlotNo)格式。
DECLARE @HeapRid BINARY(8)
SET @HeapRid = 0xB800000001003E00
SELECT
CONVERT (VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 6, 1)
+ SUBSTRING(@HeapRid, 5, 1)))
+ ':'
+ CONVERT(VARCHAR(10),
CONVERT(INT, SUBSTRING(@HeapRid, 4, 1)
+ SUBSTRING(@HeapRid, 3, 1)
+ SUBSTRING(@HeapRid, 2, 1)
+ SUBSTRING(@HeapRid, 1, 1)))
+ ':'
+ CONVERT(VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 8, 1)
+ SUBSTRING(@HeapRid, 7, 1)))
AS 'Fileid:Pageid:Slot'

1:184:62表示文件号:1 ,页号:184 ,槽号:62。我们来看看184页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,184,3)
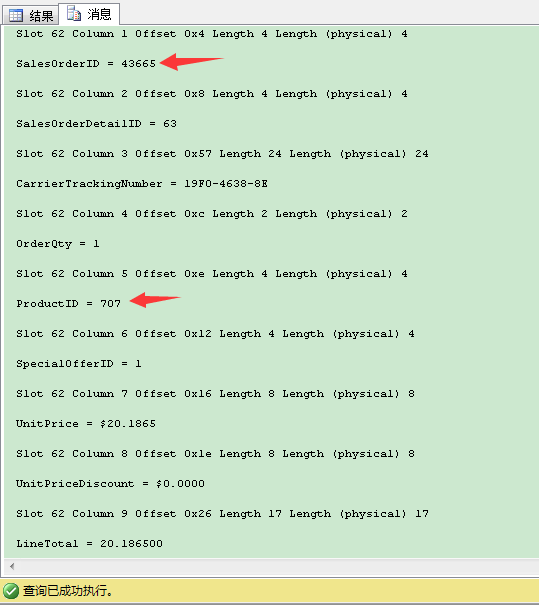
从输出我们可以看到,productid值为707,salesorderid值为43665的记录所有列可以在槽号62找到,与1:184:62表示文件号:1 ,页号:184 ,槽号:62完全一致。
我们通过下面的查询看看SQL Server如何使用非聚集索引查找堆表上的数据,点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

SQL Server需要进行2次I/O操作到达非聚集索引的叶子层,1次I/O操作通过使用RID查找(堆)拿到剩下的数据。执行计划如下所示:
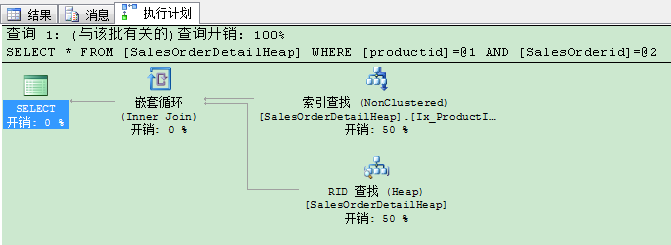
即使我们将查询语句修改为,只要 ProductId,SalesOrderid,SalesorderDetailId 这3列,SQL Server还是要进行键查找(Key lookup)操作。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665 SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid,SalesOrderDetailID FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

这是因为,SalesorderDetailId列没有定义为聚集键,在非聚集索引的叶子层没有这列。为了避免键查找(key lookup)操作,我们需要将列限制到只有非聚集索引键(ProductKey ,salesorderid)。
SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

如上图所示,只有非聚集索引查找操作,没有键查找(Key lookup)操作了。
参考文章:
索引深入浅出(5/10):非聚集索引的B树结构在堆表的更多相关文章
- 索引深入浅出(3/10):聚集索引的B树结构
在SQL Server里,有2种表是以存储为基础的.有聚集索引的表叫聚集表,没有聚集索引的表叫堆表.在上一篇文章,我们讨论了堆表的特性和存储结构.在这篇文章里,我们来看下聚集表. 有聚集索引的表叫聚集 ...
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
- 索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引.我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构. 非聚集索引的逻辑呈现 简单来说,非聚集索引是表的子 ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
随机推荐
- 重量级Orchard模块发布 - 模块生成工具RaisingStudio.ModuleGenerator
可以从这里下载安装(http://gallery.orchardproject.net/List/Modules/Orchard.Module.RaisingStudio.ModuleGenerato ...
- 图片下载缓存防止OOM
一 ImageManager ImageMemoryCache(内存缓存).ImageFileCache(文件缓存) 关于Java中对象的软引用(SoftReference),如果一个对象具有 ...
- 再谈扩展方法,从string.IsNullOrEmpty()说起
string.IsNullOrEmpty()这个方法算得上是.net中使用频率最高的方法之一.此方法是string的一个静态方法,类似的静态方法在string这个类中还有很多.那么这样的方法作为静态方 ...
- Javascript事件机制兼容性解决方案
本文的解决方案可以用于Javascript native对象和宿主对象(dom元素),通过以下的方式来绑定和触发事件: 或者 var input = document.getElementsByTag ...
- 如何基于纯GDI实现alpha通道的矢量和文字绘制
今天有人在QQ群里问GDI能不能支持带alpha通道的线条绘制? 大家的答案当然是否定的,很多人推荐用GDI+. 一个基本的图形引擎要包括几个方面的支持:位图绘制,文字绘制,矢量绘制(如矩形,线条). ...
- Linux下安装SVN服务端小白教程
安装 使用yum安装非常简单: yum install subversion 配置 创建仓库 我们这里在/home下建立一个名为svn的仓库(repository),以后所有代码都放在这个下面,创建成 ...
- ASP.NET MVC 随想录—— 使用ASP.NET Identity实现基于声明的授权,高级篇
在这篇文章中,我将继续ASP.NET Identity 之旅,这也是ASP.NET Identity 三部曲的最后一篇.在本文中,将为大家介绍ASP.NET Identity 的高级功能,它支持声明式 ...
- Visual Studio 2015速递(1)——C#6.0新特性怎么用
系列文章 Visual Studio 2015速递(1)——C#6.0新特性怎么用 Visual Studio 2015速递(2)——提升效率和质量(VS2015核心竞争力) Visual Studi ...
- 项目管理师prince2
项目管理师prince2 PRINCE2并不适合用于管理商业活动中的日常事物.商业日常事务通常是指组织机构日常运营中需要完成的那些工作.例如,公司it系统的维护,宾馆的房间整理,或者运营公司的客户呼叫 ...
- 爱上MVC系列~带扩展名的路由失效问题
回到目录 对MVC中,对URL进行重写变得非常方便,你只要设置相应的路由规则即可完成,但进行MVC3后,发现设置了以下路由,系统具体不认 routes.MapRoute( name: "De ...