SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract
- 提出了一种无监督单目深度估计和相机运动估计的框架
- 利用视觉合成作为监督信息,使用端到端的方式学习
- 网络分为两部分(严格意义上是三个)
- 单目深度估计
- 多视图姿态估计
- 解释性网络(论文后面提到训练了第三个网络)
2. Introduction
- 计算机几何视觉难以重建真实的场景模型
- 由于非刚性、遮挡、纹理缺失等情况的存在
- 人类在很短的时刻可以推断自我运动以及三维场景的结构,为什么?
- 一个假设就是人类在移动中通过观察大量的场景,已经进化出一个对真实世界丰富的、具有结构层次的理解力。通过这些上百万次的观察,人们已经认识到了世界的规律性—路是平的,大楼是直立的等,于是在进入一个新的场景,即使通过一个单目图像。我们也可以运用这些先验知识来识别场景。
- 很自然地,我们就想到通过训练一个观察图像序列的网络来模拟这种能力,这个网络的目的在于通过预测相机运动和场景结构来解释观察到的内容。
- 端到端的方式。直接从输入的像素来估计相机运动(6个自由度的变化矩阵)和场景结构(每个像素的深度)
- 视觉合成作为度量。
- 无监督的方法。直接使用图像序列进行训练,不需要人工标记甚至相机运动信息。
- 本文方法建立一个观点的基础上:只有当场景的中间预测与相机姿态与真实场景一致的时候,几何视觉合成系统才会表现的很好。
- 但是对于某些场景(例如纹理缺失),几何和姿态估计的不好会导致视觉合成的错误,由此相同模型在面对另一类场景(布局和场景结构更多样)时,会非常失败。
- 本文的目标是构建整个视觉合成的流程,作为CNN的推理过程,通过学习深度和相机姿态的中间估计,以达到网络解释内容与真实世界一致的效果。
3. Related Work
3.1 SFM
3.2 Warping-based view synthesis
3.3 Learning single-view 3D from registered 2D views
3.4 Unsupervised/Self-supervised learning from video
4. 方法
4.1 视觉合成作为监督
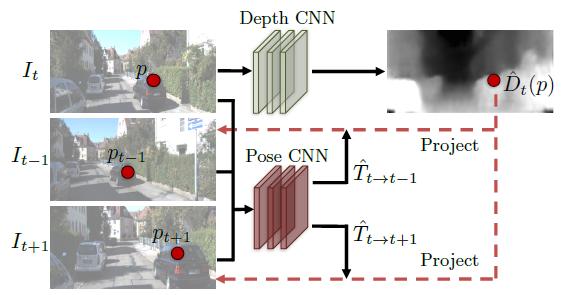
图1:基于视觉合成的有监督训练流程
本文深度和姿态预测的监督信息来自于视觉合成:给定一个场景的输入图片,合成该场景在另一个相机姿态下的新的视角。给定输入图片中每一个像素的深度,再加上该图片某个相邻视角下相机的姿态以及可见性,我们可以合成同一场景新的视角图片。可见性由本文的explaination网络完成,视角合成可以由CNN完成。
假设\(<I_1,\cdots,I_N>\)表示一个训练图像序列,序列中的一帧作为目标视角\(I_t\),其余的作为源视角\(I_s(1 \leq s \leq N, s \neq t)\).视觉合成的目标函数可以表示为:
\[\mathcal{L}_{vs} = \sum_{s} \sum_{p} |I_t(p)-\hat{I}_s(p)| \tag{1}\]
这里\(p\)表示一个像素坐标,\(\hat{I}_s\)是基于深度图像及render方式将输入视角\(I_s\)翘曲(warp)到目标视角坐标系的图像
注:
可见性(visibility):指两个不同的目标视图在生成新视图的过程中,warp到新视角的同一点。当新视角的一个3D点被另一个3D点遮挡的时候,就会出现这种情况。
4.2 基于图像渲染的可微分深度
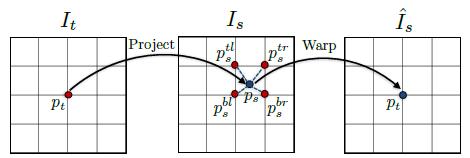
图2:可微分图像翘曲描述。对于target view的每个像素点\(p_t\),首先基于预测的深度和姿态将其投影至source view,然后利用双线性差值获得点\(p_t\)在翘曲后图像\(\hat{I}_s\)的像素值
考虑两个相机和一个三维点\(P\),\(P\)在第一、第二个视角的投影坐标分别为\(p_s\),\(p_t\)。假设世界坐标系是第一个相机的相机坐标系,透视投影变换公式如下:
\[ Z_t p_t = \begin{bmatrix} u \\ v \\ 1 \end{bmatrix}_{t} = KP \tag{2}\]
\[Z_s p_s = \begin{bmatrix} u \\ v \\ 1 \end{bmatrix}_{s} = K \hat{T}_{t \to s} P \tag{3}\]
其中\(Z_t\)、\(Z_s\)分别是点\(p_t\)、\(p_s\)的深度,\(K\)是相机的内参矩阵(假设内参一致),\(\hat{T}_{t \to s}\)表示相机1到2的相对位姿。基于\(p_t\)的深度值(所以该方法称为DBIR,又称为3D image warping),变换公式(2)得到:
\[P=Z_t K^{-1} p_t \tag{4}\]
将公式(4)代入公式(3),得到:
\[Z_s p_s =Z_t K \hat{T}_{t \to s} K^{-1} p_t \tag{5}\]
公式(5)可以看成:我们只需要知道新视角(虚拟的,3D image warping得到的)相对于参考帧所在相机的姿态变换\(\hat{T}_{t \to s}\),相机的内参,以及参考帧每个像素的深度值,就可以通过公式(5)合成一个新的虚拟视角。这里的原理详见参考[1]。所以得到论文中的公式,见公式(6),\(\hat{D_t}\)表示\(p_t\)的深度值。
\[p_s \sim K \hat{T}_{t \to s} \hat{D_t} (p_t) K^{-1} p_t \tag{6}\]
因为透视变换得到的图像坐标\(p_s\)是连续的(小数),因此无法获得\(p_s\)的灰度值。本文根据双线性插值获得\(p_s\)处的灰度值\(I_s(p_s)\),
\[\hat I_s=I_s(p_s)=\sum_{i \in \{t,b \}, j \in \{ l,r\}} w^{ij} I_s(p_s^{ij}) \tag{7}\]
4.3 克服模型局限性建模
- 建模基于三个假设
- 场景是静态的,没有动态的物体;
- 目标视角和源视角之间没有遮挡和离合的物体;
- 物体表明是朗伯表面(漫反射)以保证图像一致性误差有意义。
- 解释性预测网络(explainability prediction network)
- 由于以上三个假设并不完全满足,因此为了提高系统的鲁棒性,增加一个训练网络
- 与深度、姿态网络联合训练
- 输出:每对目标视角-源视角每个像素的soft mask$ \hat{E_S}$,表示
- 对公式加一个置信参数(有点类似直接法SLAM的优化方程)
\[\mathcal{L}_{vs}=\sum_{<I_1,\cdots,I_N> \in \mathcal{S}} \sum_{p} \hat{E_s}(p) |I_t(p) - \hat{I_s}(p)| \tag{8}\] - 最小化loss函数时候,很可能会让\(\mathcal{L}_{reg}(\hat{E}_{s})\)为0,那么整个loss函数就没有意义了;
- 为了避免这种情况,需要对公式(8)添加一个正则项\(\mathcal{L}_{reg}(\hat{E}_{s})\),通过最小化每个像素点处与1之间的交叉熵损失,来避免\(\hat{E}_{s}\)为0;
- 换句话说,鼓励网络最小化视觉合成的目标函数,但允许一定程度的松弛度以磨合网络未考虑的因素。
4.4 克服梯度局限性
- 梯度来源于\(I(p_{t})\)与相邻四个点\(I(p_s)\)的像素差
- 如果利用ground-truth深度和姿态得到的投影像素\(p_s\)(这是一个精确值)位于低纹理区域,或当前估计不够准确时,网络会一直训练。
- 两种典型的处理这种问题的方法
- 使用带有bottleneck层的encoder-decoder网络架构,从而约束深度网络的输出平滑,并且促使有意义的梯度区域传给周围像素;
- 明确多尺度和平滑损失:允许梯度能从更大的区域得到;
- 本文使用了第二种方法。
- 为了平滑损失,在预测深度图时,最小化二阶梯度的\(L_1\)范式
- 最终的目标函数变为:
\[\mathcal{L}_{final}=\sum_{l} \mathcal{L}_{vs}^{l}+\lambda_{s} \mathcal{L}_{smooth}^{l} + \lambda_{e} \sum_{s} \mathcal{L}_{reg}(\hat{E}_{s}^{l}), \tag{9}\]- \(l\)表示不同的图像尺度,\(s\)表示源图像,\(\lambda_{s}\)和\(\lambda_{e}\)分别是深度平滑loss和解释性网络正则化的权值。
4.5 网络架构
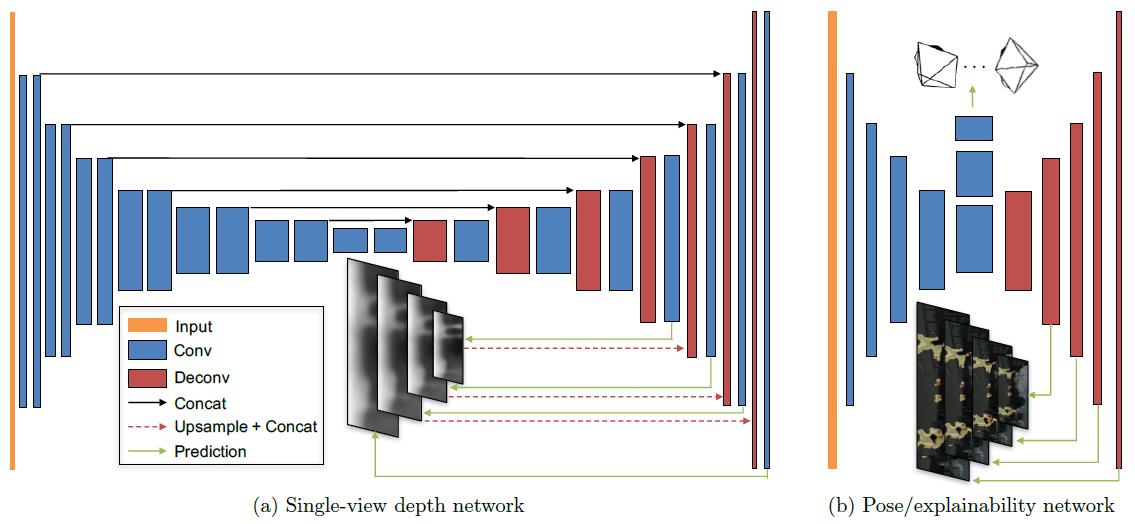
图3:网络架构
- 单目深度估计
- 输入:目标视角(target view)
- 采用DispNet结构;
- 采用带有跳跃连接(skip connections)的Encoder-Decoder架构,multi-scale端预测深度;
- 除了深度预测层,所有层都采用ReLU函数激活;
- 深度预测层采用\(\frac{1}{\alpha * sigmoid(x)+ \beta}\),这里的\(\alpha = 10\),\(\beta = 0.1\),以保证预测深度为正值,且在一个合理范围内。
- 除了前四层分别采用7*7, 7*7, 5*5, 5*5的卷积核,其余都采用3*3的卷积核
- 姿态估计
- 输入:目标视角(target view)和所有源视角(source view)
- 输出:目标视角与每一个源视角的相对姿态
- 7个卷积层,步长为2,除了前两个卷积层和最后两个反卷积(预测)层的卷积核分别是7*7, 5*5, 5*5, 7*7之外,其余都采用3*3的卷积核
- \(6*(N-1)\)个1*1的卷积层(对应于6个自由度:3个欧拉角和3个平移量)
- 第一个卷积层的输出通道为16
- 解释性网络
- 与pose网络共享前五个econding层
- 5个反卷积层的多尺度预测
- 除了预测层没有激活函数,所有卷积层/反卷积层都使用ReLU激活函数
- 每个预测层的输出通道为\(2 * (N-1)\),每两个通道都使用softmax归一化,以获得每个source-target对的解释性预测(第二个通道归一化为\(\hat{E}_{s}\),用于计算公式5的loss)
5. 实验
主要使用了KITTI作衡量基准,同时使用了Make3D数据集以评估模型的泛化能力。
训练:
- Tensorflow架构(github也有PyTorch实现)
- \(\lambda_{s}\)设为\(0.5 / l\)(\(l\)是下采样因子),同时\(\lambda_{e}=0.2\)
- 每层都使用Batch Normalization和ReLU
- 优化器使用Adam,\(\beta_{1}=0.9\),\(\beta_2=0.999\)
- 学习率:0.002,mini-batch的size为4,迭代次数150K
- 单目相机拍摄的图像序列,训练时将图片设为128$\times$416
5.1 单目深度估计
- 使用KITTI数据集训练
- 排除所有帧中平均光流小于1个像素的静态场景作训练
- 固定图像序列长度为3帧,将中间帧作为target view,中间帧的\(\pm 1\)帧作为source view
- 一共44540个序列,40109用于训练,4431用于测试。
6. 讨论
考虑了三个未来工作:
- 本文目前的框架没有明确估计动态场景和遮挡(尽管explainability已经将其考虑在内),这两者都是三维场景理解的关键因素。通过motion segmentation建模或许是解决方法之一
- 目前的框架假设内参已知,这限制了对网上视频的应用,未来考虑解决这一问题
- 深度图是三维场景的一种简单表示方法,考虑应用更好的表示,例如体素。
另一个有趣的方向是探究由本文学习得到的系统更详细的细节,尤其是姿态估计时使用某种图像对应,深度估计时识别场景和对象的共同特征,即探究语义分割、对象检测等对本文框架的影响。
参考
[1] Christoph Fehn. Depth-image-based rendering (DIBR), compression, and transmission for a new approach on 3D-TV
[2] https://blog.csdn.net/wangshuailpp/article/details/80098059
SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video的更多相关文章
- 【论文笔记】Learning Fashion Compatibility with Bidirectional LSTMs
论文:<Learning Fashion Compatibility with Bidirectional LSTMs> 论文地址:https://arxiv.org/abs/1707.0 ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文笔记:Learning wrapped guidance for blind face restoration
这篇论文主要是讲人脸修复的,所谓人脸修复,其实就是将低清的,或者经过压缩等操作的人脸图像进行高清复原.这可以近似为针对人脸的图像修复工作.在图像修复中,我们都会假设退化的图像是高清图像经过某种函数映射 ...
- 深度学习论文笔记-Deep Learning Face Representation from Predicting 10,000 Classes
来自:CVPR 2014 作者:Yi Sun ,Xiaogang Wang,Xiaoao Tang 题目:Deep Learning Face Representation from Predic ...
- 论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking AAAI-2019 Paper:http://faculty.ucmer ...
- 论文笔记:Learning regression and verification networks for long-term visual tracking
Learning regression and verification networks for long-term visual tracking 2019-02-18 22:12:25 Pape ...
- 论文笔记: Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation
Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation 2018-11-03 09:58:58 Paper: http ...
- 论文笔记:Learning Dynamic Memory Networks for Object Tracking
Learning Dynamic Memory Networks for Object Tracking ECCV 2018Updated on 2018-08-05 16:36:30 Paper: ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
随机推荐
- -moz、-ms、-webkit
1.-moz代表firefox浏览器私有属性 2.-ms代表IE浏览器私有属性 3.-webkit代表safari.chrome私有属性 需要设置这个的样式: transform,border-rad ...
- H5 应用程序缓存(离线缓存)
离线缓存这个功能的实现有以下步骤: 1,以nginx做web服务器为例,在mime.types文件中添加一行:text/cache-manifest manifest,作用是为了让服务器识别该 ...
- Entertainment Box Gym100781E(数据结构+贪心)
Entertainment Box 题意: 有n个节目,每个节目给出开始时间(st)和结束时间(en): 有k个内存条这k个内存条可以同时存储节目.如果节目j的开始时间stj 大于等于节目i的结束时 ...
- Mac在python3环境下安装virtualwrapper遇到的问题
前言 我在使用mac安装virtualwrapper的时候遇到了问题,搞了好长时间,才弄好,在这里总结一下分享出来,供遇到相同的问题的朋友使用,少走些弯路. 问题说明: Mac默认系统的python2 ...
- Python之类方法,lambda,闭包简谈
类方法,lambda,闭包 类方法 lambda 闭包 类方法 classmethod staticmethod instancemethod 类方法 类方法,通过装饰器@classmethod来标明 ...
- copy the content of a file muliptle times and save as ordered files:
input: transient.case outputs: transient_1.case, transient_2.case,...transient_101.case ********** n ...
- 《hello-world》第八次团队作业:Alpha冲刺-Scrum Meeting 5
项目 内容 这个作业属于哪个课程 2016级计算机科学与工程学院软件工程(西北师范大学) 这个作业的要求在哪里 实验十二 团队作业8:软件测试与Alpha冲刺 团队名称 <hello--worl ...
- 【Codeforces 446A】DZY Loves Sequences
[链接] 我是链接,点我呀:) [题意] 让你找一段连续的区间 使得这一段区间最多修改一个数字就能变成严格上升的区间. 问你这个区间的最长长度 [题解] dp[0][i]表示以i为结尾的最长严格上升长 ...
- VI 快捷操作 【持续更新】
2014-9-23 一. 大小写转换 vim中大小写转化的命令是 gu或者gU 形象一点的解释就是小u意味着转为小写:大U意味着转为大写. 剩下的就是对这两个命令的限定(限定操作的行,字母,单词) ...
- ZooKeeper官方文档资源
一般来说官方的文档是最权威的. 入口:http://zookeeper.apache.org/ 在右侧即可进入相应版本文档: 如果想要看主干的文章,入口如下,主干是最稳当的版本:http://zook ...