python3.x爬取美团信息
在之前的文章中,笔者有提到,我们要在实践中去学习python,笔者有天就想着要不要爬点东西呢,跃跃欲试的节奏啊,想来想去,想到美团了,那么首先笔 者想给自己确定一个目标,就是我要爬什么样的数据,我要爬美团的哪些东西。笔者首先确定了笔者想要爬去的界 面,http://bj.meituan.com/。就是美团网在北京的团购首页,获取首页的团购,团购项目的介绍,团购售价,销量。
1.首先确定要用的模块,<1.>urrlib,os,re三个模块,
2.要想获得数据,并且一一对应起来,那么用到循环的嵌套(一开始卡壳,后来咨询得到启发),
3.获取网页的所有数据,爬去下来
4.分析这些想要或许的模块怎么找出来,
5.找出相对于的正则来匹配,
6.获取数据,并且找到对应的数值
7.利用循环,并且配合字典的使用,将数据完整的获取下来,
8.保存到相应的文档中
9.关闭文档,
10.提示数据保存成功,结束爬去。
由于这是第一次采取这么多的信息,之前只是爬个图片啥的,所以笔者还是十分小心的去审查每一个元素,在这里推荐利用火狐浏览器,感觉是真的好用使用Firebug插件审查元素。
查看元素后,可以获得这个网站的编码形式是utf-8,这对于我们爬取数据也是关键的。
在一开始呢,笔者还打开了一款软件,fiddler,抓包
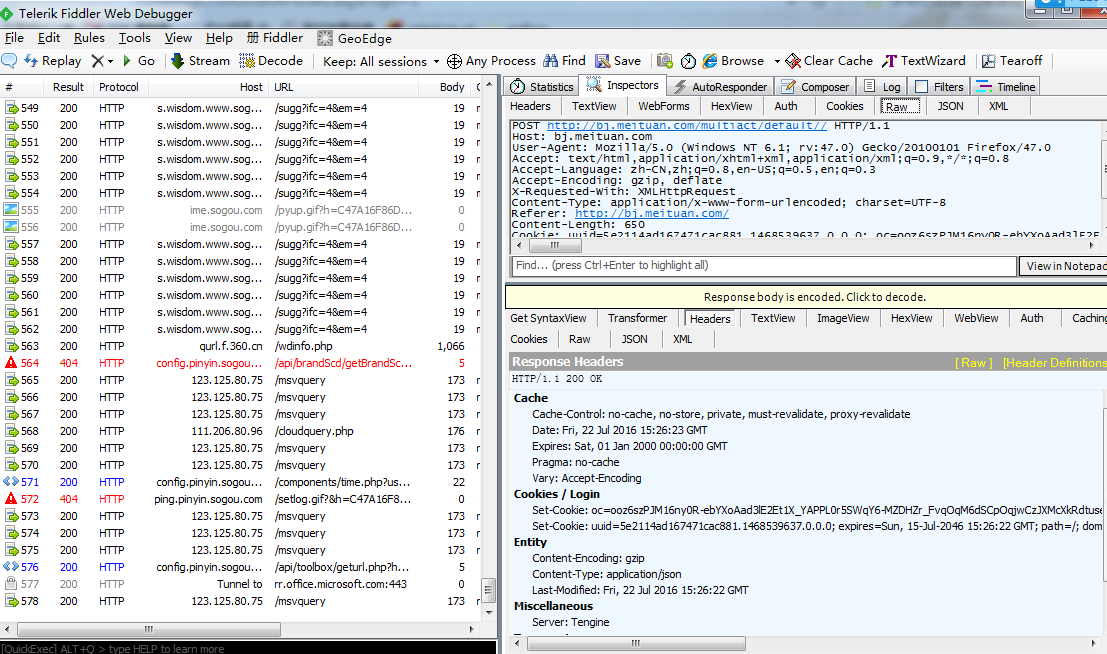
这些信息还是很多的,由于笔者截图的时候碰到了网络的原因,但是笔者还是找到了自己想要的信息,这样可以在自己的代码中加入伪装浏览器的信息,那么接下来要做的事情就是定位我们想要找的数据。
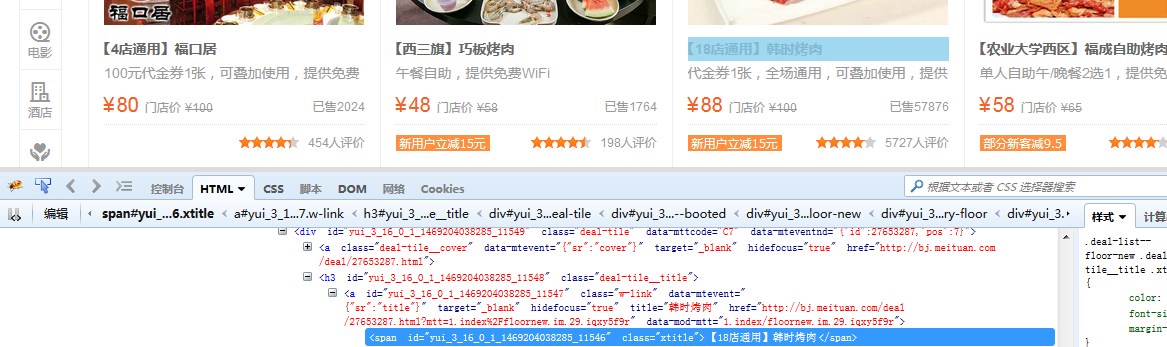
分析首页的团购信息,我们可以根据多个来确认这个信息的唯一标识符,<span>标签中并且有class="xtitle"< /span>中间文字,那么我们的正则表达式就出来了,r'<span
class="xtitle">(.+?)</span>'(正则太难,笔者一个个试出来的)
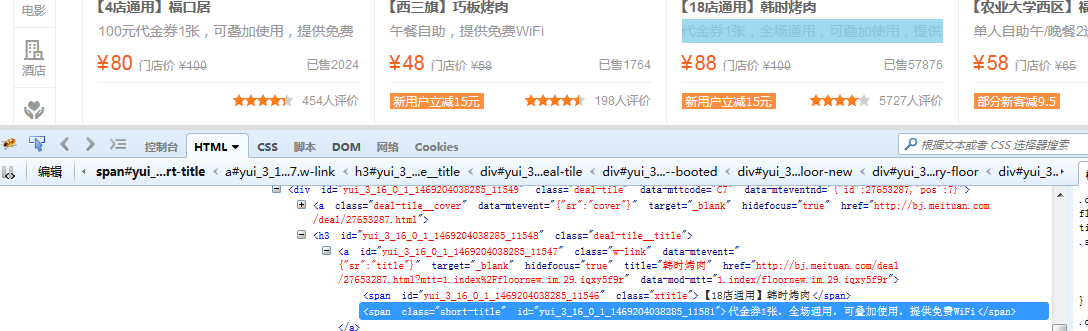
描述也是<span>标签并且 class="short-title",</span>的文字,那么很快就匹配到了,正则出来了,r'class="short-title">(.+)</span>'
后面的就是依次类推。完成这个,那么我们就开始写我们的爬虫程序,导入我们想要用的模块,定义我们想要用的变量。爬去,匹配,然后循环得出来我们的结果,写入文档。代码如下
#作者:雷子
#qq:952943386
#邮箱:leileili126@163.com
#欢迎大家来点评,有问题可以进行沟通
import urllib.request
import os
import re
file=open(r'meituancde.txt','w')
url="http://bj.meituan.com/"
headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X
10.10; rv:47.0) Gecko/20100101 Firefox/47.0"}
req=urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
title_reg=r'<span
class="xtitle">(.+?)</span>' #匹配团购
jianjie_reg=r'class="short-title">(.+)</span>' #匹配团购简介
sellnum_reg=r'<strong class="num">(.+)</strong>' #销售的数量
pire_reg=r'<strong>(.+)</strong>' #团购的售价
title_list = re.findall(title_reg,html)
jianjie_list=re.findall(jianjie_reg,html)
sellnum_list=re.findall(sellnum_reg,html)
pire_list=re.findall(pire_reg,html)
meitu={}
i = 0
for title in title_list:
meitu['团购'] =title_list[i]
for jianjie in jianjie_list:
meitu['简介']=jianjie_list[i]
for sellum in sellnum_list:
meitu['销量']=sellnum_list[i]
for pire in
pire_list:
meitu['美团售价']=pire_list[i]
i+=1
print(meitu)
if len(meitu) !=0:
file.write(str(meitu))
file.write("\n")
file.close
print("写入正确")
代码 百度云
python3.x爬取美团信息的更多相关文章
- python3+beautifulsoup4爬取汽车信息
import requests from bs4 import BeautifulSoup response = requests.get("https://www.autohome.com ...
- Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考 主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过 ...
- python爬取“美团美食”汕头地区的所有店铺信息
一.目的 获取美团美食每个店铺所有的评论信息,并保存到数据库和本地 二.实现步骤 获取所有店铺的poiId 首先观察详情页的url,后面是跟着一串数字的,而这一串数字代表着每个店铺特有的id号,我们称 ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- python爬取酒店信息练习
爬取酒店信息,首先知道要用到那些库.本次使用request库区获取网页,使用bs4来解析网页,使用selenium来进行模拟浏览. 本次要爬取的美团网的蚌埠酒店信息及其评价.爬取的网址为“http:/ ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- python学习之——爬取网页信息
爬取网页信息 说明:正则表达式有待学习,之后完善此功能 #encoding=utf-8 import urllib import re import os #获取网络数据到指定文件 def getHt ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
随机推荐
- pyQt 每日一练习 -- 登录框
#coding=utf-8 #第一个练习,登录框 import sys from PyQt4 import QtGui,QtCore #登录框 class LoginBox(QtGui.QWidget ...
- JQuery实现的动态Table(转)
这个例子做的不错,转载备份. 原文:http://www.cnblogs.com/linjiqin/archive/2013/06/21/3148181.html $("#mytable t ...
- 详解keil采用C语言模块化编程时全局变量、结构体的定义、声明以及头文件包含的处理方法
一.关于全局变量的定义.声明.引用: (只要是在.h文件中定义的变量,然后在main.c中包含该.h文件,那么定义的变量就可以在main函数中作为全局变量使用) 方法1: 在某个c文件里定义全局变量后 ...
- 关于诺顿身份安全2013独立版(Norton Identity Safe)
现在身份安全这货好像从诺顿的套装当中独立出来了,出了中文版.其实诺顿的Web信誉做得还是不错的,当然天朝不要有太大期望.只是公认的做web信誉做得最好的应该就是趋势科技和诺顿,所以诺顿的身份安全也许还 ...
- [iOS微博项目 - 3.3] - 封装网络请求
github: https://github.com/hellovoidworld/HVWWeibo A.封装网络请求 1.需求 为了避免代码冗余和对于AFN框架的多处使用导致耦合性太强,所以把网 ...
- UVa 1620 Lazy Susan (找规律)
题意:给 n 个数,每次可以把4个连续的数字翻转,问你能不能形成1-n的环状排列. 析:找一下奇偶性,写几个数试试,就会找到规律. 代码如下: #include <cstdio> #inc ...
- thinkphp利用行为扩展实现监听器
1.在User/login函数中添加如下代码 tag('login_listener',$result); //alert('success', '恭喜,登录成功', U('xx/yy')); 去掉跳 ...
- VS2010编译器下针对C#和C++的opencv的配置方法
我们大家都知道opencv是针对C.C++编写的,没有独立的编译调试工具.所以今天就捣鼓了一下在xp vs2010下配置C++和C#环境下的opencv.请大家一步一步的按步骤操作.本人亲自鉴定可行. ...
- 在WindowsServer2008服务器上安装SQLServer2008R2
登录服务器 使用远程桌面登录Windows Server 2008 安装前的准备工作 下载SQL Server安装程序 下载Microsoft SQL Server2008 R2 RTM - Ex ...
- 转载:div和flash层级关系问题
转自:http://sin581.blog.163.com/blog/static/860578932012813112334404/ 问题: ie下默认好像div层级没有flash层级高,也 ...