Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】所谓爬虫,就是通过编程的方式自动从网络上获取自己所需的资源,比如文章、图片、音乐、视频等多媒体资源。通过一定的方式获取到html的内容,再通过各种手段分析得到自己所需的内容,比如通过BeautifulSoup对网页内容进行解析提取。
本文通过==selenium==的==webdriver==模拟浏览器来浏览网页,通过==lxml==库解析得到咱所需的内容。下面开始我们的爬虫工作。
首先,安装好我们爬网所需的开发环境,我的开发环境如下:
- win7 x64中文版
- Visual Studio Code 1.27.2(用于作为Python的编辑器,通过插件可以支持多种语言的开发)
- Anaconda3.5.2-64bit(选择Python3版本)
- 本系列演示过程所用到的python环境以及第三方库:
- python 3.6.5 ==Anaconda预安装==
- selenium 3.14.0 ==Anaconda手动安装==
- lxml 4.2.1 ==Anaconda预安装的不包含etree,需要卸载重装,见文末方法==
- pip 10.0.1 ==Anaconda预安装==
- PyExecJS ==Anaconda没有,需要cmd执行pip安装==
这里为了方便管理Python里面的各种插件的依赖关系,我选择的是Py集成管理工具Anaconda,就像我们其它语言开发使用Maven、Gradle作为依赖库版本管理工具一样,节省自己的时间减少出错的几率。(当然你很强,也可以自己单独安装Python以及本文所用到的各种依赖包,只要不出错就好)
安装步骤:
win7系统就不用说了,大家都懂的
Visuan Studio Code(本系列后续文章内统一简称vs code)的安装也是很easy,下载后一路下一步完成就行
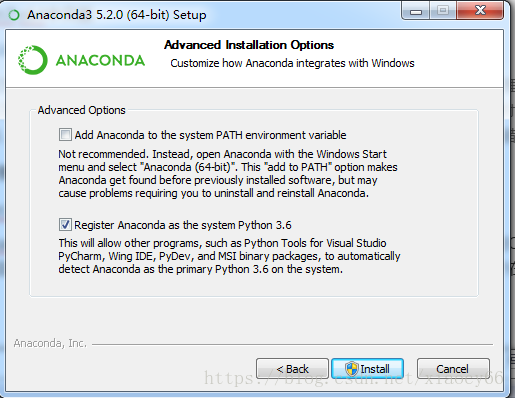
- Anaconda3.5也是从官网下来安装包双击执行一路下一步,我是默认安装在C:\ProgramData\Anaconda3,并且在安装过程中勾选了把这个安装目录作为系统Python的安装目录,
但是查了系统环境变量Path,并没有发现这个在里面,所以安装完成后我们在cmd里面输入python以及pip,是提示命令找不到的。所以不管了,干就完了,咱自己手动把以下路径添加到系统环境变量Path的值里面:
- C:\ProgramData\Anaconda3\Scripts
- C:\ProgramData\Anaconda3
- 不懂配置环境变量操作的自行du一下~
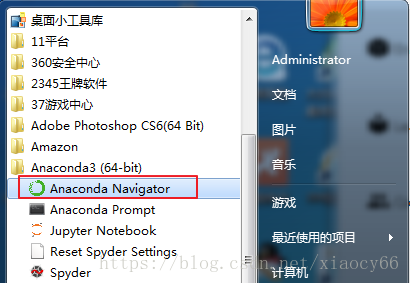
- 启动Anaconda:
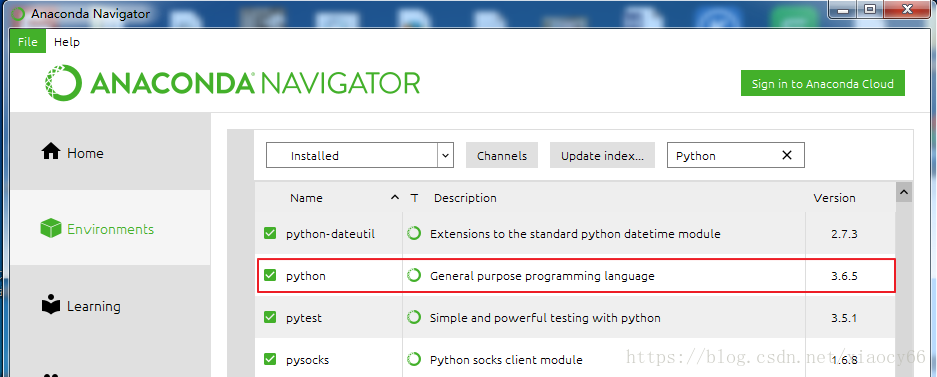
可以看到Anaconda里面已经自动帮我们安装好了Python3.6.5
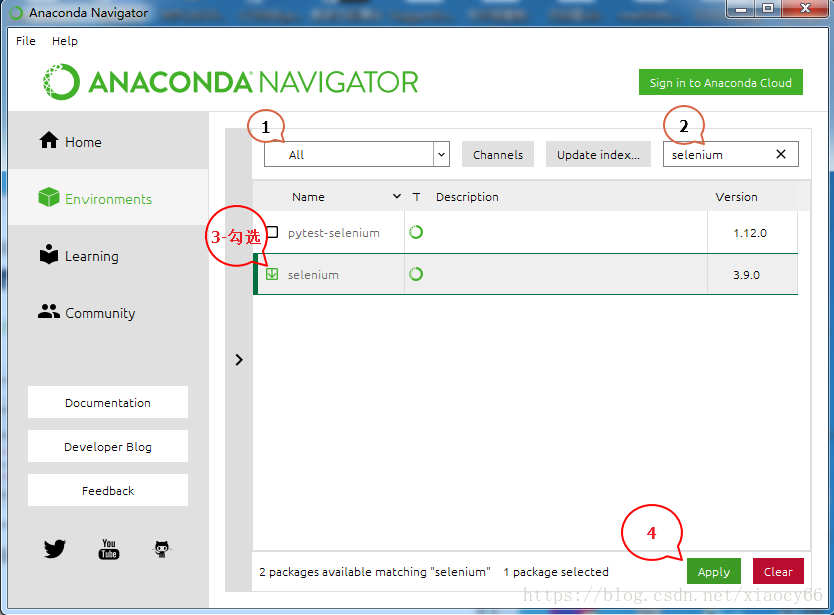
我们在这里通过anaconda继续安装后续爬网所需的selenuim框架(用这个管理工具安装的好处就是其它必须的相关依赖都会自动安装,省得自己一个一个去折腾,当然除非这个工具本身找不到你要的插件)
继续安装用户在py脚本中执行js脚本的插件:PyExecJS
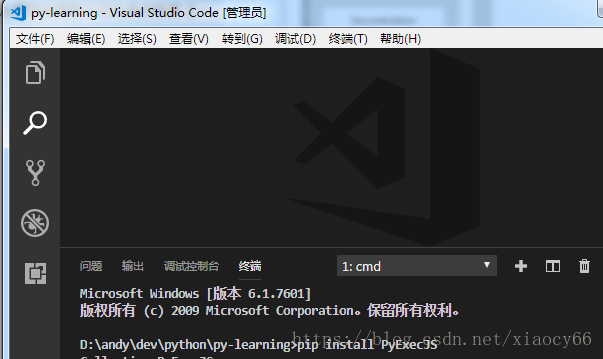
打开vs code,然后按键:Ctrl + ~ 打开cmd终端
- 输入pip install PyExecJS 安装
最后,卸载Anaconda预安装的lxml,手动安装带etree的版本,否则执行代码会提示etree导入出错,有些lxml不包含etree,导致找不到指定模块,我们需要手动安装一下。
方法有很多,这里只是其中一种:在网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml找到符合当前python3.7版本的64位的whl文件到本机,然后cmd命令窗口cd到这个whl文件所在的目录,执行安装(先卸载之前预安装的lxml版本再安装下载的这个):
pip uninstall lxml
pip install lxml-4.2.5-cp37-cp37m-win_amd64.whl==如果你的网速较慢,点这里快速下载 lxml-4.2.5-cp37-cp37m-win_amd64.whl==
安装火狐浏览器驱动:下载地址
下载后解压放到python.exe所在目录,本文中是C:\ProgramData\Anaconda3
至此,我们把本系列操作所需的软件环境都搞定了,接下来开始我们的爬虫之旅~
全文完结,后续实现用其它框架来爬虫新闻资源。敬请期待~
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
参考资料:
[1]: X1Path语法参考
[2]: 廖雪峰老师的Python3 在线学习手册
[3]: Python3官方文档
[4]: 菜鸟学堂-Python3在线学习
[5]: 其他所有分享过python学习填坑网友的经验
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】的更多相关文章
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- 使用python-aiohttp爬取今日头条
http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用python-aiohttp爬取网易云音乐>中, ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
随机推荐
- MATLAB cftool工具数据拟合结果好坏判断
SSE和RMSE比较小 拟合度R接近于1较好 * 统计参数模型的拟合优度 1.误差平方和(SSE) 2. R-Square(复相关系数或复测定系数) 3. Adjusted R-Square(调整自由 ...
- important的妙用解决firefox和ie的css兼容问题
设置css的min-height属性.min-height在Firefox里有效,但IE无法识别.下面有个不错的解决方案,大家可以参考下 对于某些内容可变的层(比如用户评论),我们希望它有个最小的高度 ...
- django在windows下的经历
django-admin.py startproject project_name 去掉.py 常见命令:https://blog.csdn.net/weixin_42134789/article/d ...
- mysql定时器设置开机默认自启动
1).查询mysql安装位置:show variables like "%char%"; 2).查询定时器是否开启: -查询定时器状态:show VARIABLES LIKE '% ...
- C语言通讯录系统——C语言单向链表实现
实现的通讯录功能有:查看通讯录.添加联系人.删除联系人.查询联系人.保存并退出. 通过txt文件保存和读取通讯录数据. #include <stdio.h> #include <st ...
- 20175306 迭代和JDB调试
迭代和JDB调试 1.使用C(n,m)=C(n-1,m-1)+C(n-1,m)公式进行递归编程实现求组合数C(m,n)的功能 代码展示: public class C { public static ...
- java连接3种数据库 JdbcLinkDB --201801
先看这篇记录 java连接3种数据库 JdbcLinkDB 测试 --201801 配置文件放在jar外面 读取,遇到的问题 - 海蓝steven - 博客园https://www.cnblogs.c ...
- linux系统下完全卸载Jenkins
1.关闭tomcat:./shutdown.sh 2.删除/webapps/jenkins下所有文件:rm -rf jenkins 3.删除配置文件:rm -rf /root/.jenkins/
- lua post参数获取,参数截断
post 请求头: a.application/x-www-form-urlencoded 普通表单提交 b.multipart/form-data 含有文件的表单,二进制上传 c.applicati ...
- C# 操作Session、Cookie,Url 编码解码工具类WebHelper
using System; using System.Collections.Generic; using System.IO; using System.Net; using System.Text ...