网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
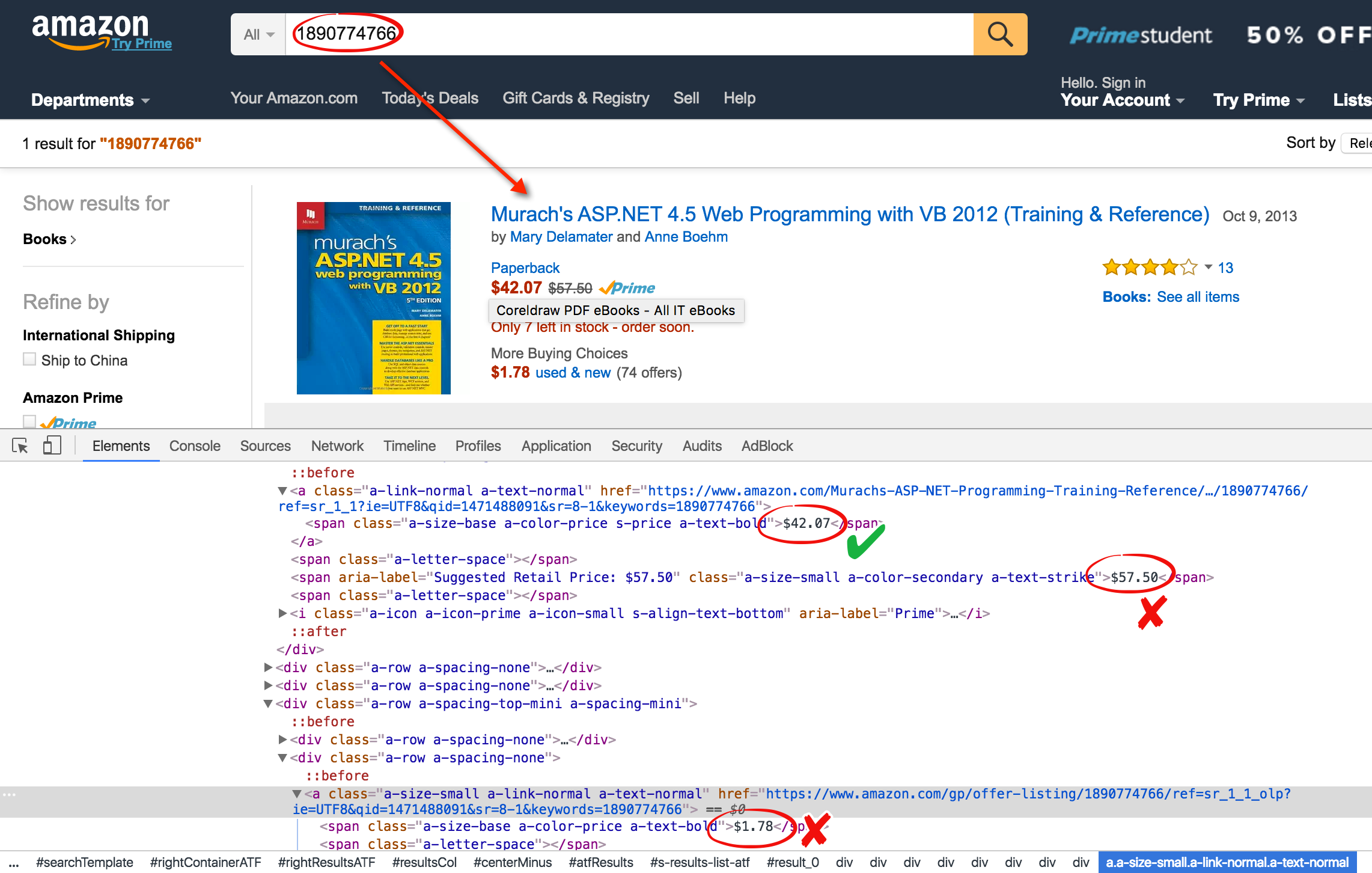
def get_price_amazon(isbn):
base_url = "https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords="
url = base_url + str(isbn)
page = urlopen(url)
soup = BeautifulSoup(page, 'lxml')
page.close()
price_regexp = re.compile("\$[0-9]+(\.[0-9]{2})?")
price = soup.find(text=price_regexp)
return [isbn, price]
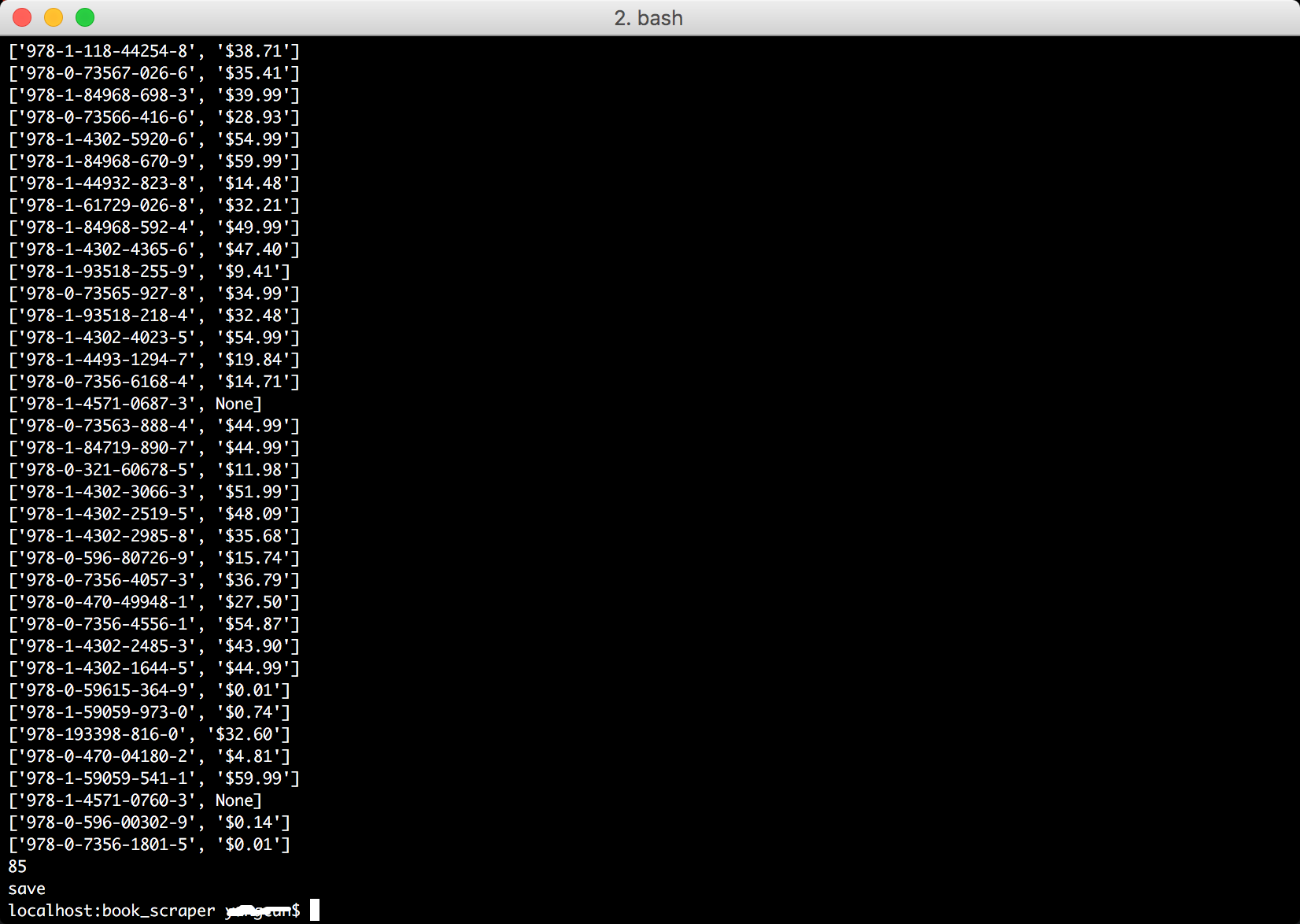
二、将两部分结果数据合并
book_info_data = pd.read_csv('books.csv')
price_data = pd.read_csv('prices.csv')
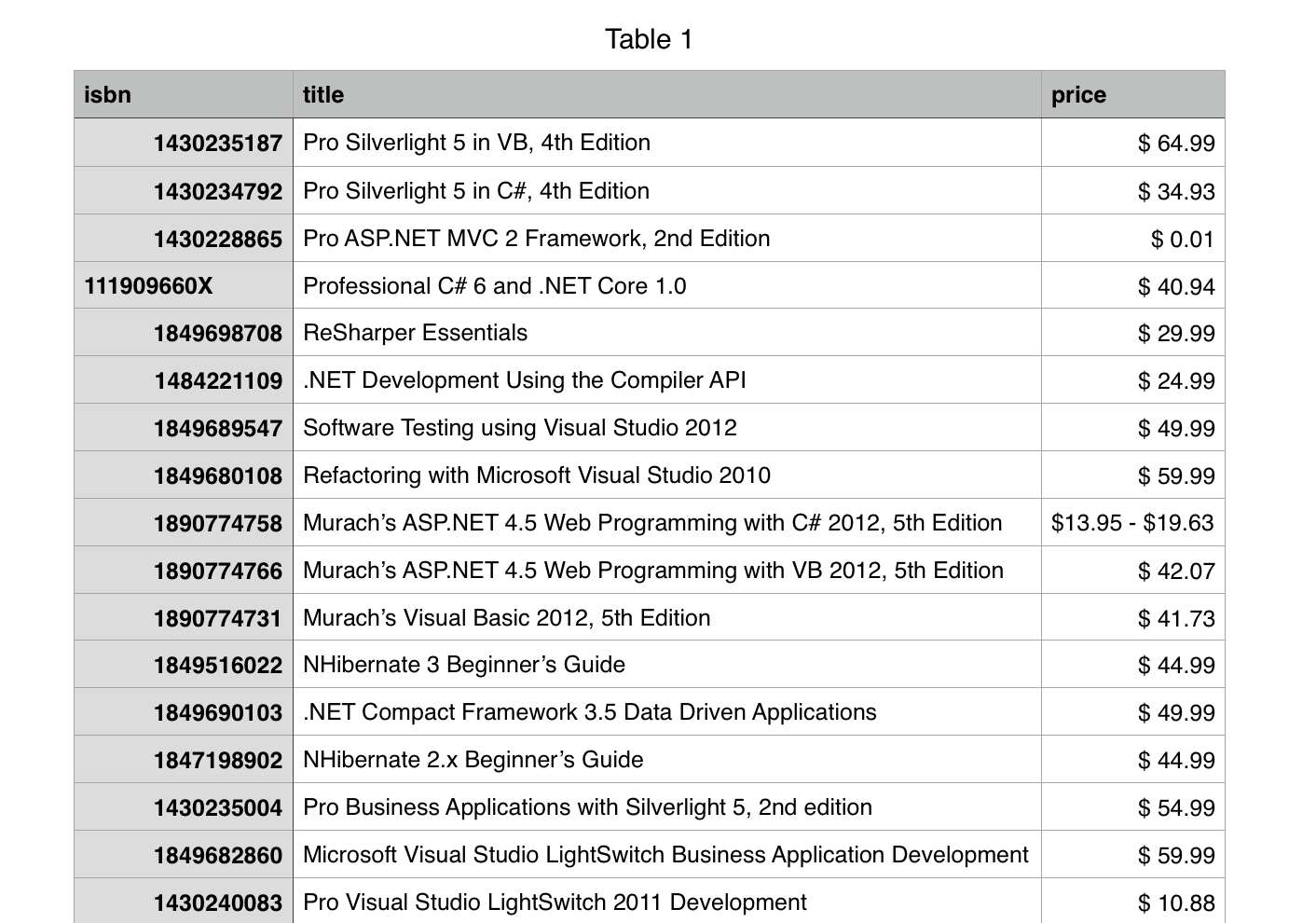
result = pd.merge(book_info_data, price_data, on='isbn')
result.to_csv('result.csv', index=False, header=True, columns=['isbn', 'title', 'price'])
大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 python操作Excel,excel读写 通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。
网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格的更多相关文章
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包(免费赠送)+崔庆才
Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包+崔庆才 下载: 链接:https://pan.baidu.com/s/1H-VrvrT7wE9-CW2Dy2p0qA 提取码:35go ...
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- java之网络爬虫介绍
文章大纲 一.网络爬虫基本介绍二.java常见爬虫框架介绍三.WebCollector实战四.项目源码下载五.参考文章 一.网络爬虫基本介绍 1. 什么是网络爬虫 网络爬虫(又被称为网页蜘蛛, ...
- Java网络爬虫 HttpClient
简介 : HttpClient是Apache Jakarta Common下的子项目,用于提供高效的,功能丰富的支持HTTP协议的客户编程工具包,其主要功能如下: 实现了所有HTTP的方法 : GET ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- Day01_WebCrawler(网络爬虫)
学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"webcrawler"获取视频和教程资料! b站在线视 ...
随机推荐
- JAVA for mac 的学习之路
要学习一门新技术,首先得下载相关的工具. 一 . 下载相关工具 1. 下载 jdk formac 下载地址为:http://www.oracle.com/technetwork/java/javase ...
- 深入理解CSS中的margin负值
前面的话 margin属性在实际中非常常用,也是平时踩坑较多的地方.margin折叠部分相信不少人都因为这样那样的原因中过招.margin负值也是很常用的功能,很多特殊的布局方法都依赖于它.它看似简单 ...
- Hawk 4.4 执行器
执行器是负责将Hawk的结果传送到外部环境的工具.你可以写入数据表,数据库,甚至执行某个特定的动作,或是生成文件等等. 在调试模式下,执行器都是不工作的.这是为了避免产生副作用.否则,每刷新一遍数据, ...
- 高频交易算法研发心得--MACD指标算法及应用
凤鸾宝帐景非常,尽是泥金巧样妆. 曲曲远山飞翠色:翩翩舞袖映霞裳. 梨花带雨争娇艳:芍药笼烟骋媚妆. 但得妖娆能举动,取回长乐侍君王. [摘自<封神演义>纣王在女娲宫上香时题的诗] 一首定 ...
- 修改eclipse皮肤
习惯了vim黑色背景的程序猿们想必用eclipse时会倍感的不适应吧,不过没关系,因为eclipse的皮肤是可以自己定制的! 下面是我电脑上的eclipse界面,看到这个是不是找回了vim的感觉呢? ...
- 整理下.net分布式系统架构的思路
最近看到有部分招聘信息,要求应聘者说一下分布式系统架构的思路.今天早晨正好有些时间,我也把我们实际在.net方面网站架构的演化路线整理一下,只是我自己的一些想法,欢迎大家批评指正. 首先说明的是.ne ...
- App解读
一直不懂别人口中说的原生开发.混合式开发.今天突然看了一篇文章讲解的是什么叫做原生App?移动 Web App?混合APP?分享给大家. 原生App是专门针对某一类移动设备而生的,它们都是直接安装到设 ...
- C#事件-使用事件需要的步骤
事件是C#中另一高级概念,使用方法和委托相关.奥运会参加百米的田径运动员听到枪声,比赛立即进行.其中枪声是事件,而运动员比赛就是这个事件发生后的动作.不参加该项比赛的人对枪声没有反应. 从程序员的角度 ...
- 【转】组件化的Web王国
本文由 埃姆杰 翻译.未经许可,禁止转载!英文出处:Future Insights. 内容提要 使用许多独立组件构建应用程序的想法并不新鲜.Web Component的出现,是重新回顾基于组件的应用程 ...
- TFS2013 设置签出独占锁
转载自: http://www.cnblogs.com/zhang888/p/4280251.html