scrapy 原理,结构,基本命令,item,spider,selector简述
原理,结构,基本命令,item,spider,selector简述
原理
(1)结构
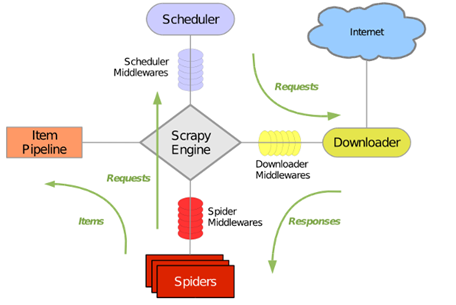

(2)运行流程

实操
(1) scrapy命令:
注意先把python安装目录的scripts文件夹添加到环境变量
查看帮助
scrapy
scrapy <command> -h
创建项目
scrapy startproject 项目名
创建爬虫
scrapy genspider [-t template] <name> <domain>
运行爬虫
运行一个爬虫的基本命令:
scrapy crawl 爬虫名
-a 给spider的构造器传参数
-o表示写入文件,-t 表示以json格式输出
scrapy crawl test -o test.json -t json
查看可用爬虫
scrapy list
快捷爬取(不需要创建爬虫项目,爬取结果直接回送到命令行)
scrapy fetch <url>

(2)项目结构功能
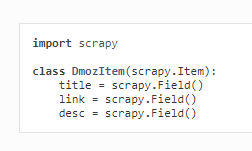
(3)item.py定义数据model
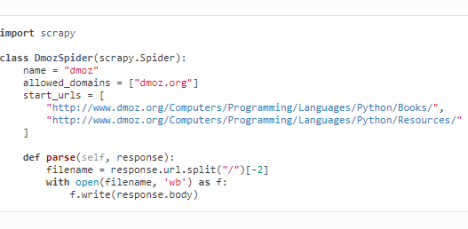
(4)spiders文件夹中的爬虫文件
name爬虫名,唯一
allowed_domains域名
start_urls起始url
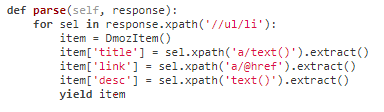
parse函数——处理爬取到的response的函数
基本格式:
parse函数使用selector的格式:
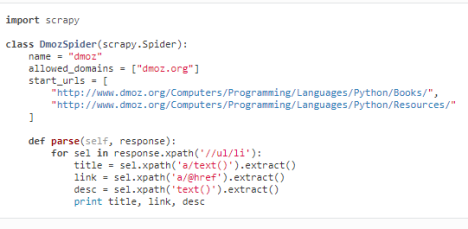
parse函数使用selector并通过生成器返回多个结果:
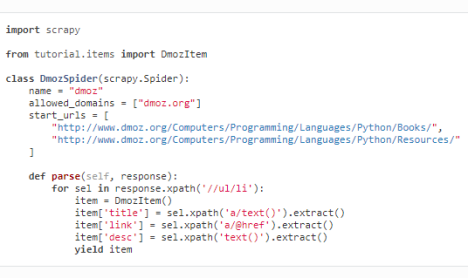
(5)selector
四种格式(即spider文件parse函数中response对象的四个可用方法)

response.xpath()
response.css()
response.extract()
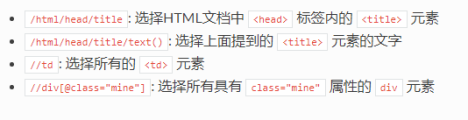
举例:response.xpath()使用
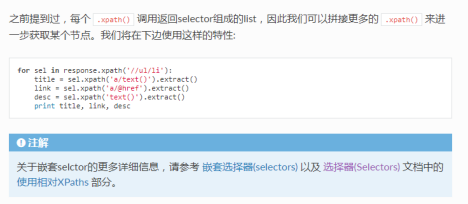
selector的嵌套
(6)保存爬取结果的方式之一:Feed Exports
scrapy 原理,结构,基本命令,item,spider,selector简述的更多相关文章
- 第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了. 然后进入虚拟环境创建一个scrapy工程: (third ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Scrapy 原理
Scrapy 原理 一.原理 scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列程序中. 二.工作流程 Scrapy Engi ...
- Scrapy(六):Spider
总结自:Spiders - Scrapy 2.5.0 documentation Spider 1.综述 ①在回调函数Parse及其他自写的回调函数中,必须返回Item对象.Request对象.或前两 ...
- python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别: 库可以直接拿来就用, 框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令: 创建一个 项目 : cd 到需 ...
- scrapy框架系列 (3) Item Pipline
item pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
- scrapy框架中多个spider,tiems,pipelines的使用及运行方法
用scrapy只创建一个项目,创建多个spider,每个spider指定items,pipelines.启动爬虫时只写一个启动脚本就可以全部同时启动. 本文代码已上传至github,链接在文未. 一, ...
- Scrapy 对不同的Item进行分开存储
在Piperlines里面进行对象的判断, def process_item(self, item, spider): if item.__class__ == BaseItem : #savexxx ...
- scrapy 知乎关键字爬虫spider代码
以下是spider部分的代码.爬知乎是需要登录的,建议使用cookie就可以了,如果需要爬的数量预计不多,请不要使用过大的线程数量,否则会过快的被封杀,需要等十几个小时账号才能重新使用,比起损失的这十 ...
随机推荐
- Powershell对象条件查询筛选
在 Windows PowerShell 中,与所需的对象数量相比,通常生成的对象数量以及要传递给管道的对象数量要多得多.可以使用 Format cmdlet 来指定要显示的特定对象的属性,但这并不能 ...
- SqlServer 数据分页
select * from ( select ROW_NUMBER() over (partition by name order by name) rowid,* from table ) t
- Oracle面试题目及解答
这里的回答并不是十分全面,这些问题可以通过多个角度来进行解释,也许你不必在面试过程中给出完全详尽的答案,只需要通过你的解答使面试考官了解你对ORACLE概念的熟悉程度. 1. 解释冷备份和热备份的不同 ...
- 1.2.3 Task and Back Stack - 任务和回退堆
一个应用通常包含多个Activities.每个activity的设计应该围绕着某种指定类型的action,如果这样做了,用户就可以执行该action,也可以用它来开启另外的activity.例如,邮件 ...
- Swift-8-枚举
// Playground - noun: a place where people can play import UIKit // 枚举语法 enum SomeEnumeration { // e ...
- 下列哪一个接口定义了用于查找、创建和删除EJB实例
下列哪一个接口定义了用于查找.创建和删除EJB实例 A.Home B.Remote C.Local D.Message 解答:A remote接口定义了业务方法,用于EJB客户端调用业务方法. hom ...
- C#调用ActiveX
ActiveX控件一般是用来在IE浏览器中配合使用的,有时也需要在例如WPF中调用,这样也是可以的. 一.引用-->右键-->添加引用 点击 COM,找到想要引用的类型库,名字不一定和IE ...
- Hourrank 21 Tree Isomorphism 树hash
https://www.hackerrank.com/contests/hourrank-21/challenges/tree-isomorphism 题目大意: 给出一棵树, 求有多少本质不同的子树 ...
- 安装tomcat出现failed to install tomcat6 service错误及解决方法(转载)
安装安装版tomcat会出现failed to install tomcat6 service ,check your setting and permissio的概率是非常低的,但是最近楼主就老出现 ...
- js for in
JavaScript中for..in循环陷阱 大家都知道在JavaScript中提供了两种方式迭代对象: (1)for 循环: (2)for..in循环: 使用for循环进行迭代数组对象,想必 ...