scrapy-splash抓取动态数据例子六
一、介绍
本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息。
给定关键字:打通;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息

三、数据抓取
针对上面的网站信息,来进行抓取
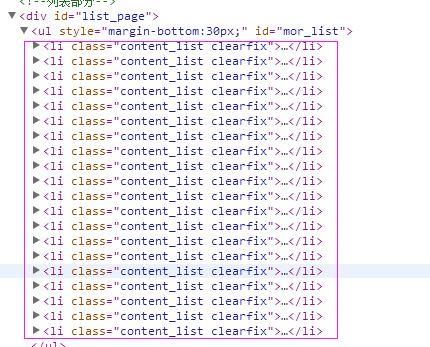
1、首先抓取信息列表
抓取代码:sels = site.xpath('//li[@class="content_list clearfix"]')
2、抓取标题
首先列表页面,根据标题和日期来判断是否自己需要的资讯,如果是,就今日到资讯对应的链接,来抓取来源,如果不是,就不用抓取了
抓取代码:titles = sel.xpath('.//div[@class="content_listtext"]/a/h3/text()')
3、抓取链接
抓取代码:url = 'http://www.tvoao.com' + str(sel.xpath('.//a/@href')[0].extract())
4、抓取日期
抓取代码:strdates = sel.xpath('.//div[@class="listtext_label"]/span/text()')
5、抓取来源
抓取代码:sources = site.xpath('//div[@class="headlines_source"]/span[2]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') sys.stdout = open('output.txt', 'w') class tvoaoSpider(Spider):
name = 'tvoao' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearch_urls = cf.GetValue("tvoao", "websearchurl").split(';')
start_urls = []
for url in websearch_urls:
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
)
def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
return False, '' def parse(self, response):
site = Selector(response)
sels = site.xpath('//li[@class="content_list clearfix"]')
for sel in sels:
strdates = sel.xpath('.//div[@class="listtext_label"]/span/text()') if len(strdates)>0:
flag, date = self.date_isValid(str(strdates[0].extract()))
if flag:
titles = sel.xpath('.//div[@class="content_listtext"]/a/h3/text()')
if len(titles) > 0:
title = str(titles[0].extract()) url = 'http://www.tvoao.com' + str(sel.xpath('.//a/@href')[0].extract())
for keyword in self.information_wordlist:
if title.find(keyword) > -1:
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//div[@class="headlines_source"]/span[2]/text()')
if len(sources)>0:
it['source'] = str(sources[0].extract()).replace(u'来源: ', '')
return it
scrapy-splash抓取动态数据例子六的更多相关文章
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十五
一.介绍 本例子用scrapy-splash爬取电视之家(http://www.tvhome.com/news/)网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信 ...
随机推荐
- Search a 2D Matrix——两度二分查找
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
- Majority Element——算法课上的一道题(经典)
Given an array of size n, find the majority element. The majority element is the element that appear ...
- 使用python读取文本中结构化数据
需求 read some .txt file in dir and find min and max num in file. solution: echo *.txt > file.name ...
- Introducing the Filter Types
The ActionFilterAttribute class implements both the IActionFilter and IResultFilter interfaces. This ...
- D - Matrix Multiplication ZOJ - 2316 规律题
Let us consider undirected graph G = which has N vertices and M edges. Incidence matrix of this grap ...
- BZOJ 3399 [Usaco2009 Mar]Sand Castle城堡(贪心)
[题目链接] http://www.lydsy.com/JudgeOnline/problem.php?id=3399 [题目大意] 将一个集合调整成另一个集合中的数,把一个数+1需要消耗x,-1需要 ...
- 【搜索】bzoj3109 [cqoi2013]新数独
搜索,没什么好说的.要注意读入. Code: #include<cstdio> #include<cstdlib> using namespace std; ][]= {{,, ...
- 【manacher】HDU3068-最长回文
[题目大意] 给出一个只由小写英文字符a,b,c...y,z组成的字符串S,求S中最长回文串的长度. [manacher知识点] ①mx - i > P[j] 的时候,以S[j]为中心的回文子串 ...
- 【FFT】HDU4609-3 idiots
..退化为一天两题了,药丸.. [题目大意] 给出n根木棍的长度,求从其中取出3根能组成三角形的概率. [思路] 然后枚举求前缀和,枚举最长边.假设最长边为l,先求出所有两边之和大于它的情况数.然后减 ...
- 【tarjan+缩点】POJ1236[IOI1996]-Network of Schools
[题意] 见:http://blog.csdn.net/ascii991/article/details/7466278 [思路] 缩点+tarjan,思路也可以到上面的博客去看.(吐槽:这道题其实我 ...