【转载】 DeepMind 提出元梯度强化学习算法,显著提高大规模深度强化学习应用的性能
原文地址:
https://www.jiqizhixin.com/articles/053104

2018/05/31 12:38
=============================================================
DeepMind 提出元梯度强化学习算法,显著提高大规模深度强化学习应用的性能
强化学习(RL)的核心目标是优化智能体的回报(累积奖励)。一般通过预测和控制相结合的方法来实现这一目标。预测的子任务是估计价值函数,即在任何给定状态下的预期回报。理想情况下,这可以通过朝着真值函数(true value function)的方向不断更新近似价值函数来实现。控制的子任务是优化智能体选择动作的策略,以最大化价值函数。理想情况下,策略只会在使真值函数增加的方向上更新。然而,真值函数是未知的,因此,对于预测和控制,我们需要将采样回报作为代理(proxy)。强化学习算法家族 [Sutton,1988;Rummery 和 Niranjan,1994;van Seijen 等,2009;Sutton 和 Barto,2018] 包括多种最先进的深度强化学习算法 [Mnih 等,2015;van Hasselt 等,2016;Harutyunyan 等,2016;Hessel 等,2018;Espeholt 等,2018],它们的区别在于对回报的不同设定。
折扣因子 γ 决定了回报的时间尺度。接近 1 的折现因子更关注长期的累计回报,而接近 0 的折现因子优先考虑短期奖励,更关注短期目标。即使在明显需要关注长期回报的问题中,我们也经常观察到使用小于 1 的折扣因子可以获得更好的效果 [Prokhorov 和 Wunsch,1997],这一现象在学习的早期体现得尤为明显。众所周知,许多算法在折扣因子较小时收敛速度较快 [Bertsekas 和 Tsitsiklis,1996],但过小的折扣因子可能会导致过度短视的高度次优策略。在实践中,我们可以首先对短期目标进行优化,例如首先用 γ= 0 进行优化,然后在学习取得一定效果后再不断增加折扣 [Prokhorov and Wunsch,1997]。
我们同样可以在不同的时间段设定不同的回报。一个 n 步的回报需要考虑 n 步中奖励的累积,然后添加第 n 个时间步时的价值函数。λ- 回报 [Sutton,1988;Sutton 和 Barto,2018] 是 n 步回报的几何加权组合。在任何一种情况下,元参数 n 或 λ 对算法的性能都很重要,因为他们影响到偏差和方差之间的权衡。许多研究人员对如何自动选择这些参数进行了探索 [Kearns 和 Singh,2000,Downey 和 Sanner,2010,Konidaris 等,2011,White and White,2016]。
还有很多其他的设计可以在回报中体现出来,包括离策略修正 [Espeholt 等,2018,Munos 等,2016]、目标网络 [Mnih 等,2015]、对特定状态的强调 [Sutton 等,2016]、奖励剪裁 [Mnih 等,2013],甚至奖励本身 [Randløv 和 Alstrøm,1998;Singh 等,2005;Zheng 等,2018]。
本论文主要关注强化学习的一个基本问题:便于智能体最大化回报的最佳回报形式是什么?具体而言,本论文作者提出通过将回报函数当作包含可调整元参数 η 的参数函数来学习,例如折扣因子 γ 或 bootstrapping 参数 λ [Sutton,1988]。在智能体与环境的交互中,元参数 η 可以在线进行调整,使得回报既能适应具体问题,又能随着时间动态调整以适应不断变化的学习环境。研究者推导出一种实用的、基于梯度的元学习算法,实验表明它可以显著提高大规模深度强化学习应用的性能。
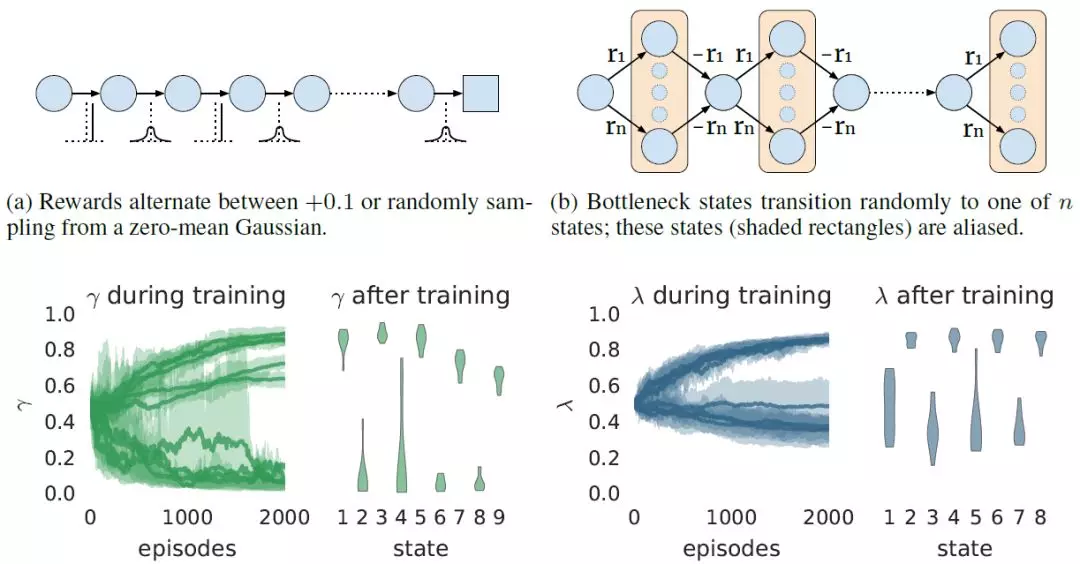
图 1:在各自的马尔可夫奖励过程(顶部)中,状态依赖可调整参数(a)bootstrapping 参数 λ 或(b)折扣因子 γ 的元梯度学习结果图示。在底部显示的每个子图中,第一幅图展示了元参数 γ 或 λ 在训练过程中的变化情况(10 个种子下的平均值 - 阴影区域覆盖了 20%-80%)。第二幅图显示了每种状态下 γ 或 λ 的最终值,分别指奇 / 偶状态的高 / 低值(小提琴图显示不同种子的分布情况)。
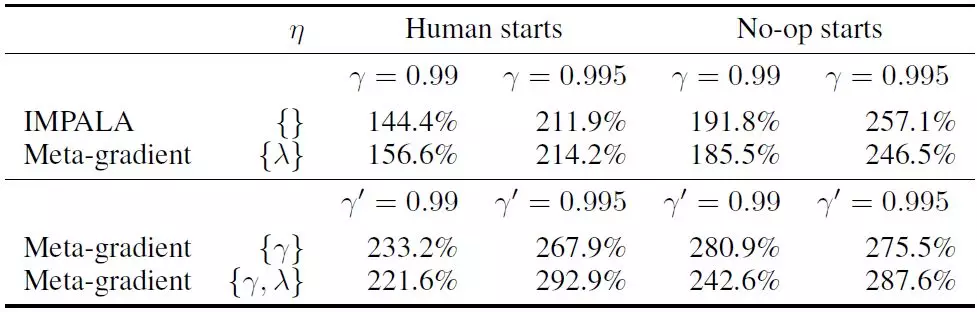
表 1:与不使用元学习的基线 IMPALA 算法相比,元学习折扣参数 γ、时序差分学习参数 λ,或学习二者的结果。研究者使用的是 [Espeholt et al,2018] 最初报告的折扣因子 γ= 0.99 以及调整后的折扣因子 γ= 0.995(见附录 C); 为了公平比较,研究者将元目标中的交叉验证折扣因子 γ’设置为相同的值。
论文:Meta-Gradient Reinforcement Learning(元梯度强化学习)

论文链接:https://arxiv.org/abs/1805.09801
摘要:强化学习算法的目标是估计和 / 或优化价值函数。然而与监督学习不同,强化学习中没有可以提供真值函数的教师或权威。相反,大多数强化学习算法估计和 / 或优化价值函数的代理。该代理通常基于对真值函数的采样和 bootstrapped 逼近,即回报。对回报的不同选择是决定算法本质的主要因素,包括未来奖励的折扣因子、何时以及如何设定奖励,甚至奖励本身的性质。众所周知,这些决策对强化学习算法的整体成功至关重要。我们讨论了一种基于梯度的元学习算法,它能够在线适应回报的本质,同时进行与环境的互动和学习。我们将该算法应用于超过 2 亿帧 Atari 2600 环境中的 57 场比赛,结果表明我们的算法取得了目前最好的性能。
【转载】 DeepMind 提出元梯度强化学习算法,显著提高大规模深度强化学习应用的性能的更多相关文章
- 强化学习 车杆游戏 DQN 深度强化学习 Demo
网上搜寻到的代码,亲测比较好用,分享如下. import gym import time env = gym.make('CartPole-v0') # 获得游戏环境 observation = en ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- 提升学习算法简述:AdaBoost, GBDT和XGBoost
1. 历史及演进 提升学习算法,又常常被称为Boosting,其主要思想是集成多个弱分类器,然后线性组合成为强分类器.为什么弱分类算法可以通过线性组合形成强分类算法?其实这是有一定的理论基础的.198 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
随机推荐
- Flashduty 案例分享 - 益丰大药房
Flashduty 作为功能完备的事件OnCall中心,可以接入云上.云下不同监控系统,统一做告警降噪分派.认领升级.排班协同,已经得到众多先进企业的认可.我们采访了一些典型客户代表,了解他们的痛点. ...
- Jx9 虚拟机
一.Jx9 虚拟机的生命周期 加载 Jx9 脚本 jx9_compile() 或 jx9_compile_file(),加载编译成功后,Jx9 引擎将自动创建一个实例 (jx9_vm) 并且返回指向此 ...
- ITMS-90717: 无效的应用程序商店图标
PS导入照片 图像->模式->索引颜色 透明度去掉打勾保存即可
- Unity UI优化
UI优化 动静分离.拆分UI.预加载.字体拆分.滚屏优化.网格重构优化.展示关闭优化.对象池.贴图优化.图集拼接优化.UI业务逻辑中GC优化等. 一.动静分离 ** 问题:**unity中UGUI系统 ...
- 常用RAID级别简介
RAID不同等级的两个目标: 1. 增加数据可靠性 2. 增加存储的读写性能 RAID级别: RAID-0: 是以条带的形式将数据均匀分布在阵列的各个磁盘上 优点:读写性能高,不存在校验,不会 ...
- 10-Python进程与线程
Python进程 创建新进程 from multiprocessing import Process import time def run_proc(name): #子进程要执行的代码 for i ...
- openEuler 20.04 TLS3 上的 Python3.11.9 源码一键构建安装
#! /bin/bash # filename: python-instaler.sh SOURCE_PATH=/usr/local/source # 下载源码包 mkdir -p $SOURCE_P ...
- .NET 个人博客-首页排版优化-2
个人博客-首页排版优化-2 原本这篇文章早就要出了的,结果之前买的服务器服务商跑路了,导致博客的数据缺失了部分.我是买了一年的服务器,然后用了3个月,国内跑路云太多了,然后也是花钱重新去别的服务商买了 ...
- C# Linq俩个list<Datarow> 取差集,并自定义字段
可以自定义类 ,也可以从参考官网文档:Enumerable.Except 方法 (System.Linq) | Microsoft Learn List<DataRow> list1 = ...
- mysqldump备份时保持数据一致性分析--master-data=2 --single-transaction
对MySQL数据进行备份,常见的方式如以下三种,可能有很多人对备份时数据一致性并不清楚 1.直接拷贝整个数据目录下的所有文件到新的机器.优点是简单.快速,只需要拷贝:缺点也很明显,在整个备份过程中新机 ...