ElasticSearch系列——介绍、安装、插件介绍、安装ElasticSearch插件、安装Kibana、安装中文分词器、倒排索引、索引操作、映射管理
文章目录
ElasticSearch之介绍
一 Elasticsearch产生背景
1.1 大规模数据如何检索
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
1)用什么数据库好?(mysql、oracle、mongodb、hbase…)
2)如何解决单点故障;(lvs、F5、A10、Zookeeper、MQ)
3)如何保证数据安全性;(热备、冷备、异地多活)
4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5)如何解决统计分析问题;(离线、近实时)
1.2 传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果
1.3 非关系型数据库解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
1.4 内存数据库解决方案
完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到PB级别时,按照每个节点96G内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922个
实际上,考虑到数据备份,节点数往往在2.5万台左右。成本巨大决定了其不现实!
所以把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。
全部放在内存速度问题是解决了,但成本问题上来了。
为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法:
1、存储数据时按有序存储;
2、将数据和索引分离;
3、压缩数据;
这就引出了Elasticsearch
二 Elasticsearch介绍
2.1Elasticsearch是什么
Elasticsearch 是一个基于Lucene的分布式搜索和分析引擎。
ES是elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch使用Java开发,在Apache许可条款下开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
设计用途:用于分布式全文检索,通过HTTP使用JSON进行数据索引,速度快
2.2 Lucene与Elasticsearch关系
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2.3 Elasticsearch vs solr
1)Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。
2)Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
3)Solr是用Java编写、运行在Servlet容器(如 Apache Tomcat 或Jetty)的一个独立的全文搜索服务器。 Solr采用了 Lucene Java 搜索库为核心的全文索引和搜索,并具有类似REST的HTTP/XML和JSON的API。
4)Solr强大的外部配置功能使得无需进行Java编码,便可对 其进行调整以适应多种类型的应用程序。Solr有一个插件架构,以支持更多的高级定制
Elasticsearch 与 Solr 的比较总结
- 二者安装都很简单
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用
2.4 Elasticsearch核心概念
2.4.1 Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2.4.2 Node:节点
形成集群的每个服务器称为节点。
2.4.3 Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
2.4.4 Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
2.4.5 全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”今日是周日我们出去玩” 可能会被分词成:“今天“,”周日“,“我们“,”出去玩“ 等token,这样当你搜索“周日” 或者 “出去玩” 都会把这句搜出来。
2.5 与关系型数据库Mysql对比
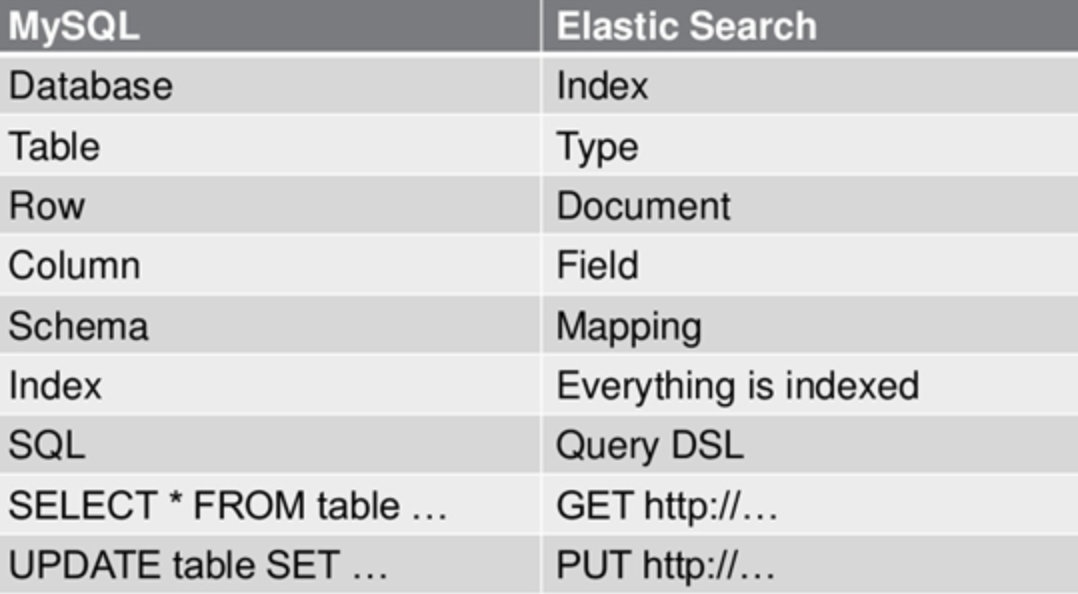
1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.1.7
2.6 ES逻辑设计(文档–>类型–>索引)
一个索引类型中,包含多个文档,比如说文档1,文档2。
当我们索引一篇文档时,可以通过这样的顺序找到它:索引▷类型▷文档ID,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
文档
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含
key:value - 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
- 文档是无模式的,也就是说,字段对应值的类型可以是不限类型的。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型(详见扩展阅读:删除映射类型),这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
类型中对于字段的定义称为映射,比如name映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整型。
但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。后面在讨论更多关于映射的东西。
索引
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
2.7 ES物理设计
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
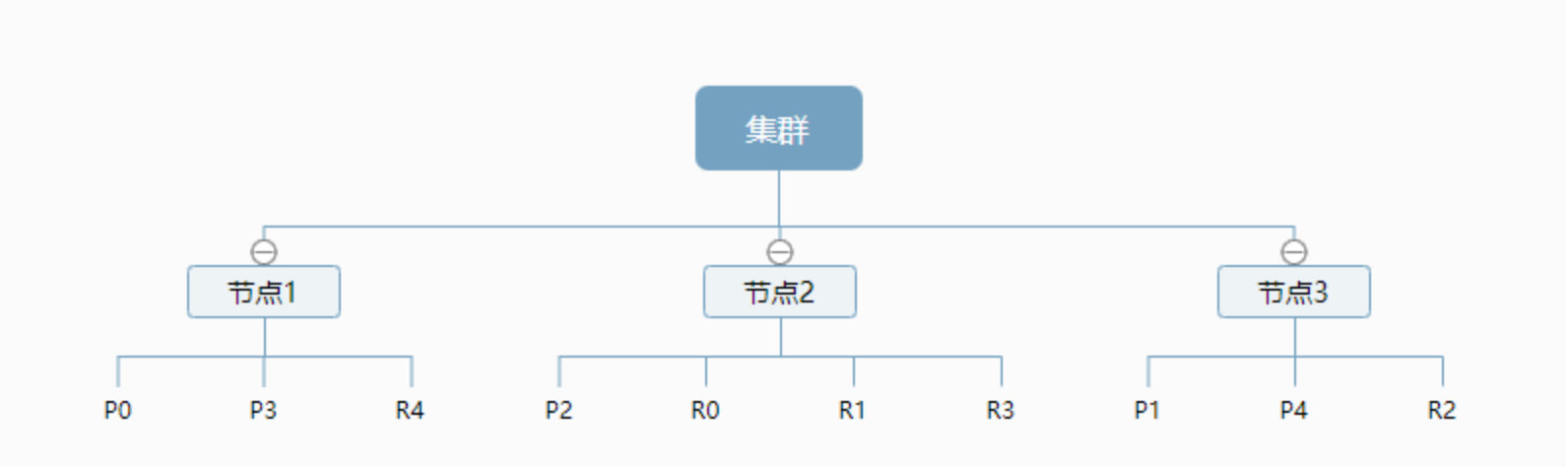
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
那么这个索引是如何存储在集群中的呢?
图中有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
2.6 ELK是什么
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
2.7 Elasticsearch特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
三 为什么使用Elasticsearch
3.1 国内外优秀案例
1) 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”。
2)维基百科:启动以elasticsearch为基础的核心搜索架构。
3)SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”。
4)百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据。
5)新浪ES 如何分析处理32亿条实时日志
6)阿里ES 构建挖财自己的日志采集和分析体系
7)有赞ES 业务日志处理
3.2 我们的业务场景
实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用ElasticSearch等来实现。
近年ElasticSearch发展迅猛,已经超越了其最初的纯搜索引擎的角色,现在已经增加了数据聚合分析(aggregation)和可视化的特性,如果你有数百万的文档需要通过关键词进行定位时,ElasticSearch肯定是最佳选择。当然,如果你的文档是JSON的,你也可以把ElasticSearch当作一种“NoSQL数据库”, 应用ElasticSearch数据聚合分析(aggregation)的特性,针对数据进行多维度的分析。
尝试使用ES来替代传统的NoSQL,它的横向扩展机制太方便了
应用场景:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文检索服务,需要使用ES
四 Elasticsearch索引到底能处理多大数据
单一索引的极限取决于存储索引的硬件、索引的设计、如何处理数据以及你为索引备份了多少副本。
通常来说,一个Lucene索引(也就是一个elasticsearch分片,一个es索引默认5个分片)不能处理多于21亿篇文档,或者多于2740亿的唯一词条。但达到这个极限之前,我们可能就没有足够的磁盘空间了!
当然,一个分片如何很大的话,读写性能将会变得非常差
安装ElasticSearch
一 安装JDK环境
因为ElasticSearch是用Java语言编写的,所以必须安装JDK的环境,并且是JDK 1.8以上,具体操作步骤自行百度
安装完成查看java版本
java -version
二 官网下载最新版本
下载地址[https://www.elastic.co/cn/downloads/elasticsearch],选择相应版本下载即可
三 下载其他版本
直接点击https://www.elastic.co/cn/downloads/past-releases#elasticsearch
三 下载完成,启动
解压文件,切换到解压文件路径下,执行
cd elasticsearch-<version> #切换到路径下
./bin/elasticsearch #启动es
#如果你想把 Elasticsearch 作为一个守护进程在后台运行,那么可以在后面添加参数 -d 。
#如果你是在 Windows 上面运行 Elasticseach,你应该运行 bin\elasticsearch.bat 而不是 bin\elasticsearch
四 测试启动是否成功
在浏览器输入以下地址:http://127.0.0.1:9200/
即可看到如下内容:
{
"name" : "lqzMacBook.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "G1DFg-u6QdGFvz8Z-XMZqQ",
"version" : {
"number" : "7.5.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "e9ccaed468e2fac2275a3761849cbee64b39519f",
"build_date" : "2019-11-26T01:06:52.518245Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
五 关闭es
#查看进程
ps -ef | grep elastic
#干掉进程
kill -9 2382(进程号)
#以守护进程方式启动es
elasticsearch -d
一 Elasticsearch插件介绍
es插件是一种增强Elasticsearch核心功能的途径。它们可以为es添加自定义映射类型、自定义分词器、原生脚本、自伸缩等等扩展功能。
es插件包含JAR文件,也可能包含脚本和配置文件,并且必须在集群中的每个节点上安装。安装之后,需要重启集群中的每个节点才能使插件生效。
es插件包含核心插件和第三方插件两种
二 核心插件
核心插件是elasticsearch项目提供的官方插件,都是开源项目。这些插件会跟着elasticsearch版本升级进行升级,总能匹配到对应版本的elasticsearch,这些插件是有官方团队和社区成员共同开发的。
官方插件地址: https://github.com/elastic/elasticsearch/tree/master/plugins
三 第三方插件
第三方插件是有开发者或者第三方组织自主开发便于扩展elasticsearch功能,它们拥有自己的许可协议,在使用它们之前需要清除插件的使用协议,不一定随着elasticsearch版本升级, 所以使用者自行辨别插件和es的兼容性。
四 插件安装
elasticsearch的插件安装方式还是很方便易用的。
它包含了命令行和离线安装几种方式。
它包含了命令行,url,离线安装三种方式。
核心插件随便选择一种方式安装均可,第三方插件建议使用离线安装方式
第一种:命令行
bin/elasticsearch-plugin install [plugin_name]
# bin/elasticsearch-plugin install analysis-smartcn 安装中文分词器
第二种:url安装
bin/elasticsearch-plugin install [url]
#bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-smartcn/analysis-smartcn-6.4.0.zip
第三种:离线安装
#https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-smartcn/analysis-smartcn-6.4.0.zip
#点击下载analysis-smartcn离线包
#将离线包解压到ElasticSearch 安装目录下的 plugins 目录下
#重启es。新装插件必须要重启es
注意:插件的版本要与 ElasticSearch 版本要一致
安装ElasticSearch插件
一 Head插件介绍
elasticsearch-head是elasticsearch的一款可视化工具,依赖于node.js ,所以需要先安装node.js
二 安装Node.js
一 nodejs介绍
Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
为什么要安装Node.js呢,下面用到的Grunt 工具是基于Node.js 使用的
下载地址:https://nodejs.org/en/download/releases/
选择版本下载, 一直下一步确定即可,安装后进入命令行中 输入 :
node -v
# 显示版本号即安装成功
二 查看原来的镜像地址
npm(node package manager):nodejs的包管理器,用于node插件管理(包括安装、卸载、管理依赖等)
npm get registry
# 输出:https://registry.npmjs.org/
三 npm切换阿里源
#切换阿里源
npm config set registry https://registry.npm.taobao.org/
#查看是否成功
npm config get registry
#或者
npm get registry
#可以看到输出
#https://registry.npm.taobao.org/
四 安装cmpm
cnpm:因为npm安装插件是从国外服务器下载,受网络的影响比较大,可能会出现异常,如果npm的服务器在中国就好了,所以我们乐于分享的淘宝团队干了这事。来自官网:“这是一个完整
npmjs.org 镜像,你可以用此代替官方版本(只读),同步频率目前为 10分钟 一次以保证尽量与官方服务同步。”
npm install -g cnpm --registry=https://registry.npm.taobao.org
#查看是否安装成功
cnpm -v
#成功后可以使用cnpm代替npm命令
五 改变原有的环境变量
1、首先配置npm的全局模块的存放路径、cache的路径
npm config set prefix "路径"
npm config set cache "路径"
三 安装Grunt
#Grunt是基于Node.js的项目构建工具。它可以自动运行你所设定的任务
npm install grunt -g
四 下载Head
#地址:<https://github.com/mobz/elasticsearch-head>,可以用git下载,或者下载zip
# 解压后切换到目录下
cd elasticsearch-head
# 通过npm安装依赖
npm install
#启动
npm run start
#在浏览器里打开
http://localhost:9100/
五 配置跨域
修改 Elasticsearch 安装目录中config 文件夹下 elasticsearch.yml 文件,加入下面两行:
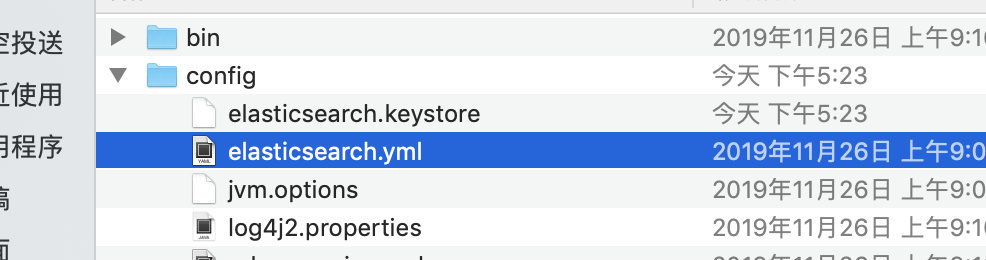
添加配置时,:后必须空格,不然启动闪退
http.cors.enabled: true
http.cors.allow-origin: "*"
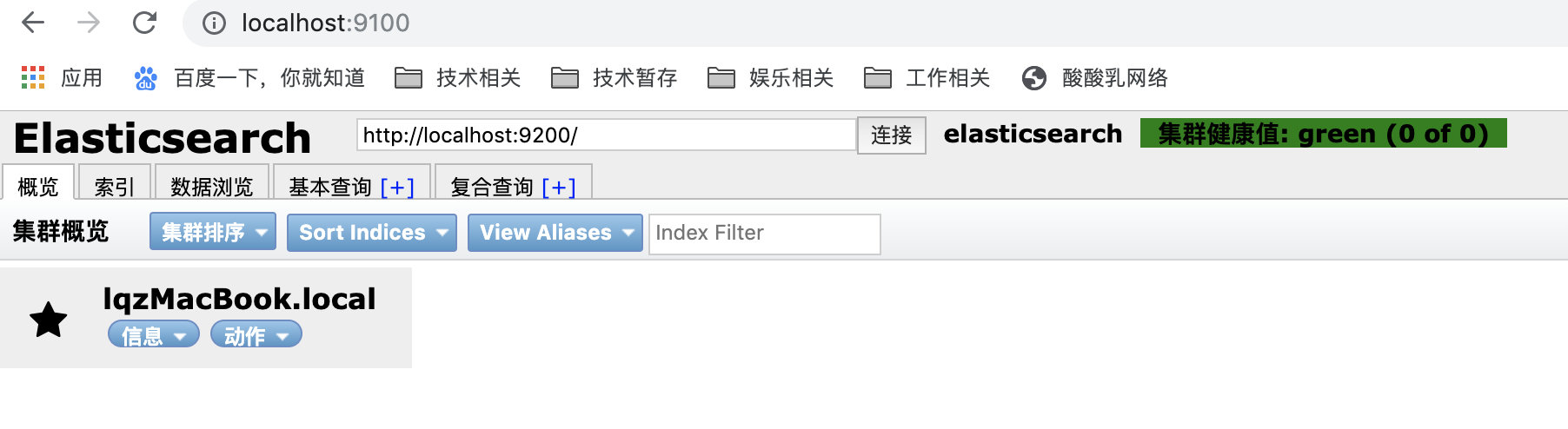
六 查看
看到如下效果表示成功
安装Kibana
一 Kibana介绍
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。
您、可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现
详情可见用户手册:
https://www.elastic.co/guide/cn/kibana/current/index.html
注意跟Elasticsearch版本兼容情况,详情见:
https://www.elastic.co/cn/support/matrix#matrix_compatibility
下载地址为:
https://www.elastic.co/cn/downloads/past-releases
二 下载Kibana
到相应地址,下载即可
解压下载后的文件
三 修改配置文件
修改配置文件:vim 安装目录/config/kibana.yml
# 更多配置信息,详见 https://www.elastic.co/guide/cn/kibana/current/settings.html
server.port: 5601
server.host: "127.0.0.1"
server.name: lqz
elasticsearch.hosts: ["http://localhost:9200/"]
四 启动
到安装目录下:
./bin/kibana
#正常启动
##六 查看
在浏览器里访问:http://localhost:5601/app/kibana
(如访问不到,尝试删除es中跟kibana相关的索引)
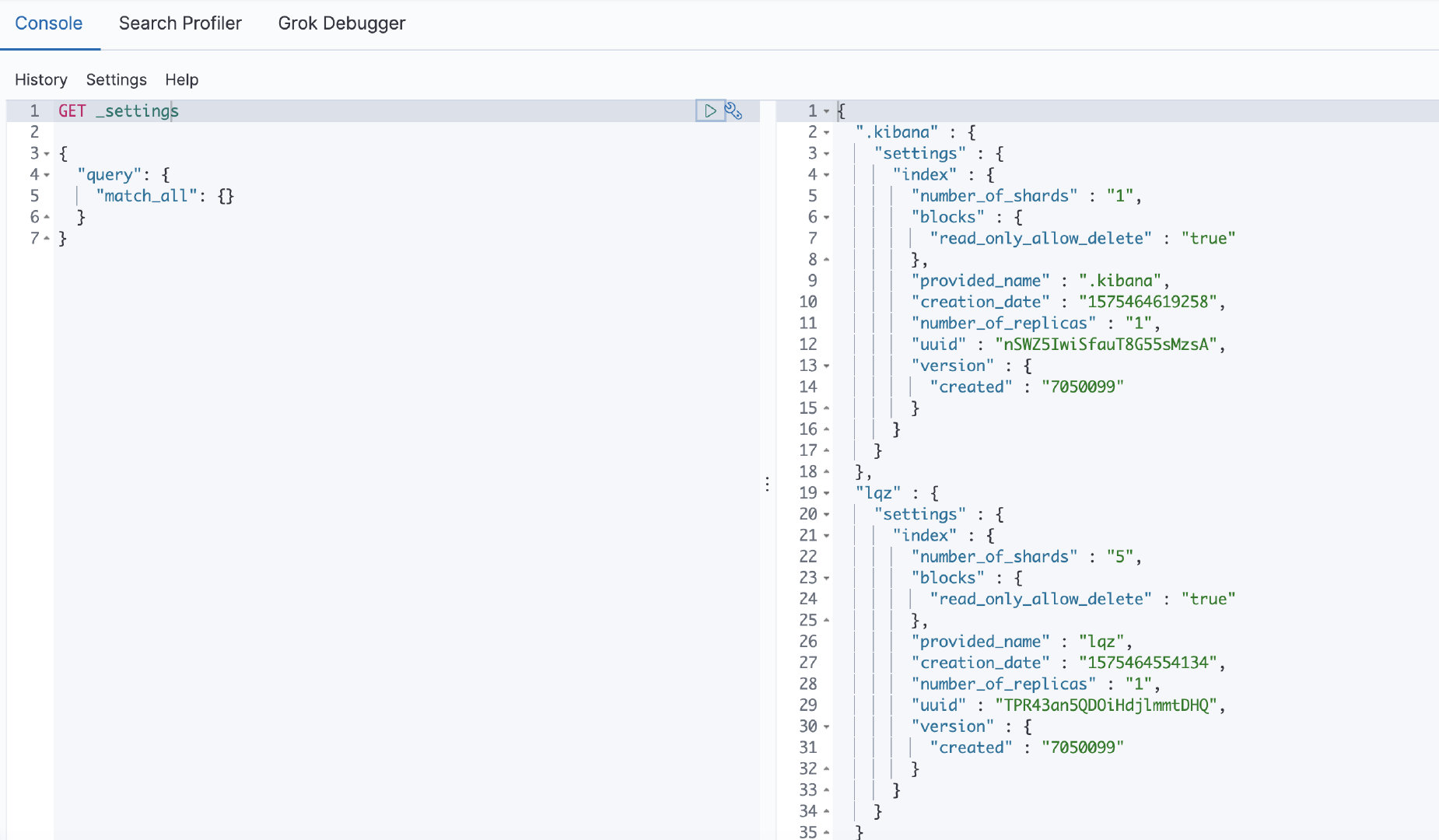
选择Dev Tools
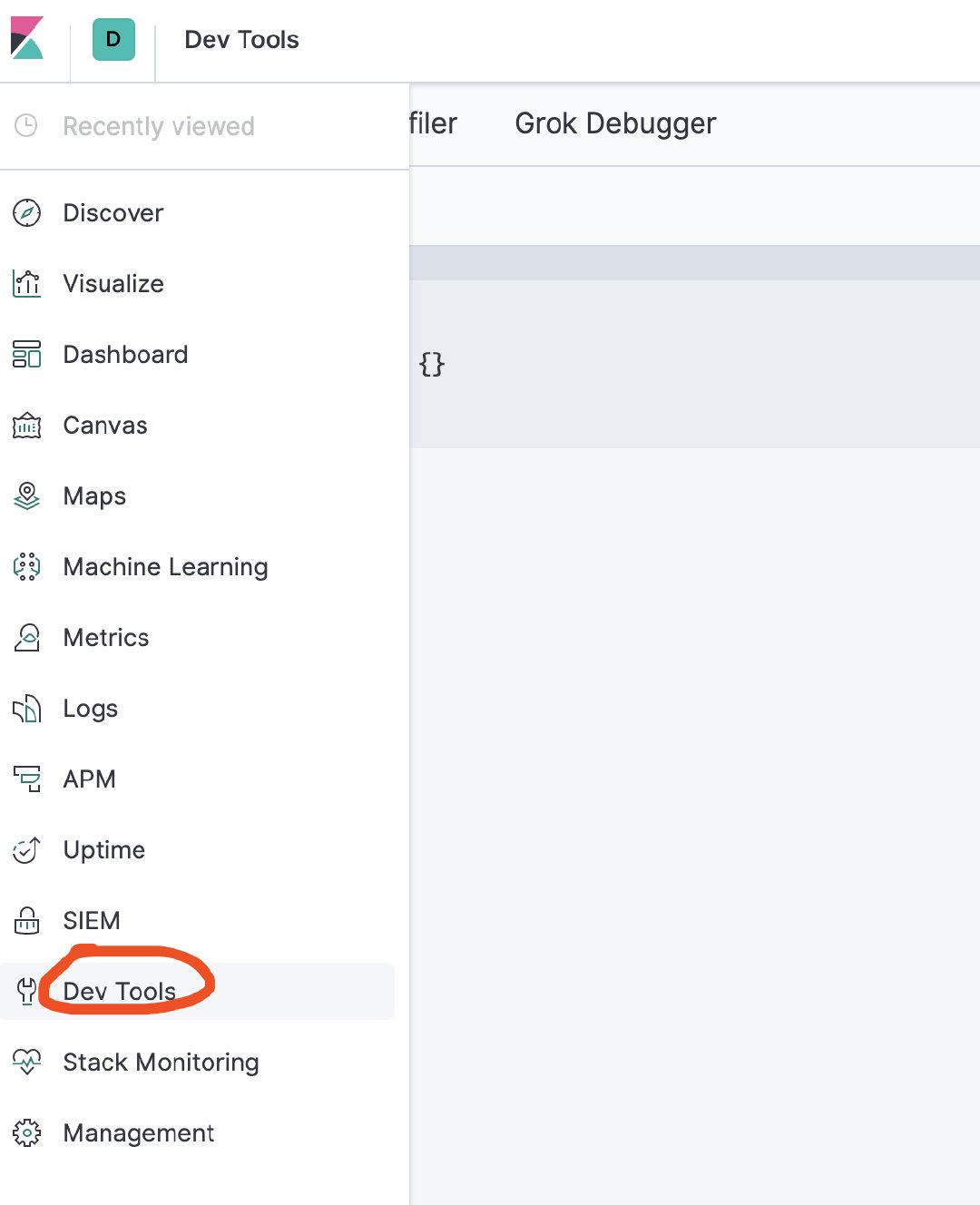
在console中输入GET _settings ,查询可以看到如下
安装中文分词器
一 中文分词介绍
elasticsearch提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词器)、language analyzer(语言分词器)
而如果我们不指定分词器类型的话,elasticsearch默认是使用标准分词器的
我们需要下载中文分词插件,来实现中文分词
二 下载
地址为:https://github.com/medcl/elasticsearch-analysis-ik
安装方式参照【02-ElasticSearch之-插件介绍】
#我们采用第二种,url安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
Elasticsearch之-倒排索引
一 倒排索引是什么
倒排索引源于实际应用中需要根据属性的值来查找记录,这种索引表中的每一个项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而成为倒排索引。带有倒排索引的文件我们称之为倒排索引文件,简称倒排文件
二 举例
例如有如下三个文件:
文件A:通过Python django搭建网站
文件B:通过Python scrapy爬取网站数据
文件C:scrapy-redis分布式爬虫
现在我们要查询,带有Python的文件,正常是对每个文件进行遍历,每个文件遍历一次,如果文件特别大,每个文件有一亿个字符,总共有一亿各文件,每个我们都要遍历,非常消耗资源
在存储文件之前,先对文件进行分析,将文件分词,对分词建立索引,例如下面一句话
1 今天是星期天我们出去玩
2 明天是星期天,放假
3 今天天气很晴朗
4 xxx
5 他们出去玩了
| 关键词 | 文章 |
|---|---|
| 今天 | 文章1,文章3 |
| 星期天 | 文章2 |
| 出去玩 | 文章5,文章1 |
实际上es在做存储的时候,更详细,如下表
| 关键词 | 文章 |
|---|---|
| 今天 | (文章1,<2,10>,2) (文章3,<8>,1) |
| 星期天 | (文章2,<12,25,100>,3) |
| 出去玩 | (文章5,<11,24,89>,3)(文章1,<8,19>,2) |
今天出现在哪个文章,出现的位置和出现的次数
三 倒排索引待解决的问题
1 大小写转换问题,如python和Python应该为同一个词
2 词干抽取,looking和look应该处理为同一个词
3 分词,如 屏蔽系统 是屏蔽 和系统两个词还是 为屏蔽系统一个词
4 倒排索引文件过大,需要压缩编码
Elasticsearch之-索引操作
具体操作可以查看官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices.html>
官方2版本的中文文档
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-settings.html
一 索引初始化
#新建一个lqz2的索引,索引分片数量为5,索引副本数量为1
PUT lqz2
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
'''
number_of_shards
每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。
number_of_replicas
每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
'''
二 查询索引配置
#获取lqz2索引的配置信息
GET lqz2/_settings
#获取所有索引的配置信息
GET _all/_settings
#同上
GET _settings
#获取lqz和lqz2索引的配置信息
GET lqz,lqz2/_settings
三 更新索引
#修改索引副本数量为2
PUT lqz/_settings
{
"number_of_replicas": 2
}
#如遇到报错:cluster_block_exception,因为
#这是由于ES新节点的数据目录data存储空间不足,导致从master主节点接收同步数据的时候失败,此时ES集群为了保护数据,会自动把索引分片index置为只读read-only
PUT _all/_settings
{
"index": {
"blocks": {
"read_only_allow_delete": false
}
}
}
四 删除索引
#删除lqz索引
DELETE lqz
Elasticsearch之-映射管理
在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type。 在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行。 Mapping types将在Elasticsearch 7.0.0中完全删除
一 映射介绍
在创建索引的时候,可以预先定义字段的类型及相关属性
Es会根据Json数据源的基础类型,猜测你想要映射的字段,将输入的数据转变成可以搜索的索引项。
Mapping是我们自己定义的字段数据类型,同时告诉es如何索引数据及是否可以被搜索
作用:会让索引建立的更加细致和完善
1.1 字段数据类型
string类型:text,keyword
数字类型:long,integer,short,byte,double,float
日期类型:data
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表)
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
1.2 映射参数
| 属性 | 描述 | 适合类型 |
|---|---|---|
| store | 值为yes表示存储,no表示不存储,默认为no | all |
| index | yes表示分析,no表示不分析,默认为true | text |
| null_value | 如果字段为空,可以设置一个默认值,比如"NA"(传过来为空,不能搜索,na可以搜索) | all |
| analyzer | 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 | all |
| include_in_all | 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false | all |
| format | 时间格式字符串模式 | date |
二 创建索引
text类型会取出词做倒排索引,keyword不会被分词,原样存储,原样匹配
mapping类型一旦确定,以后就不能修改了
#6.x的版本没问题
PUT books
{
"mappings": {
"book":{
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
}
7.x版本以后
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
插入数据测试:
PUT books/_doc/1
{
"title":"大头儿子小偷爸爸",
"price":100,
"addr":"北京天安门",
"company":{
"name":"我爱北京天安门",
"company_addr":"我的家在东北松花江傻姑娘",
"employee_count":10
},
"publish_date":"2019-08-19"
}
#测试数据2
PUT books/_doc/2
{
"title":"白雪公主和十个小矮人",
"price":"99", #写字符串会自动转换
"addr":"黑暗森里",
"company":{
"name":"我的家乡在上海",
"company_addr":"朋友一生一起走",
"employee_count":10
},
"publish_date":"2018-05-19"
}
三 查看索引
#查看books索引的mapping
GET books/_mapping
#获取所有的mapping
GET _all/_mapping
ElasticSearch系列——介绍、安装、插件介绍、安装ElasticSearch插件、安装Kibana、安装中文分词器、倒排索引、索引操作、映射管理的更多相关文章
- kibana和中文分词器analysis-ik的安装使用
Centos7安装elasticSearch6 上面讲述了elasticSearch6的安装和使用教程. 下面讲一下elasticsearch6的管理工具Kibana. Kibana是一个开源的分析和 ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- elasticsearch安装中文分词器插件smartcn
原文:http://blog.java1234.com/blog/articles/373.html elasticsearch安装中文分词器插件smartcn elasticsearch默认分词器比 ...
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- elasticsearch中文分词器ik-analyzer安装
前面我们介绍了Centos安装elasticsearch 6.4.2 教程,elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,别急,已经有大拿把中文分词器做好了, ...
- 如何给Elasticsearch安装中文分词器IK
安装Elasticsearch安装中文分词器IK的步骤: 1. 停止elasticsearch 2.2的服务 2. 在以下地址下载对应的elasticsearch-analysis-ik插件安装包(版 ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
随机推荐
- tvm-多线程代码生成和运行
本文链接 https://www.cnblogs.com/wanger-sjtu/p/16818492.html 调用链 tvm搜索算子在需要多线程运行的算子,是在codegen阶段时插入TVMBac ...
- iOS select标签适配去掉iOS默认select样式
iOS端对select标签有独特的适配,如何取消这些默认样式呢 css样式表 加上 1 select { 2 -webkit-appearance: none; 3 } 博客同步更新:地址
- 教师节专题:AI互动课来了,即构方案助推在线教育创新升级
打开热门综艺,乘风破浪的姐姐们告诉你"用瓜瓜龙英语给孩子启蒙":走出家门,电梯口.公交站的大幅广告跟你说"2-8岁上斑马". 如果说去年的AI互动课还是浮于媒体 ...
- Linux 命令:ps
ps -ef ps -e f # 树形显示
- VueX报错:Cannot read property 'commit' of undefined
原因 main.js文件中没有引入store 解决方案 添加如下代码即可 import store from "./store"; new Vue({ el: '#app', ro ...
- ChatGPT插件开发实战
1.概述 ChatGPT是一款由OpenAI推出的先进对话模型,其强大的自然语言处理能力使得它成为构建智能对话系统和人机交互应用的理想选择.为了进一步拓展ChatGPT的功能和适应不同领域的需求,Op ...
- 拖拽宫格vue-grid-layout详细应用及案例
目录 1.前言 2.安装 3.属性 4.事件 5.占位符样式修改 6.案例 1.前言 vue-grid-layout是一个适用于vue的拖拽栅格布局库,功能齐全,适用于拖拽+高度/宽度自由调节的布局需 ...
- Linux 身份验证被拒绝,登录失败解决
解决方案: vim /etc/ssh/sshd_config 修改参数 基本参数: PermitRootLogin yes #允许root认证登录 PasswordAuthentication yes ...
- 带你读论文丨S&P21 Survivalism: Living-Off-The-Land 经典离地攻击
本文分享自华为云社区<[论文阅读] (21)S&P21 Survivalism: Living-Off-The-Land经典离地攻击>,作者: eastmount . 摘要 随着恶 ...
- [Lua][Love Engine] 打砖块游戏实现过程与知识点
本文旨在根据LOVE2D官方文档和教程实现打砖块的游戏,记录部分实现过程和重要知识点 目标摧毁所有砖块 玩家控制球拍左右滑动反弹小球 小球摧毁砖块 小球保持在屏幕内 小球碰到屏幕底部,GAME OVE ...