Jsoup+HttpUnit爬取搜狐新闻
怎么说呢,静态的页面,但我也写了动态的接口支持,方便后续爬取别的新闻网站使用。
一个接口,接口有一个抽象方法pullNews用于拉新闻,有一个默认方法用于获取新闻首页:
public interface NewsPuller {
void pullNews();
// url:即新闻首页url
// useHtmlUnit:是否使用htmlunit
default Document getHtmlFromUrl(String url, boolean useHtmlUnit) throws Exception {
if (!useHtmlUnit) {
return Jsoup.connect(url)
//模拟火狐浏览器
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
} else {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(10000);
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(10000);
String htmlString = htmlPage.asXml();
return Jsoup.parse(htmlString);
} finally {
webClient.close();
}
}
}
}
之后就是爬虫;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.WebConsole.Logger;
import com.gargoylesoftware.htmlunit.html.HtmlPage; import java.io.IOException;
import java.net.MalformedURLException;
import java.util.Date;
import java.util.HashSet; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.LoggerFactory; public class SohuNewsPuller implements NewsPuller {
public static void main(String []args) {
System.out.println("123");
SohuNewsPuller ss=new SohuNewsPuller();
ss.pullNews();
}
private String url="http://news.sohu.com/";
public void pullNews() {
Document html= null;
try {
html = getHtmlFromUrl(url, false);
} catch (Exception e) {
e.printStackTrace();
return;
}
// 2.jsoup获取新闻<a>标签
Elements newsATags = html.select("div.focus-news")
.select("div.list16")
.select("li")
.select("a"); for (Element a : newsATags) {
String url = a.attr("href");
System.out.println("内容"+a.text());
Document newsHtml = null;
try {
newsHtml = getHtmlFromUrl(url, false);
Element newsContent = newsHtml.select("div#article-container")
.select("div.main")
.select("div.text")
.first();
String title1 = newsContent.select("div.text-title").select("h1").text();
String content = newsContent.select("article.article").first().text();
System.out.println("url"+"\n"+title1+"\n"+content); } catch (Exception e) {
e.printStackTrace();
}
}
} }
结果:
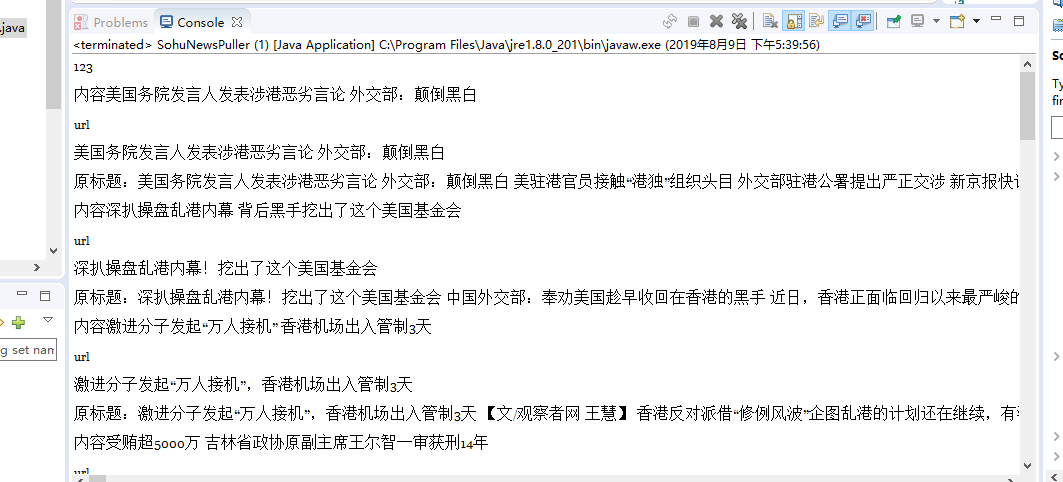
当然还没有清洗内容,后续会清洗以及爬取动态网站啥的。
参考博客:https://blog.csdn.net/gx304419380/article/details/80619043#commentsedit
代码已上传github:https://github.com/mmmjh/GetSouhuNews
欢迎吐槽!!!!
绝大部分代码是参考的人家的博客。我只是把项目还原了。
Jsoup+HttpUnit爬取搜狐新闻的更多相关文章
- 利用Jsoup包爬取网站内容
一 Jsoup包 下载链接:http://download.csdn.net/detail/u014000832/7994245 二 爬取搜狐新闻网站标题等内容 package com.test1; ...
- 利用朴素贝叶斯分类算法对搜狐新闻进行分类(python)
数据来源 https://www.sogou.com/labs/resource/cs.php介绍:来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL ...
- 搜狗输入法弹出搜狐新闻的解决办法(sohunews.exe)
狗输入法弹出搜狐新闻的解决办法(sohunews.exe) 1.找到搜狗输入法的安装目录(一般是C:\program files\sougou input\版本号\)2.右键点击sohunews.ex ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- 【NLP】3000篇搜狐新闻语料数据预处理器的python实现
3000篇搜狐新闻语料数据预处理器的python实现 白宁超 2017年5月5日17:20:04 摘要: 关于自然语言处理模型训练亦或是数据挖掘.文本处理等等,均离不开数据清洗,数据预处理的工作.这里 ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- 基于jieba,TfidfVectorizer,LogisticRegression进行搜狐新闻文本分类
一.简介 此文是对利用jieba,word2vec,LR进行搜狐新闻文本分类的准确性的提升,数据集和分词过程一样,这里就不在叙述,读者可参考前面的处理过程 经过jieba分词,产生24000条分词结果 ...
- 利用jieba,word2vec,LR进行搜狐新闻文本分类
一.简介 1)jieba 中文叫做结巴,是一款中文分词工具,https://github.com/fxsjy/jieba 2)word2vec 单词向量化工具,https://radimrehurek ...
- 利用搜狐新闻语料库训练100维的word2vec——使用python中的gensim模块
关于word2vec的原理知识参考文章https://www.cnblogs.com/Micang/p/10235783.html 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会, ...
随机推荐
- Spring Cloud 服务之间调用
微服务之多个服务间调用 现在又一个学生微服务 user 和 学校微服务 school,如果user需要访问school,我们应该怎么做? 1.使用RestTemplate方式 添加config imp ...
- 第05组 Alpha冲刺(3/4)
第05组 Alpha冲刺(3/4) 队名:天码行空 组长博客连接 作业博客连接 团队燃尽图(共享): GitHub当日代码/文档签入记录展示(共享): 组员情况: 组员1:卢欢(组长) 过去两天完成了 ...
- python写文件时,使用代码强制刷新文件
一.实验环境 1.Windows10x64 2.anaconda4.6.9 + python3.7.1(anaconda集成,不需单独安装) 3.pyinstaller3.5 二.任务需求 三.问题描 ...
- 06-Django视图
什么是视图? 视图就是应用中views.py文件中的函数,视图函数的第一个参数必须是request(HttpRequest)对象.返回的时候必须返回一个HttpResponse对象或子对象(包含Htt ...
- 易飞ERP API接口调用DEMO
一.使用场景: 1.需要开放ERP数据给第三方系统对接,如APP手机端开发,MES,OA等: 2.接口按现在主流开发,restful风格,传JSON数据,跨平台,不限开发工具: 3.不限易飞ERP,支 ...
- Springboot 打包自带启动脚本
一直以来,我都是 gradlew build java -jar xxx.jar 来启动springboot项目的.今天突然发现,springboot自动封装了一个bootJar的任务脚本. demo ...
- 解决No 'Access-Control-Allow-Origin' header is present on the requested resource.跨域问题
跨域错误 错误原因 解决方法在后台写一个过滤器过滤器来改写请求头头 CorsFilter.java public class CorsFilter implements Filter { @Overr ...
- KeContextToKframes函数逆向
在逆向_KiRaiseException(之后紧接着就是派发KiDispatchException)函数时,遇到一个 KeContextToKframes 函数,表面意思将CONTEXT转换为 TRA ...
- .net core入门-跨域访问配置
Asp.net Core 跨域配置 一般情况WebApi都是跨域请求,没有设置跨域一般会报以下错误 No 'Access-Control-Allow-Origin' header is prese ...
- 我用python爬取了知乎Top沙雕问题排行榜
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 数据森麟 PS:如有需要Python学习资料的小伙伴可以加点击下方 ...