DAGScheduler stage 划分算法
DAGScheduler stage 划分算法
stage划分算法很重要,对于spark开发人员来说,必须对stage划分算法很清晰,知道自己编写的spark Application被划分成了几个job,每个job被划分成了几个stage,每个stage包括哪些代码,这样当发现哪个stage报错或者执行特别慢,才能针对对应代码排查问题和性能调优
stage 划分思想:
由submitStage() 和getMissingParentStage() 组成
会从触发Action操作的那个RDD开始往前,首先为最后一个RDD创建一个stage,然后在往前,如果遇到某个RDD是宽依赖,就会为宽依赖创建一个新的stage,新的RDD就是最新的stage的最后一个RDD,然后以依次类推,继续往前,根据宽依赖或者窄依赖进行stage划分,知直到最后一个RDD遍历完为止
stage划分步骤:
1、使用出发job的最后一个RDD,创建finalStage(创建一个stage对象,并且将stage加入到DAGScheduler内部的内存缓存中)
2、使用finalStage创建一个job(这个job的最后一个stage,就是 finalStage)
3、将job加入到内存缓存中
4、使用 submitStage() 提交 finalStage
提交stage的方法(stage划分算法入口):
调用 getMissingParentStage() 获取当前这个 stage 的父 stage:
往栈中推入stage的最后一个RDD
while循环对stage的最后一个RDD,调用自己定义的visit()方法
visit():如果是窄依赖,将RDD放入栈中,如果是宽依赖,使用宽依赖的那个RDD创建一个stage,将isShuffleMap设为true
提交stage,为stage创建一批task,task数量与Partition数量相同
计算每个task对应的Partition的最佳位置(就是从stage最后一个RDD开始,去找被cache或checkpoint的RDD的Partition,task的最佳位置,就是该Partition的位置,这样task就在那个节点上执行,不需要计算之前的RDD;如果从最后一个RDD到最开始的RDD,都没有被cache或checkpoint,那么最佳位置就是Nil,就是没有最佳位置)
5.、针对stage的task,创建TaskSet对象,调用TaskScheduler的submitTask方法,提交TaskSet,提交到Excutor上去执行
总结如下:
1、从finalstage倒推,
2、通过宽依赖进行新的stage划分
3、使用递归,优先提交父stage
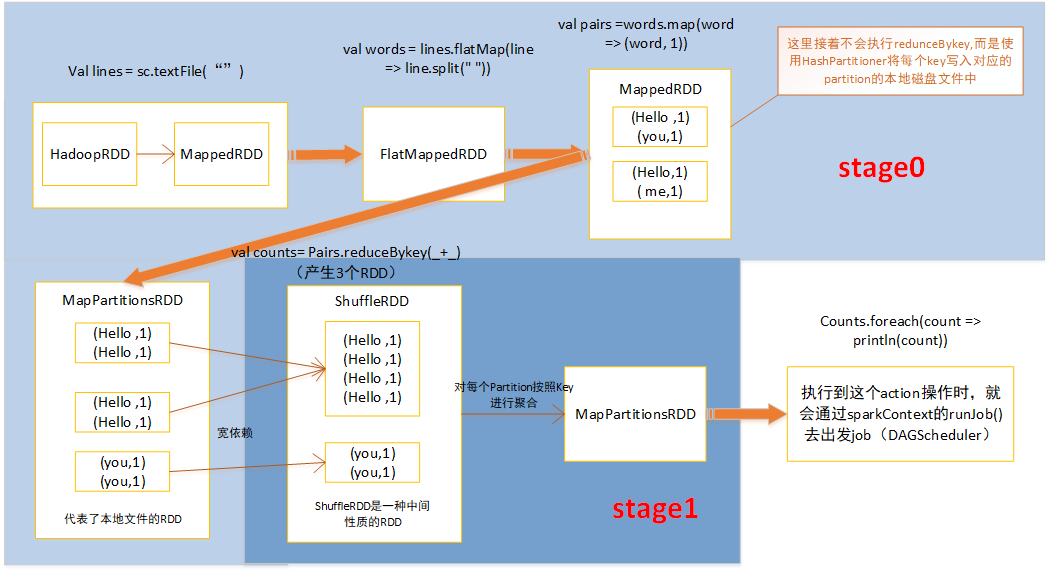
对于每一种有shuffle的操作。底层对应了三个RDD:MapPartitionsRDD、ShuffleRDD、MapPartitionsRDD
DAGScheduler stage 划分算法的更多相关文章
- 17、stage划分算法原理及DAGScheduler源码分析
一.stage划分算法原理 1.图解 二.DAGScheduler源码分析 1. ###org.apache.spark/SparkContext.scala // 调用SparkContext,之前 ...
- Spark源码剖析(八):stage划分原理与源码剖析
引言 对于Spark开发人员来说,了解stage的划分算法可以让你知道自己编写的spark application被划分为几个job,每个job被划分为几个stage,每个stage包括了你的哪些代码 ...
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
- Stage划分和Task最佳位置算法源码彻底解密
本课主题 Job Stage 划分算法解密 Task 最佳位置算法实现解密 引言 作业调度的划分算法以及 Task 的最佳计算位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- Spark任务提交底层原理
Driver的任务提交过程 1.Driver程序的代码运行到action操作,触发了SparkContext的runJob方法.2.SparkContext调用DAGScheduler的runJob函 ...
- 一个Spark job的生命历程
一个job的生命历程 dagScheduler.runJob //(1) --> submitJob ( eventProcessLoop.post(JobSubmitted,***) //(2 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
随机推荐
- window下 phpstorm 打不开
如果 window 上不能执行 strace 命令, 安装 Git Bash 工具. 切换到 phpstorm 安装的 bin 目录: D 盘的相关文件昨天被我删了!奇怪这文件怎么放到那里了? 换个路 ...
- Sieve of Eratosthenes时间复杂度的感性证明
上代码. #include<cstdio> #include<cstdlib> #include<cstring> #define reg register con ...
- python日记:用pytorch搭建一个简单的神经网络
最近在学习pytorch框架,给大家分享一个最最最最基本的用pytorch搭建神经网络并且训练的方法.本人是第一次写这种分享文章,希望对初学pytorch的朋友有所帮助! 一.任务 首先说下我们要搭建 ...
- opencv::两张图片的线性融合
理论-线性混合操作 g(x) 表示 融合图片中的像素点,f0(x) 和 f1(x) 分别表示背景和前景图片中的像素点. //参数1:输入图像Mat – src1 //参数2:输入图像src1的alph ...
- HDU 1506 Largest Rectangle in a Histogram(区间DP)
题目网址:http://acm.hdu.edu.cn/showproblem.php?pid=1506 题目: Largest Rectangle in a Histogram Time Limit: ...
- PostgreSQL使用安装
PostgreSQL使用安装 一. 安装 ubuntu安装: # 安装客户端 sudo apt-get install postgresql-client # 安装服务器 sudo apt-get i ...
- 百万年薪python之路 -- 请求跨域和CORS协议详解
楔子 什么是同源策略 同源策略,它是由Netscape提出的一个著名的安全策略.现在所有支持JavaScript 的浏览器都会使用这个策略.所谓同源是指,域名,协议,端口相同.当一个浏览器的两个tab ...
- Newtonsoft—Json.NET常用方法简述
Json.NET常用方法汇总(可解决日常百分之90的需求) 0.Json.NET基础用法 首先去官网下载最新的Newtonsoft.Json.dll(也可以使用VS自带的NuGet搜索Json.NET ...
- 设计模式(十八)Memento模式
在使用面向对象编程的方式实现撤销功能时,需要事先保存实例的相关状态信息.然后,在撤销时,还需要根据所保存的信息将实例恢复至原来的状态. 要想恢复实例,需要一个可以自由访问实例内部结构的权限.但是,如果 ...
- swiper轮播
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...