spark-2.4.0-hadoop2.7-简单操作
1. 说明
本文基于:spark-2.4.0-hadoop2.7-高可用(HA)安装部署
2. 启动Spark Shell
在任意一台有spark的机器上执行
# --master spark://mini02:7077 连接spark的master,这个master的状态为alive,而不是standby
# --total-executor-cores 总共占用2核CPU
# --executor-memory 512m 每个woker占用512m内存
[yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m
-- :: WARN NativeCodeLoader: - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://mini03:4040
Spark context available as 'sc' (master = spark://mini02:7077, app id = app-20181125120746-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information. scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@77e1b84c
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
2.1. 相关截图
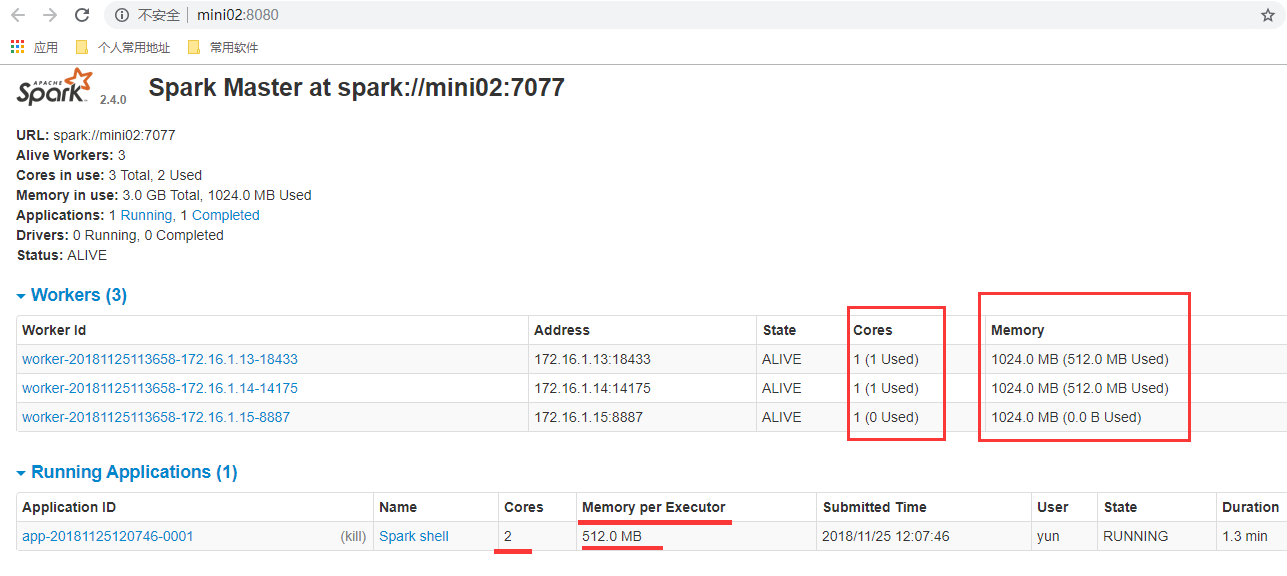
3. 执行第一个spark程序
该算法是利用蒙特•卡罗算法求PI
[yun@mini03 ~]$ spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://mini02:7077 \
--total-executor-cores \
--executor-memory 512m \
/app/spark/examples/jars/spark-examples_2.-2.4..jar
# 打印的信息如下:
-- :: WARN NativeCodeLoader: - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-- :: INFO SparkContext: - Running Spark version 2.4.
………………
-- :: INFO TaskSetManager: - Finished task 97.0 in stage 0.0 (TID ) in ms on 172.16.1.14 (executor ) (/)
-- :: INFO TaskSetManager: - Finished task 98.0 in stage 0.0 (TID ) in ms on 172.16.1.13 (executor ) (/)
-- :: INFO TaskSetManager: - Finished task 99.0 in stage 0.0 (TID ) in ms on 172.16.1.14 (executor ) (/)
-- :: INFO TaskSchedulerImpl: - Removed TaskSet 0.0, whose tasks have all completed, from pool
-- :: INFO DAGScheduler: - ResultStage (reduce at SparkPi.scala:) finished in 3.881 s
-- :: INFO DAGScheduler: - Job finished: reduce at SparkPi.scala:, took 4.042591 s
Pi is roughly 3.1412699141269913
………………
4. Spark shell求Word count 【结合Hadoop】
1、启动Hadoop
2、将文件放到Hadoop中
[yun@mini05 sparkwordcount]$ cat wc.info
zhang linux
linux tom
zhan kitty
tom linux
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /
Found items
drwxr-xr-x - yun supergroup -- : /hbase
drwx------ - yun supergroup -- : /tmp
drwxr-xr-x - yun supergroup -- : /wordcount
-rw-r--r-- yun supergroup -- : /zookeeper-3.4..tar.gz
[yun@mini05 sparkwordcount]$ hdfs dfs -mkdir -p /sparkwordcount/input
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/input
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
3、进入spark shell命令行,并计算
[yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m
# 计算完毕后,打印在命令行
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_).sortBy(_._2, false).collect
res6: Array[(String, Int)] = Array((linux,), (tom,), (kitty,), (zhan,), ("",), (zhang,))
# 计算完毕后,保存在HDFS【因为有多个文件组成,则有多个reduce,所以输出有多个文件】
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output")
# 计算完毕后,保存在HDFS【将reduce设置为1,输出就只有一个文件】
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_, ).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output1")
4、在HDFS的查看结算结果
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/
Found items
drwxr-xr-x - yun supergroup -- : /sparkwordcount/input
drwxr-xr-x - yun supergroup -- : /sparkwordcount/output
drwxr-xr-x - yun supergroup -- : /sparkwordcount/output1
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/_SUCCESS
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
[yun@mini05 sparkwordcount]$
[yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output/part*
(linux,)
(tom,)
(,)
(zhang,)
(kitty,)
(zhan,)
###############################################
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output1
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/output1/_SUCCESS
-rw-r--r-- yun supergroup -- : /sparkwordcount/output1/part-
[yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output1/part-
(linux,)
(tom,)
(,)
(zhang,)
(kitty,)
(zhan,)
spark-2.4.0-hadoop2.7-简单操作的更多相关文章
- spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0
1.准备: centos 6.5 jdk 1.7 Java SE安装包下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- spark sql的简单操作
测试数据 sparkStu.text zhangxs chenxy wangYr teacher wangx teacher sparksql { ,"job":"che ...
- moloch1.8.0简单操作手册
moloch1.8.0简单操作手册 Sessions 页面:Sessions主要通过非常简单的查询语言来构建表达式追溯数据流量,以便分析. SPIView 页面: SPIGraph页面:SPIGrap ...
- spark 1.1.0 单机与yarn部署
环境:ubuntu 14.04, jdk 1.6, scala 2.11.4, spark 1.1.0, hadoop 2.5.1 一 spark 单机模式 部分操作参考:http://www.cnb ...
- Spark快速入门 - Spark 1.6.0
Spark快速入门 - Spark 1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 快速入门(Quick Start) 本文简单介绍了Spark的使用方式.首 ...
- Apache Spark 2.2.0 中文文档 - Spark 编程指南 | ApacheCN
Spark 编程指南 概述 Spark 依赖 初始化 Spark 使用 Shell 弹性分布式数据集 (RDDs) 并行集合 外部 Datasets(数据集) RDD 操作 基础 传递 Functio ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
随机推荐
- hdfs创建删除文件和文件夹
在 hadoop 中,基于 Linux 命令可以给 hdfs 创建文件和文件夹,或者删除文件和文件夹 创建文件的命令为: hadoop fs -touch /file.txt 创建文件夹的命令为: h ...
- JVM垃圾回收
1. 概念理解 1.1. 并行(Parallel)与并发(Concurrent) 并行:指多个垃圾收集线程并行工作,但此时用户线程仍然处于等待状态 并发:指用户线程与垃圾收集线程同时执行 1.2. ...
- 《连连看》算法c语言演示(自动连连看)
(图片是游戏的示意图,来自互联网,与本文程序无关) 看题目就知道是写给初学者的,没需要的就别看了,自己都觉得怪无聊的. 很多游戏的耐玩性都来自精巧的算法,特别是人工智能的水平.比如前几天看了著名的Al ...
- C#2.0之细说泛型
C#2的头号亮点 : 泛型 在C#1中,Arraylist总是会给人带来困扰,因为它的参数类型是Object,这就让开发者无法把握集合中都有哪些类型的数据.如果对string类型的数据进行算术操作那自 ...
- 【c#】RabbitMQ学习文档(三)Publish/Subscribe(发布/订阅)
(本教程是使用Net客户端,也就是针对微软技术平台的) 在前一个教程中,我们创建了一个工作队列.工作队列背后的假设是每个任务会被交付给一个[工人].在这一部分我们将做一些完全不同的事情--我们将向多个 ...
- 【SpringCloud】HystrixCommand的threadPoolKey默认值及线程池初始化
关于threadPoolKey默认值的疑问 使用SpingCloud必然会用到Hystrix做熔断降级,也必然会用到@HystrixCommand注解,@HystrixCommand注解可以配置的除了 ...
- -1-4 java io java流 常用流 分类 File类 文件 字节流 字符流 缓冲流 内存操作流 合并序列流
File类 •文件和目录路径名的抽象表示形式 构造方法 •public File(String pathname) •public File(String parent,Stringchild) ...
- js内存深入学习(一)
一. 内存空间储存 某些情况下,调用堆栈中函数调用的数量超出了调用堆栈的实际大小,浏览器会抛出一个错误终止运行.这个就涉及到内存问题了. 1. 数据结构类型 栈: 后进先出(LIFO)的数据结构 堆 ...
- tomcat 大并发报错 Maximum number of threads (200) created for connector with address null and port 80
1.INFO: Maximum number of threads (200) created for connector with address null and port 80 说明:最大线程数 ...
- Oracle day05 索引_数据去重
索引 自动:当在表上定义一个primary key或者unique 约束条件时,oracle数据库自动创建一个对应的唯一索引. 手动:用户可以创建索引以加速查询 在一列或者多列上创建索引: creat ...