【Storm篇】--Storm从初始到分布式搭建
一、前述
Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架。
二 、搭建流程
1.集群规划
Nimbus Supervisor Zookeeper
node01 1
node02 1 1
node03 1 1
node04 1 1
2.配置
node01作为nimbus。
vim conf/storm.yaml
storm.zookeeper.servers:
- "node02"
- "node03"
- "node04" storm.local.dir: "/tmp/storm" nimbus.host: "node01" supervisor.slots.ports:
-
-
-
-
PS:supervisor.slots.ports 相当于启动4个worker进程
配置一定要顶格写!!!!!!!
3.创建log文件
在storm目录中创建logs目录
mkdir logs启动ZooKeeper集群
4.启动服务
node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
tail -f logs/nimbus.log
./bin/storm ui >> ./logs/ui.out 2>&1 &
tail -f logs/ui.log 节点node02和node03,node04启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
tail -f logs/supervisor.log
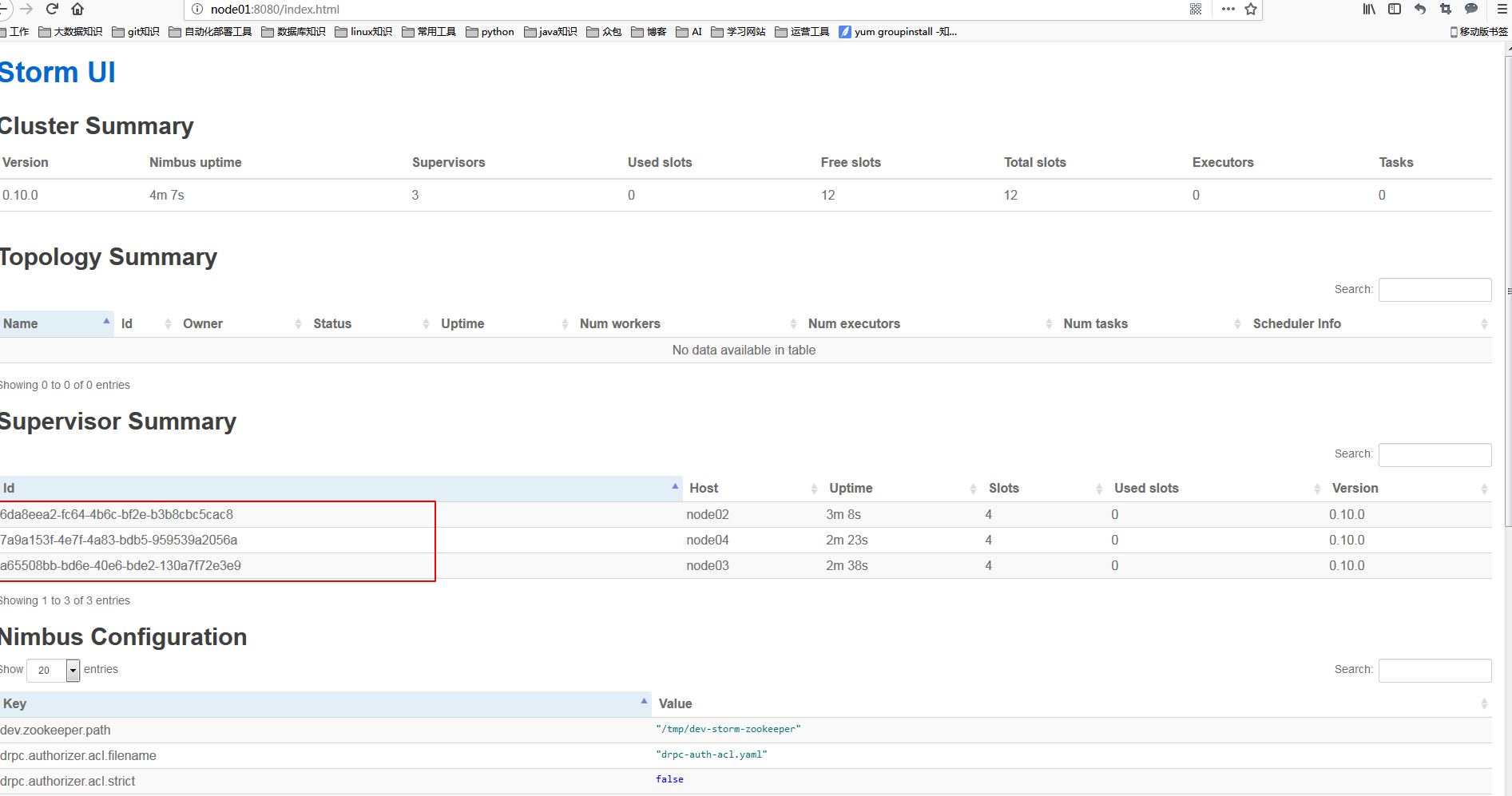
(当然node1也可以启动supervisor) http://node1:8080/
提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test 环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=$PATH:$STORM_HOME/bin
【Storm篇】--Storm从初始到分布式搭建的更多相关文章
- Storm伪分布式搭建
配置zookeeper 下载zookeeper tar包 解压:tar -zxvf zookeeper-3.4.10.tar.gz -C /root/training/ 配置 cd /root/tra ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【Storm篇】--Storm基础概念
一.前述 Storm是个实时的.分布式以及具备高容错的计算系统,Storm进程常驻内存 ,Storm数据不经过磁盘,在内存中处理. 二.相关概念 1.异步: 流式处理(异步)客户端提交数据进行结算,并 ...
- 【Storm】Storm实战之频繁二项集挖掘
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 【Storm】Storm实战之频繁二项集挖掘(附源码)
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 第三篇——第二部分——第二文 计划搭建SQL Server镜像
原文:第三篇--第二部分--第二文 计划搭建SQL Server镜像 本文紧跟上一章:SQL Server镜像简介 本文出处:http://blog.csdn.net/dba_huangzj/arti ...
- Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备 1,hadoop-2.7.3.tar.gz(包) 2,三台机器装有cetos7的机子 (二)安装步骤 1,给每台机子配相同的用户 进入root : su root ---------& ...
随机推荐
- .Net Core小技巧 - Hosted Services + Quartz实现定时任务调度
背景 之前一直有朋友问,.Net Core + Linux环境有没有类似Windows服务的东西.其实是有的,我了解的方法有两种: #1 创建一个ASP.Net Core的Web项目(如Web API ...
- 029 Es面试小节
1.大纲 Es是什么?处理哪种业务逻辑用的多? Es类比数据库是什么? 对于数据库的字段.表等,在es中叫什么? Es的refresh把数据写到哪里? Es的数据如何变成检索和聚合索引的? Es的fl ...
- setParameter不支持传统的按位置查询方式
setParameter不支持传统的按位置查询方式 String hql = "from Customer as c where c.cust_id = ?"; List<C ...
- Windows linux子系统 使用说明
1.安装 linux 子系统 2.应用商店安装ubuntu 3.为了方便可以配置成默认登陆root账户 Ubuntu config –default-user root 4. 安装完毕 5.安 ...
- nginx.conf 中php-ftp配置
location ~ .php$ { root /home/www; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; fastcgi_par ...
- Python数据处理PDF
Python数据处理(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1h8a5-iUr4mF7cVujgTSGOA 提取码:6fsl 复制这段内容后打开百度网盘手机A ...
- angular.uppercase()
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- for循环:用turtle画一颗五角星
import turtle # 设置初始位置 turtle.penup() turtle.left(90) turtle.fd(200) turtle.pendown() turtle.right(9 ...
- csv 数据
csv数据:逗号分隔值,其文件以纯文本的形式存储表格数据(数据和文本).csv模块是python的内置模块,需要引用后再使用 csv.reader(csv_file) #使用with结构 with o ...
- idea远程打断点
(1)用如下方式启动jar java -Xdebug -Xrunjdwp:transport=dt_socket,address=5005,server=y,suspend=y -jar durati ...