【Storm篇】--Storm从初始到分布式搭建
一、前述
Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架。
二 、搭建流程
1.集群规划
Nimbus Supervisor Zookeeper
node01 1
node02 1 1
node03 1 1
node04 1 1
2.配置
node01作为nimbus。
vim conf/storm.yaml
storm.zookeeper.servers:
- "node02"
- "node03"
- "node04" storm.local.dir: "/tmp/storm" nimbus.host: "node01" supervisor.slots.ports:
-
-
-
-
PS:supervisor.slots.ports 相当于启动4个worker进程
配置一定要顶格写!!!!!!!
3.创建log文件
在storm目录中创建logs目录
mkdir logs启动ZooKeeper集群
4.启动服务
node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
tail -f logs/nimbus.log
./bin/storm ui >> ./logs/ui.out 2>&1 &
tail -f logs/ui.log 节点node02和node03,node04启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
tail -f logs/supervisor.log
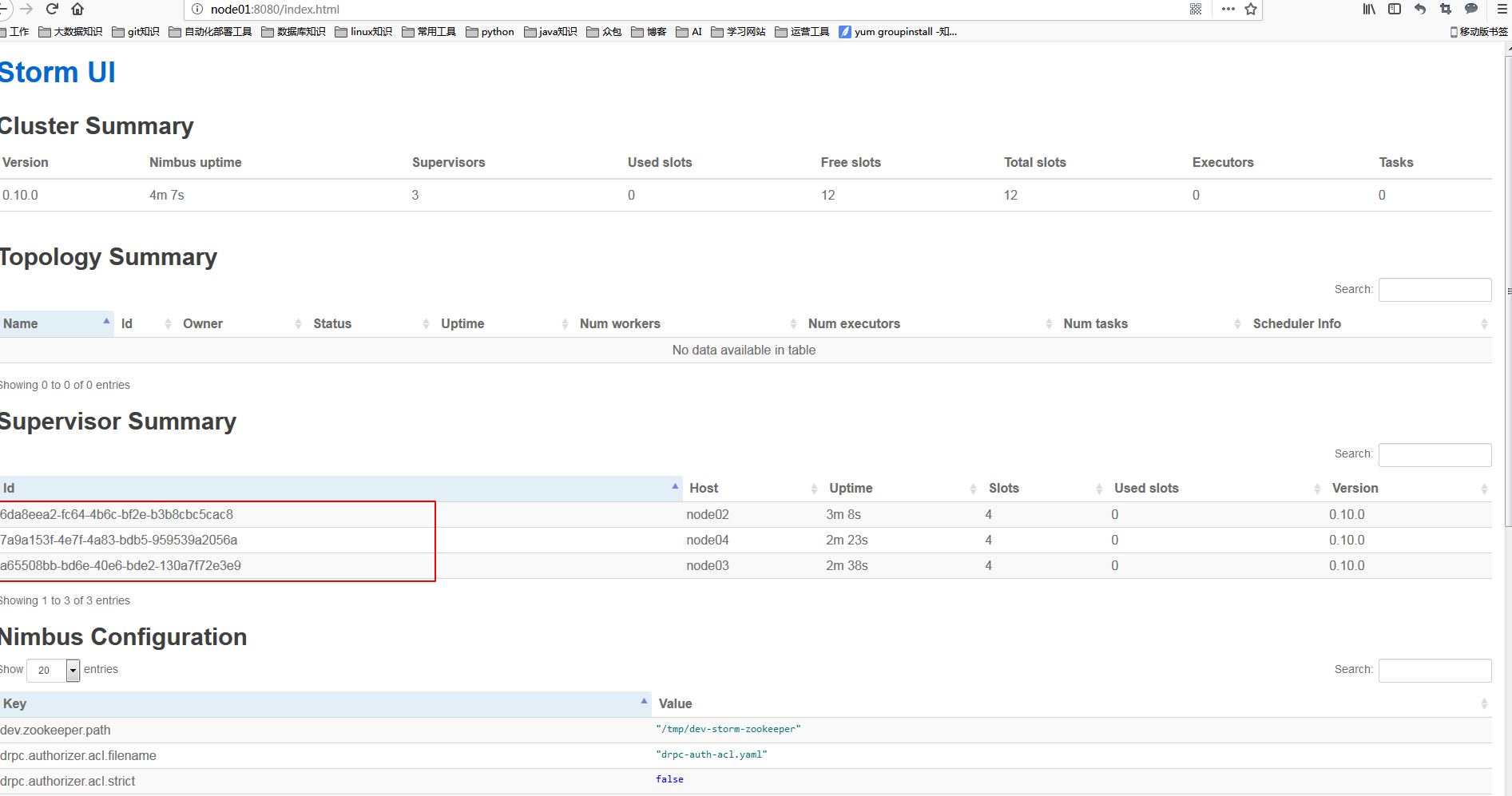
(当然node1也可以启动supervisor) http://node1:8080/
提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test 环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=$PATH:$STORM_HOME/bin
【Storm篇】--Storm从初始到分布式搭建的更多相关文章
- Storm伪分布式搭建
配置zookeeper 下载zookeeper tar包 解压:tar -zxvf zookeeper-3.4.10.tar.gz -C /root/training/ 配置 cd /root/tra ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【Storm篇】--Storm基础概念
一.前述 Storm是个实时的.分布式以及具备高容错的计算系统,Storm进程常驻内存 ,Storm数据不经过磁盘,在内存中处理. 二.相关概念 1.异步: 流式处理(异步)客户端提交数据进行结算,并 ...
- 【Storm】Storm实战之频繁二项集挖掘
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 【Storm】Storm实战之频繁二项集挖掘(附源码)
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 第三篇——第二部分——第二文 计划搭建SQL Server镜像
原文:第三篇--第二部分--第二文 计划搭建SQL Server镜像 本文紧跟上一章:SQL Server镜像简介 本文出处:http://blog.csdn.net/dba_huangzj/arti ...
- Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备 1,hadoop-2.7.3.tar.gz(包) 2,三台机器装有cetos7的机子 (二)安装步骤 1,给每台机子配相同的用户 进入root : su root ---------& ...
随机推荐
- Jmeter性能测试报告扩展
自动收集采集结果:运行完毕后,自动出结果:
- UOJ#291. 【ZJOI2017】树状数组 树套树
原文链接https://www.cnblogs.com/zhouzhendong/p/UOJ291.html 题解 结论:这个写错的树状数组支持的是后缀加和后缀求和.这里的后缀求和在 x = 0 的时 ...
- flink学习
flink介绍: Apache Flink is an open source platform for distributed stream and batch data processing. F ...
- Linux从入门到进阶全集——【第十四集:Shell基础命令】
1,Shell就是命令行执行器 2,作用:将外层引用程序的例如ls ll等命令进行解释成01表示的二进制代码给内核,从而让硬件执行:硬件的执行结果返回给shell,shell解释成我们能看得懂的代码返 ...
- ZOJ 2588 Burning Bridges 割边(处理重边)
<题目链接> 题目大意: 给定一个无向图,让你尽可能的删边,但是删边之后,仍然需要保证图的连通性,输出那些不能被删除的边. 解题分析: 就是无向图求桥的题目,主要是提高一下处理重边的姿势. ...
- Spark WordCount的两种方式
Spark WordCount的两种方式. 语言:Java 工具:Idea 项目:Java Maven pom.xml如下: <properties> <spark.version& ...
- Python3系列__01Python安装
Python和Java一样是跨平台的,它可以运行在Windows.Mac和各种Linux/Unix系统上.所以你在一个平台上面上写的代码在另一个平台仍能正常运行. 要学习Python编程,你需要做的就 ...
- PHP中获取某个网页或文件内容的方法
1. 通过file_get_contents()函数$contents = file_get_contents('http://demo.com/index.php');echo $contents; ...
- centos7系统下搭建docker本地镜像仓库
## 准备工作 用到的工具, Xshell5, Xftp5, docker.io/registry:latest镜像 关于docker的安装和设置加速, 请参考这篇博文centos7系统下 docke ...
- javascript是什么,可以做什么?
是一门脚本语言:不需要编译,直接运行 是一门解释型语言:遇到一行代码就解释一行代码 是一门动态类型的语言 是一门基于对象的语言 是一门弱类型的语言:声明变量的时候不用特别声明类型都使用var 不是一门 ...