HanLP中文分词Lucene插件
基于HanLP,支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统。
Maven
<dependency>
<groupId>com.hankcs.nlp</groupId>
<artifactId>hanlp-lucene-plugin</artifactId>
<version>1.1.6</version>
</dependency>
Solr快速上手
1.将hanlp-portable.jar和hanlp-lucene-plugin.jar共两个jar放入${webapp}/WEB-INF/lib下。(或者使用mvn package对源码打包,拷贝target/hanlp-lucene-plugin-x.x.x.jar到${webapp}/WEB-INF/lib下)
2. 修改solr core的配置文件${core}/conf/schema.xml:
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
<!-- 业务系统中需要分词的字段都需要指定type为text_cn -->
<field name="my_field1" type="text_cn" indexed="true" stored="true"/>
<field name="my_field2" type="text_cn" indexed="true" stored="true"/>
· 如果你的业务系统中有其他字段,比如location,summary之类,也需要一一指定其type="text_cn"。切记,否则这些字段仍旧是solr默认分词器。
· 另外,切记不要在query中开启indexMode,否则会影响PhaseQuery。indexMode只需在index中开启一遍即可。
高级配置
目前本插件支持如下基于schema.xml的配置:
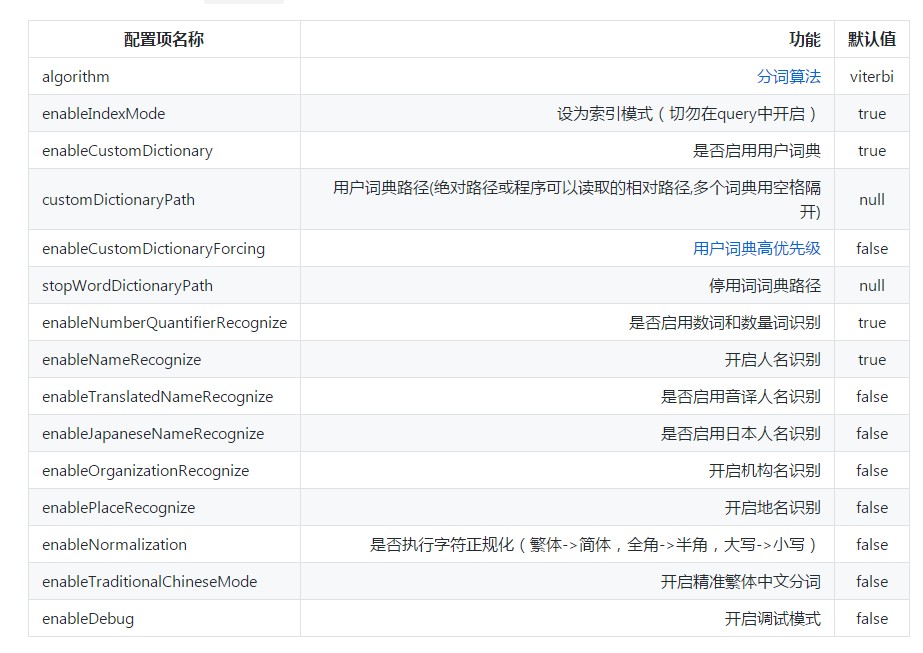
更高级的配置主要通过class path下的hanlp.properties进行配置,请阅读HanLP自然语言处理包文档以了解更多相关配置,如:
0.用户词典
1.词性标注
2.简繁转换
3.……
停用词与同义词
推荐利用Lucene或Solr自带的filter实现,本插件不会越俎代庖。 一个示例配置如下:

调用方法
在Query改写的时候,可以利用HanLPAnalyzer分词结果中的词性等属性,如
String text = "中华人民共和国很辽阔";
for (int i = 0; i < text.length(); ++i)
{
System.out.print(text.charAt(i) + "" + i + " ");
}
System.out.println();
Analyzer analyzer = new HanLPAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("field", text);
tokenStream.reset();
while (tokenStream.incrementToken())
{
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
// 偏移量
OffsetAttribute offsetAtt = tokenStream.getAttribute(OffsetAttribute.class);
// 距离
PositionIncrementAttribute positionAttr = tokenStream.getAttribute(PositionIncrementAttribute.class);
// 词性
TypeAttribute typeAttr = tokenStream.getAttribute(TypeAttribute.class);
System.out.printf("[%d:%d %d] %s/%s\n", offsetAtt.startOffset(), offsetAtt.endOffset(), positionAttr.getPositionIncrement(), attribute, typeAttr.type());
}
在另一些场景,支持以自定义的分词器(比如开启了命名实体识别的分词器、繁体中文分词器、CRF分词器等)构造HanLPTokenizer,比如:
tokenizer = new HanLPTokenizer(HanLP.newSegment()
.enableJapaneseNameRecognize(true)
.enableIndexMode(true), null, false);
tokenizer.setReader(new StringReader("林志玲亮相网友:确定不是波多野结衣?"));
文章摘自:2019 github
HanLP中文分词Lucene插件的更多相关文章
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Elasticsearch之中文分词器插件es-ik(博主推荐)
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch之分词器的工作流程 Elasticsearch之停用词 Elasticsearch之中文分词器 Elasti ...
- Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货! 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- elasticsearch安装中文分词器插件smartcn
原文:http://blog.java1234.com/blog/articles/373.html elasticsearch安装中文分词器插件smartcn elasticsearch默认分词器比 ...
- lucene6+HanLP中文分词
1.前言 前一阵把博客换了个模版,模版提供了一个搜索按钮,这让我想起一直以来都想折腾的全文搜索技术,于是就用lucene6.2.1加上HanLP的分词插件做了这么一个模块CSearch.效果看这里:h ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
随机推荐
- Flutter错误集合
一.Waiting for another flutter command to release the startup lock... 运行flutter命令 flutter upgrade 运行 ...
- 详细集成Redis (一)
1.添加依赖 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</a ...
- 利用Excel-Vba进行多表汇总和数据透视表
汇总表格式 详情表格式 要求根据汇总表中的信息,到详情表中查找详细物料的具体个数 最终,对物料的个数进行汇总,结果如下图: ExcelVba代码如下(有一些注释代码供参考) Sub Start() S ...
- mysql命令行下创建数据库,创建表,插入数据,查询数据
1.创建数据库 mysql> create DATABASE booktik -> ;Query OK, 1 row affected (0.02 sec) 2.创建表 mysql> ...
- linux install ftp server
first yum install vsftpd 第二部:vi /etc/vsftpd/vsftpd.conf 添上下面一段话 anonymous_enable=YESlocal_enable=YE ...
- JS的call与apply的用法
call与apply的第一个参数都是需要调用的函数对象,在函数体内这个参数就是this的值,剩余的参数是需要传递给函数的值,call与apply的不同就是call传的值可以是任意的,而apply传的剩 ...
- [date] 时间问题: 更新时间距离现在3个月
public static void main(String[] args) { Date d1 = null; try { d1 = DateFormatUtil.StringToDate(&quo ...
- django用MySQL数据库链接
在使用的过程中出现了没有mysqld.sock这个文件的情况,无法连接到mysql数据库. 几经周折,设置路径,改文件夹的权限,也都无济于事,只有重新安装mysql服务器,第一次尝试还是失败,服务器安 ...
- 《Spring实战》读书笔记——如何实现自动化装配
加我微信公众号,一起夯实Java基础,向着诗和远方出发吧~ 如果所有的装配工作都交给Spring来自动完成,减少人工的干预,是不是就能减少依赖关系配置带来的麻烦呢?认真做自己的事儿吧,装配交给Spri ...
- java中,字符串类型的时间数据怎样转换成date类型。
将字符串类型的时间转换成date类型可以使用SimpleDateFormat来转换,具体方法如下:1.定义一个字符串类型的时间:2.创建一个SimpleDateFormat对象并设置格式:3.最后使用 ...