075 importSTV的使用,与bulkload的使用
一:由HDFS将数据直接导入到HBase中
1.生成TSV文件
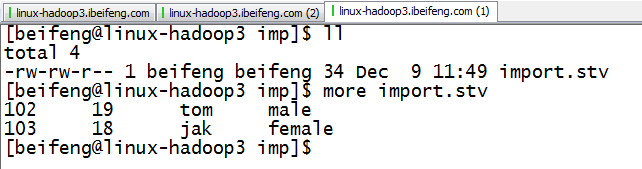
2.内容

3.上传到HDFS

4.运行
export HBASE_HOME=/etc/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`
export HADOOP_HOME=/etc/opt/modules/hadoop-2.5.0
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb1 /imp/import.tsv
重要的是:
)HBASE_ROW_KEY
)info:name,等都要和import.tsv相对应
)目录是HDFS的目录
)表名是将要书写进去的表名
5.结果

二:将数据转换为HFile
1.将数据转为HFile
hbase-0.98.6-hadoop2]$ $HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.bulk.output=/impout -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
其中:nstest1:tb2的作用是按照这个表的格式进行转换HFile
/impout 是HFile的路径。

2.将HFile保存进HBase
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar completebulkload /impout nstest1:tb2
3.结果
HDFS中的HFile数据不再存在

HBase的结果

三:自定义分隔符
1.新定义文件

2.删除以前的文件,再重新上传文件
3.运行
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.separator=,
-Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
3.结果

075 importSTV的使用,与bulkload的使用的更多相关文章
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- 【hbase】——HBase 写优化之 BulkLoad 实现数据快速入库
1.为何要 BulkLoad 导入?传统的 HTableOutputFormat 写 HBase 有什么问题? 我们先看下 HBase 的写流程: 通常 MapReduce 在写HBase时使用的是 ...
- 通过BulkLoad的方式快速导入海量数据
摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使节点宕机),但是这些方式不是慢就 ...
- bulk-load 装载HDFS数据到HBase
bulk-load的作用是用mapreduce的方式将hdfs上的文件装载到hbase中,对于海量数据装载入hbase非常有用,参考http://hbase.apache.org/docs/r0.89 ...
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- spark批量写写数据到Hbase中(bulkload方式)
1:为什么大批量数据集写入Hbase中,需要使用bulkload BulkLoad不会写WAL,也不会产生flush以及split. 如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作.除了 ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- [How to] HBase的bulkload使用方法
1.简介 将数据插入HBase表中的方法很多,我们可以通过TableOutputFormat以Mapreduce on HBase的方式将数据插入,也可以单纯的使用客户端API将数据插入.但是以上方法 ...
随机推荐
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 第15月第29天 ffmpeg AVERROR_EOF
1. 在直播时返回AVERROR_EOF代表流结束吗?但对方还在直播,没有结束. int ret = av_read_frame(mContext, pkt); if (ret == AVERROR_ ...
- 一个DOS攻击木马的详细分析过程
一个DOS攻击木马的详细分析过程 0×01 起因 网路流量里发现了大量的的1.exe的文件,而且一直在持续,第一感觉就像是一个木马程序,而且每个1.exe的MD5都不一样,对比发现只有几个字节不一样( ...
- 2017-2018-2 20155303『网络对抗技术』Final:Web渗透获取WebShell权限
2017-2018-2 『网络对抗技术』Final:Web渗透获取WebShell权限 --------CONTENTS-------- 一.Webshell原理 1.什么是WebShell 2.We ...
- 使用Groovy的mixin方法注入,和mixedIn属性实现过滤链
mixin方法注入不多说,这里只是用这个属性搞一个过滤器链的功能 假设我现在有个方法,输入一个字符串,然后需求提出需要进行大写转换输出, 过了一天又要加个前缀,再过了一天,需要把一些字符过滤掉.... ...
- UML和模式应用4:初始阶段(4)--需求制品之用例模型模板示例
1. 前言 UP开发包括四个阶段:初始阶段.细化阶段.构建阶段.移交阶段: UP每个阶段包括 业务建模.需求.设计等科目: 其中需求科目对应的需求制品包括:设想.业务规则.用例模型.补充性规格说明.词 ...
- linux unzip 中文乱码解决方法
引自:https://blog.csdn.net/abyjun/article/details/48344379 unzip -O CP936 xxx.zip (用GBK, GB18030也可以)
- url传参中文乱码解决
url传参request.setCharacterEncoding("utf-8");无法解决中文乱码问题 解决方法: 修改tomcat---conf----server.xml文 ...
- Oracle常用sql语句(一)
# Sql的分类 # DDL (Data Definition Language):数据定义语言,用来定义数据库对象:库.表.列等: CREATE. ALTER.DROP DML(Data Manip ...
- ORACLE与SQLSERVER数据转换
前言: 将SQLServer数据库中的表和数据全量导入到Oracle数据库,通过Microsoft SqlServer Management Studio工具,直接导入到oracle数据库,免去了生成 ...