基于二叉树的高效IP检索格式MMDB
一、MMDB简介
二、构造过程
三、MMDB总体格式

四、节点序列说明
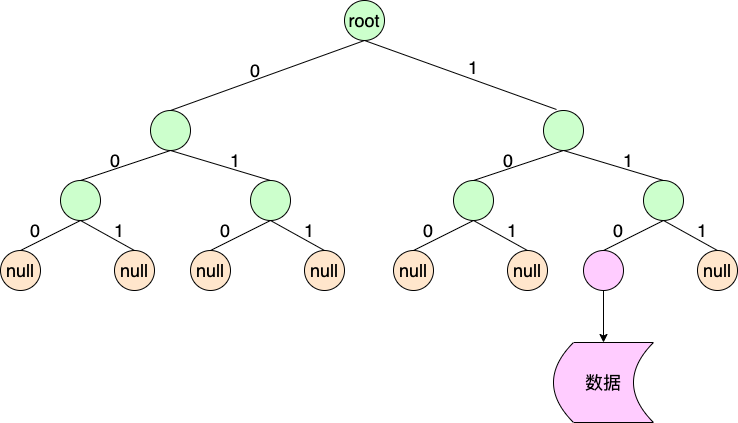
节点序列等于一个节点数组,每个节点由两个记录组成,分别对应二叉树的左孩子和右孩子。
在IP检索中,比特0对应第一个记录,比特1对应第二个记录。

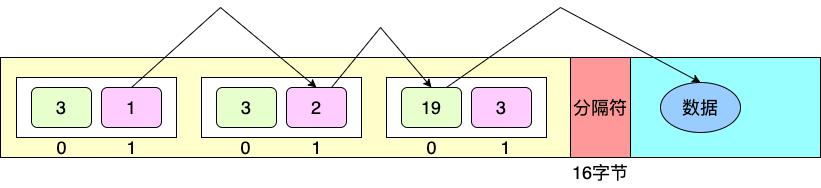
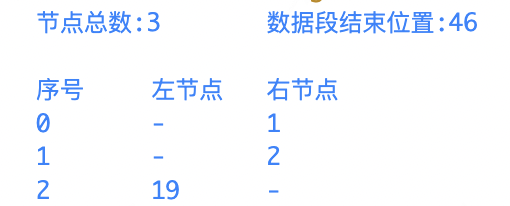
如上图所示,包含3个节点,第一个节点的两个记录为3和1,第二个节点为3和2,第三个节点为19和3。
当记录数等于节点数3时,表示没找到数据。当记录数大于节点数3时,则为数据节点的记录值。
第三个节点记录19表示数据偏移量为0,19-3(节点数)-16。
五、检索算法
在一个总节点数为3的mmdb数据库上,网段“110”的检索过程
六、数据段说明
七、实验例子
1、构造一个网段为“192.2.10.0/3”,对应二进制网络“110”的节点,数据为{"iso":156,"country_name":"China"},生成的节点序列为:

可以看到“110”网段根据二叉树检索算法得到数据段的偏移量19,则数据段偏移量为19-3(节点数)-16=0。
2、再加入一个网段为“64.2.10.0/3”,对应二进制网络“010”的节点,数据为{"iso":826,"country_name":"England"},生成的节点序列为:


八、总结
1、生成过程使用二叉树。
2、存储和检索都是序列化字节数组格式。
3、MMDB是内存数据库 。
参考链接
MaxMind DB File Format Specification
Enriching MMDB files with your own data using go
Building your own MMDB database for fun and profit
基于二叉树的高效IP检索格式MMDB的更多相关文章
- 【转】TCP/IP报文格式
1.IP报文格式 IP协议是TCP/IP协议族中最为核心的协议.它提供不可靠.无连接的服务,也即依赖其他层的协议进行差错控制.在局域网环境,IP协议往往被封装在以太网帧(见本章1.3节)中传送.而所有 ...
- TCP,UDP,IP包头格式及说明(zz)
一.MAC帧头定义 /数据帧定义,头14个字节,尾4个字节/ typedef struct _MAC_FRAME_HEADER { ]; //目的mac地址 ]; //源mac地址 short m_c ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- 以太网帧、TCP与UDP段以及IP数据报格式总结
传输层及其以下的机制由内核提供,是操作系统的一部分,应⽤层由⽤户进程提供应⽤层数据通过协议栈发到⽹络上时,每层协议都要加上⼀个数据⾸部(header),称为封装.不同的协议层对数据包有不同的称谓,在传 ...
- 计算机网络(3)-----IP数据报格式
IP数据报(IP Datagram) 格式 解析 (1)版本 占4位,指IP协议的版本.通信双方使用的IP协议版本必须一致.目前广泛使用的IP协议版本号为4(即IPv4). (2)首部长度 占4位,可 ...
- TCP/IP包格式详解
文章参考地址:http://blog.chinaunix.net/uid-20698826-id-4700710.html http://blog.csdn.net/mrwangwang/articl ...
- 一种基于重载的高效c#上图片添加文字图形图片的方法
在做图片监控显示的时候,需要在图片上添加文字,如果用graphics类绘制图片上的字体,实现图像上添加自定义标记,这种方法经验证是可行的,并且在visual c#2005 编程技巧大全上有提到,但是, ...
- 基于二叉树和数组实现限制长度的最优Huffman编码
具体介绍详见上篇博客:基于二叉树和双向链表实现限制长度的最优Huffman编码 基于数组和基于链表的实现方式在效率上有明显区别: 编码256个符号,符号权重为1...256,限制长度为16,循环编码1 ...
- 【转】以太网帧、IP报文格式
原文:https://www.cnblogs.com/yongren1zu/p/6274460.html https://blog.csdn.net/gufachongyang02/article/d ...
随机推荐
- 10、数组a和b各有10个元素。将他们相同的位置元素逐个比较, 如果a中元素大于b中对应元素的次数多于b数组中元素大于a中元素的次数, 则认为a大于b。请统计大于等于小于的次数
/* 数组a和b各有10个元素.将他们相同的位置元素逐个比较, 如果a中元素大于b中对应元素的次数多于b数组中元素大于a中元素的次数, 则认为a大于b.请统计大于等于小于的次数 */ #include ...
- 1759D(数位变0)
题目链接 题目大意: 给你两个整数n, m.你需要求一个数,它满足如下条件: 是n的整数倍,且倍数小于m. 你应该使其末尾的0尽可能的多(如100后面有2个零,1020后面有一个零,我们应该输出100 ...
- 模块/os/sys/json
目录 内容概要 1.os模块 2.sys模块 3.json模块/实战 内容概要 os模块 sys模块 json模块/实战 1.os模块 # os模块主要是与我们的操作系统打交道 1.创建文件夹(目录) ...
- Mybatis-plus - ActiveRecord 模式CRUD
什么是ActiveRecord模式 ActiveRecord 也属于 ORM 层,由 Rails 最早提出,遵循标准的 ORM 模型:表映射到记录,记录映射到对象,字段映射到对象属性.配合遵循的命名和 ...
- Django查看内部sql语句的方式
一:查看内部sql语句的方式 方式1(queryset对象才能够点击query查看内部的sql语句) res = models.User.objects.values_list('name', 'ag ...
- codeforce E - Binary Inversions题解
题目: 给你一个01串,现在你可以(或者不用)选取其中一个元素进行一次反转操作0-1,1-0:从而使得串中的逆序对个数最多. 题目链接:codeforce origin problem 思路: 1. ...
- JavaScript:变量:声明和赋值变量时,内存结构是什么样的?
这里只是大概画出内存结构的模型图,方便理解当我们声明变量和赋值变量时,到底在干嘛. 如上图所示,a赋值一个对象{},b赋值字符串hello: 于是内存里划了三个区域给我们,一个存储我们声明的变量表,即 ...
- 【进阶篇】Redis实战之Jedis使用技巧详解
一.摘要 在上一篇文章中,我们详细的介绍了 redis 的安装和常见的操作命令,以及可视化工具的介绍. 刚知道服务端的操作知识,还是远远不够的,如果想要真正在项目中得到应用,我们还需要一个 redis ...
- Ng-Matero v15 正式发布
前言 Angular 按照既定的发版计划在 11 月中旬发布了 v15 版本.推迟了一个月(几乎每个版本都是这个节奏),ng-matero 也终于更新到了 v15.其实 ng-matero 本身的更新 ...
- 01-Verilog基础
Verilog RTL编程实践 在进行数字IC设计过程中,RTL coding能力是非常重要的.结合逻辑仿真(VCS)和逻辑综合(Design Compiler)工具.看RTL. 1 ASIC Des ...