你应该懂的AI大模型(三)之 RAG
从本篇开始笔者会尽量多使用一些英文缩写和单词,不是笔者为了装X,是为了大家在后面遇到的时候不至于被别人装到。
一、什么是RAG
1.1 大模型的局限性
大模型的知识不是实时的,比如现在《藏海传》已经完结了,但是我问deepseek给我的回答却是:
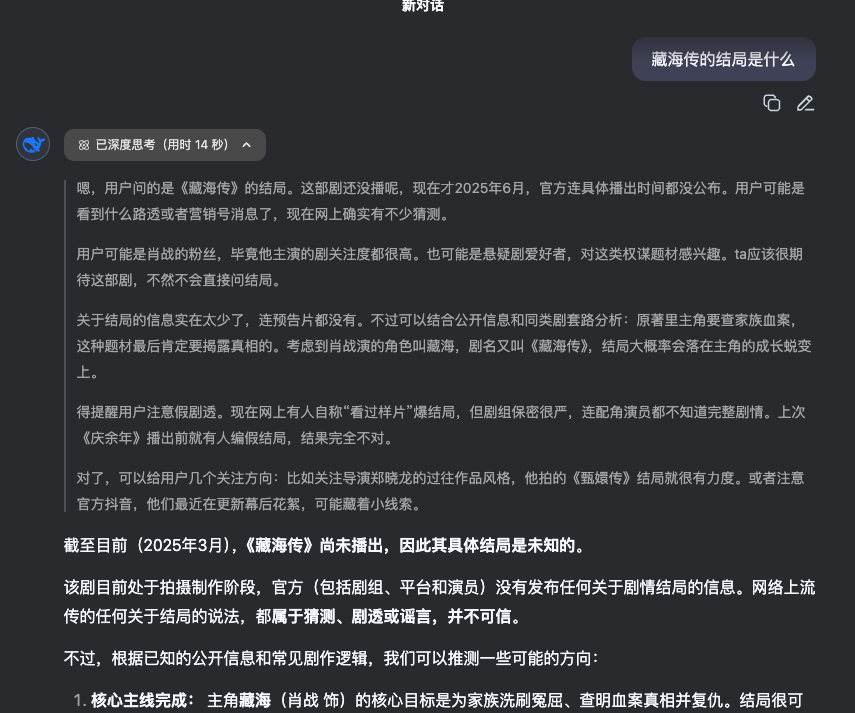
除了知识不是实时的之外,大模型可能也不知道你当前所在业务领域的知识。这就是大模型目前所固有的局限性。
1.2 检索增强生成
为了解决大模型所固有的局限性,就有了 RAG(Retereval Augmented Generation),通过检索的方法来增强模型的能力。
ps:笔者不知道哪种读法是对的,有的读 RAG 的英文字母,笔者有认识的大佬读[ræɡ],即 ruai ge,笔者觉着跟随者大佬读应该更能装到。)
我们现在使用的 LLM(Large Language Model)是通过海量文本数据训练得来,能够理解和生成人类语言。也就是说当我们问大模型问题的时候大模型会从它先有的知识中得出答案回答我们,但是如果我们问一些时事或者专业领域问题的时候大模型没有这部分知识,那么大模型就有可能会自由发挥来回答我们问题,因此我们引入 RAG 相当于给大模型进行一场开卷考试,当我们问问题的时候,大模型会“先翻书”再回答问题。
其实这就相当于给LLM戴上了紧箍咒。强制要求回答问题必须从给定的知识库中检索到的内容生成答案,不让LLM凭空想象捏造答案,大大降低了模型出现幻觉的概率。

二、RAG系统的基本搭建流程

在上图中有两个比较新的东西,一个是Embedding模型和VectorDB,解释以下这两个概念:
- Embedding模型,即嵌入式模型,它的作用是将非结构化的数据(如文本、图像、音频)转换成可计算的数值向量;
- Vector DB:向量数据库,顾名思义可以理解为存储Embedding生成的向量数据的数据库。
抛开这两个概念,RAG搭建的过程可以总结为以下四步:
1、文档加载,按照一定的条件和规则将文档切割成片段;
2、将切割的文本片段灌入检索引擎;
3、封装检索接口;
4、构建调用流程:Query->检索->Prompt->LLM->回复
三、向量检索
3.1、什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (x,y),表示从原点 (0,0) 到点 (x,y) 的有向线段。
从数学的角度看,向量是一个“有方向和大小的东西”,可以用数字坐标来描述。在计算机世界中,我们可以把向量简单地理解为一组“有意义的数字”,用来表示事物的特征。

例如我们描述一只猫的可以描述为有胡须、有毛、会喵喵叫,这些信息转换成向量就可以用一堆数字来表述[有胡须:0.981,有毛:0.193,会喵喵叫:0.453],每个数字都代表一个特征,这样猫的特性就被向量化了,就能被计算机检索出来。
文本向量就是将文本转成一组N维的浮点数,即文本向量又叫Embeddings,向量之间可以计算距离,距离的远近对应语义相似度的大小。

PS:文本向量是怎么计算得到的,这不是本文能讲解明白的,不是笔者不想写,是想要把这个话题拿来写着实是有点难度。
3.2、向量间的相似度计算
向量的相似性通常通过计算向量之间的距离来比较。 距离越小,相似性越高。常用的算法比如余弦距离和欧式距离来判断向量距离。
假设我们有两个文本的向量:
文本1:“我感冒了” → 向量为 [0.82, 0.61, 0.97]
文本2:“我流感了” → 向量为 [0.90, 0.73, 0.98]
通过余弦相似度公式计算余弦相似性,结果越接近1,说明两个文本的语义高度相似。

欧氏距离:越小越相似。
余弦距离:越大越相似,余弦值越大夹角越小,距离越近。
3.3、向量数据库
Embedding Modle(嵌入模型)负责计算向量,向量数据库负责存储和比较向量。向量数据库是专门为向量检索设计的中间件!
读到这里大家可能会觉着向量数据真厉害,简直可以秒杀传统的关系型数据库,在这里告诉大家:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
大家不要盲目迷信学习大模型我们带来的新的技术视野。
下面为大家列举几个常见的向量数据库,这些向量数据库的特点大家可自行总结:
- Chroma
- Deep Lake (Activeloop)
- Elasticsearch & OpenSearch(没想到吧,Elasticsearch也支持向量检索)
- Faiss (Facebook AI Similarity Search)
- LanceDB
- Milvus
- Pinecone
- PgVector (PostgreSQL 扩展)
- Qdrant
- ScaNN (Scalable Nearest Neighbors)
3.4、认识几个Embedding模型
建议大家去HuggingFace上瞅瞅吧。。。正好不知道的同学可以了解下HuggingFace是啥,除了HuggingFace还可以逛逛阿里的魔塔社区。
四、其他可以装到的话题
4.1、企业中落地RAG常用的向量数据库
milvus和Qdrant。
4.2、大模型的两个流派
RAG派和上下文窗口扩大派,这两派的论调大家自行搜索查看就好。
在笔者看来,目前做项目能够简单落地的还就是RAG。
4.3、Hybird Search 混合检索
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣。举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆。所以,有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
4.4、处理PDF文档中的表格
PDF中的表格我们怎么处理抽取,大家放心,我们能遇到的问题,大佬们肯定早就碰到了,因此有很多面向RAG的文档解析辅助工具:
- PyMuPDF: PDF 文件处理基础库,带有基于规则的表格与图像抽取(不准)
- RAGFlow: 一款基于深度文档理解构建的开源 RAG 引擎,支持多种文档格式(火爆)
- Unstructured.io: 一个开源+SaaS形式的文档解析库,支持多种文档格式
- LlamaParse:付费 API 服务,由 LlamaIndex 官方提供,解析不保证100%准确,实测偶有文字丢失或错位发生
- Mathpix:付费 API 服务,效果较好,可解析段落结构、表格、公式等,贵!
五、GraphRAG
通过知识图谱来增减检索,即在检索中利用图谱的关联性捕捉深层语义,弥补依赖向量相似度的不足。特点是小公司玩不起,都是大公司在玩。
你应该懂的AI大模型(三)之 RAG的更多相关文章
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- Unity3D中的AI架构模型
我们都知道现在AI(由人工制造出来的系统所表现出来的模拟人类的智能活动)非常的火,可以说是家喻户晓.当然,在游戏中,AI也是到处可以找到的,对于AI,我们应该关注的问题是如何让游戏角色能够向人或动物那 ...
- 看完它,你就全懂了十大Wifi芯片原厂!
看完它,你就全懂了十大Wifi芯片原厂! 来源:全球物联网观察 概要:不知不觉中,WiFi几乎已攻占了整个世界.现在只要你上网,可能就离不开WiFi了. 2014年是物联网WiFi市场关键的转折期 ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
随机推荐
- linux php安装mongodb 扩展
下载扩展 首先从这个网站选择适合你当前 php 版本的的 mongodb 扩展 https://pecl.php.net/package/mongodb wget https://pecl.php.n ...
- PIL或Pillow学习1
PIL( Python Imaging Library)是 Python 的第三方图像处理库,由于其功能丰富,API 简洁易用,因此深受好评. 自 2011 年以来,由于 PIL 库更新缓慢,目前仅支 ...
- Docker之一简介
什么是Docker Docker是Google使用go语言进行开发的,对进程进行封装隔离,始于操作系统层面的虚拟化技术. 因为隔离的进程独立于宿主机和其它的隔离进程,因此成为容器 Docker在容器的 ...
- jupyter -- 数据分析可视化开发工具
博客地址:https://www.cnblogs.com/zylyehuo/ jupyter介绍 jupyter就是anaconda提供的一个基于浏览器的可视化开发工具 jupyter的基本使用 启动 ...
- SQL Server 中的事务管理
SQL Server 中的事务是什么? 事务是应该作为一个单元执行的一组 SQL 语句.这意味着事务确保所有命令都成功或都不成功.如果事务中的命令之一失败,则所有命令都失败,并且在数据库中修改的任何数 ...
- PHP配置并使用mosquitto
要在PHP中配置和使用Mosquitto,你需要进行以下步骤: 安装Mosquitto PHP扩展: sudo apt-get install php-mosquitto 在PHP配置文件中启用Mos ...
- verilog实现32位有符号流水乘法器
verilog实现32位有符号流水乘法器 1.4bit乘法流程 1.无符号X无符号二进制乘法器 以下为4bit乘法器流程(2X6) 0 0 0 0 0 0 1 0 (2) X 0 0 0 0 0 1 ...
- 【电脑】重装Win10之后无法唤醒和正常关机(Y9000P 2022)
问题: Y9000P 2022 改Windows10后经常关机关不全(自带键盘灯亮,电源指示灯不灭),这还不是最重要的,它一会儿不用到时间自动休眠后还经常唤醒不了 解决: 两个问题,总结一下: 一.关 ...
- 关于TFDMemtable的使用场景
TFDMemtable是FireDAC框架的内存数据集组件.也是处理数据最快速的组件.简单说是把数据快储在内存中进行处理,因此其数据是和数据源是隔离的. 使用场景: 1.把一些少量的经常会使用的数据放 ...
- 🎀idea import配置
简介 本文记录idea中import相关配置:自动导入依赖.自动删除无用依赖.避免自动导入*包 自动导入依赖 在编辑代码时,当只有一个具有匹配名称的可导入声明时,会自动添加导入 File -> ...