2022 年数据科学研究综述:重点介绍 ML、DL、NLP 等
2022 年数据科学研究综述:重点介绍 ML、DL、NLP 等
当我们在 2022 年底临近时,我对许多著名研究小组完成的所有惊人工作感到振奋,他们将 AI、机器学习、深度学习和 NLP 的状态扩展到各种重要方向。在本文中,我将向您介绍我迄今为止在 2022 年精选的一些论文,这些论文特别引人注目且非常有用。通过努力与该领域的研究进展保持同步,我发现这些论文中所代表的方向非常有希望。我希望你和我一样喜欢我选择的数据科学研究。我通常会指定一个周末来消耗整篇论文。多么好的放松方式啊!
关于 GELU 激活函数——那是什么鬼?
这篇文章解释了最近在 Google AI 的 BERT 和 OpenAI 的 GPT 模型中使用的 GELU 激活函数。这两种模型都在各种 NLP 任务中取得了最先进的结果。对于忙碌的读者,本节介绍了 GELU 激活的定义和实现。这篇文章的其余部分提供了介绍并讨论了 GELU 背后的一些直觉。
深度学习中的激活函数:综合调查和基准测试
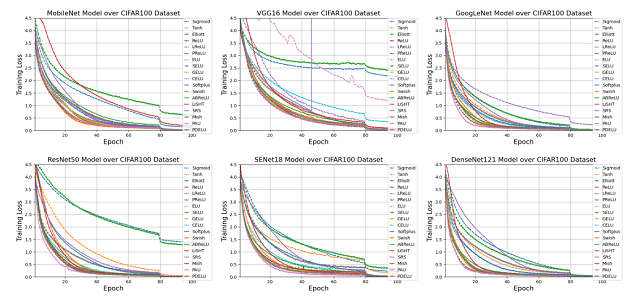
近年来,神经网络在解决许多问题方面表现出巨大的增长。已经引入了各种类型的神经网络来处理不同类型的问题。然而,任何神经网络的主要目标都是使用层次结构将非线性可分离的输入数据转换为更线性可分离的抽象特征。这些层是线性和非线性函数的组合。最流行和最常见的非线性层是激活函数 (AF),例如 Logistic Sigmoid、Tanh、ReLU、ELU、Swish 和 Mish。在本文中,对用于深度学习的神经网络中的 AFs 进行了全面的概述和调查。涵盖了不同类别的 AF,例如基于 Logistic Sigmoid 和 Tanh、基于 ReLU、基于 ELU 和基于学习的 AF。AF的几个特性,例如输出范围,单调性和平滑性也被指出。还对具有不同网络的 18 个最先进的 AF 对不同类型的数据进行了性能比较。提出 AFs 的见解有助于研究人员进行进一步的数据科学研究和从业者在不同的选择中进行选择。用于实验对比的代码发布在这里。
机器学习操作 (MLOps):概述、定义和架构
所有工业机器学习 (ML) 项目的最终目标是开发 ML 产品并快速将其投入生产。然而,机器学习产品的自动化和操作化极具挑战性,因此许多机器学习的努力未能达到他们的预期。机器学习操作 (MLOps) 的范式解决了这个问题。MLOps 包括几个方面,例如最佳实践、概念集和开发文化。然而,MLOps 仍然是一个模糊的术语,它对研究人员和专业人士的影响是模棱两可的。本文通过进行混合方法研究来解决这一差距,包括文献回顾、工具回顾和专家访谈。作为这些调查的结果,所提供的是对必要原则、组件和角色的汇总概述,
扩散模型:方法和应用的综合调查
扩散模型是一类深度生成模型,在具有密集理论基础的各种任务中显示出令人印象深刻的结果。尽管扩散模型比其他最先进的模型实现了更令人印象深刻的样本合成质量和多样性,但它们仍然受到昂贵的采样程序和次优似然估计的困扰。最近的研究表明,人们对改进扩散模型的性能表现出了极大的热情。本文首次全面回顾了现有的扩散模型变体。还提供了第一个扩散模型分类法,将它们分为三种类型:采样加速增强、似然最大化增强和数据泛化增强。论文还介绍了其他五个生成模型(即变分自编码器、生成对抗网络、归一化流、自回归模型和基于能量的模型)详细并阐明了扩散模型和这些生成模型之间的联系。最后,本文研究了扩散模型的应用,包括计算机视觉、自然语言处理、波形信号处理、多模态建模、分子图生成、时间序列建模和对抗性纯化。
多视图分析的合作学习
本文提出了一种具有多组特征(“视图”)的监督学习的新方法。使用“组学”数据(例如在一组常见样本上测量的基因组学和蛋白质组学)进行多视图分析代表了生物学和医学中日益重要的挑战。合作学习将通常的预测平方误差损失与“一致”惩罚相结合,以鼓励来自不同数据视图的预测一致。当不同的数据视图在其信号中共享一些可用于增强信号的潜在关系时,该方法可能特别强大。
自然语言处理的有效方法:调查
充分利用有限的资源,可以在自然语言处理 (NLP) 数据科学研究和实践方面取得进步,同时对资源保持保守。这些资源可能是数据、时间、存储或能源。NLP 最近的工作通过扩展产生了有趣的结果。但是,仅使用规模来改善结果意味着资源消耗也会扩大。这种关系激发了对有效方法的研究,这些方法需要更少的资源来实现类似的结果。这项调查将 NLP 效率方面的方法和发现联系起来并加以综合,旨在指导该领域的新研究人员并激发新方法的开发。
纯 Transformer 是强大的图学习器
本文表明,没有针对图的特定修改的标准 Transformer 可以在理论和实践上为图学习带来可喜的结果。给定一个图,只需将所有节点和边视为独立的标记,用标记嵌入来扩充它们,然后将它们提供给 Transformer。通过适当的令牌嵌入选择,本文证明,这种方法在理论上至少与不变的图形网络(2-ign)一样表现力,由等效线性层组成,它已经比所有消息传播的图形神经网络更具表现力(神经网络)。在大规模图形数据集 (PCQM4Mv2) 上进行训练时,与具有复杂图特定归纳偏差的 Transformer 变体相比,与 GNN 基线相比,建议的方法创造了标记化图转换器 (TokenGT) 取得了显着更好的结果和竞争结果。可以找到与本文相关的代码在这里。
为什么基于树的模型在表格数据上仍然优于深度学习?
虽然深度学习在文本和图像数据集上取得了巨大进步,但它在表格数据上的优势尚不清楚。本文在大量数据集和超参数组合中为标准和新颖的深度学习方法以及基于树的模型(如 XGBoost 和随机森林)提供了广泛的基准。该论文定义了一组标准的 45 个来自不同领域的数据集,这些数据集具有表格数据的明显特征,以及一种用于拟合模型和寻找良好超参数的基准测试方法。结果表明,即使不考虑其卓越的速度,基于树的模型在中等数据(~10K 样本)上仍然是最先进的。要了解这个差距,对基于树的模型和神经网络 (NN) 的不同归纳偏差进行实证研究非常重要。这导致了一系列挑战,这些挑战应该指导旨在构建特定表格 NN 的研究人员:1. 对无信息特征具有鲁棒性,2. 保持数据的方向,以及 3. 能够轻松学习不规则函数。
测量云实例中 AI 的碳强度
通过提供前所未有的计算资源访问,云计算促进了机器学习等技术的快速发展,其计算需求会产生高昂的能源成本和相应的碳足迹。因此,最近的学术研究呼吁更好地估计人工智能对温室气体的影响:今天的数据科学家无法轻松或可靠地获得这些信息的测量结果,从而阻碍了可操作策略的发展。云提供商向用户提供有关软件碳强度的信息是实现最小化排放的基本踏脚石。本文提供了衡量软件碳强度的框架,并建议使用基于位置和特定时间的每能源单位边际排放数据来衡量运营碳排放。提供了一组用于自然语言处理和计算机视觉的现代模型的操作软件碳强度测量,以及各种模型大小,包括对 61 亿参数语言模型的预训练。然后,本文评估了一套在 Microsoft Azure 云计算平台上减少排放的方法:在不同地理区域使用云实例,在一天中的不同时间使用云实例,并在边际碳强度高于一定值时动态暂停云实例临界点。
YOLOv7:可训练的免费赠品为实时物体检测器设置了新的最先进技术
YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的物体检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时物体检测器中具有最高的准确度 56.8% AP。YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于变压器的检测器 SWIN-L Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出 509% 和 2%,并且基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高 551%,准确率提高 0.7%,以及 YOLOv7 的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、 DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B 和许多其他速度和准确度的物体检测器。此外,YOLOv7 仅在 MS COCO 数据集上从头开始训练,没有使用任何其他数据集或预训练的权重。在这里。
StudioGAN:用于图像合成的 GAN 分类和基准
生成对抗网络 (GAN) 是用于逼真图像合成的最先进的生成模型之一。虽然训练和评估 GAN 变得越来越重要,但当前的 GAN 研究生态系统并没有提供可靠的基准来进行一致和公平的评估。此外,由于很少有经过验证的 GAN 实现,研究人员花费了大量时间来重现基线。本文研究了 GAN 方法的分类,并提出了一个名为 StudioGAN 的新开源库。StudioGAN 支持 7 种 GAN 架构、9 种调节方法、4 种对抗性损失、13 个正则化模块、3 个可微增强、7 个评估指标和 5 个评估主干。通过提出的训练和评估协议,该论文提出了一个使用各种数据集(CIFAR10、ImageNet、AFHQv2、FFHQ 和 Baby/Papa/Granpa-ImageNet)和 3 个不同的评估骨干网(InceptionV3、SwAV 和 Swin Transformer)的大规模基准测试。与 GAN 社区中使用的其他基准测试不同,本文在统一的训练管道中训练具有代表性的 GAN,包括 BigGAN、StyleGAN2 和 StyleGAN3,并使用 7 个评估指标量化生成性能。该基准评估其他尖端生成模型(例如 StyleGAN-XL、ADM、MaskGIT 和 RQ-Transformer)。StudioGAN 提供具有预训练权重的 GAN 实施、训练和评估脚本。可以找到与本文相关的代码 与 GAN 社区中使用的其他基准测试不同,本文在统一的训练管道中训练具有代表性的 GAN,包括 BigGAN、StyleGAN2 和 StyleGAN3,并使用 7 个评估指标量化生成性能。该基准评估其他尖端生成模型(例如 StyleGAN-XL、ADM、MaskGIT 和 RQ-Transformer)。StudioGAN 提供具有预训练权重的 GAN 实施、训练和评估脚本。可以找到与本文相关的代码 与 GAN 社区中使用的其他基准测试不同,本文在统一的训练管道中训练具有代表性的 GAN,包括 BigGAN、StyleGAN2 和 StyleGAN3,并使用 7 个评估指标量化生成性能。该基准评估其他尖端生成模型(例如 StyleGAN-XL、ADM、MaskGIT 和 RQ-Transformer)。StudioGAN 提供具有预训练权重的 GAN 实施、训练和评估脚本。可以找到与本文相关的代码 StudioGAN 提供具有预训练权重的 GAN 实施、训练和评估脚本。可以找到与本文相关的代码 StudioGAN 提供具有预训练权重的 GAN 实施、训练和评估脚本。可以找到与本文相关的代码在这里。
使用 Logit 归一化缓解神经网络过度自信
检测分布式输入对于在现实世界中安全部署机器学习模型至关重要。然而,众所周知,神经网络存在过度自信问题,即它们对分布内和分布外的输入产生异常高的置信度。这篇 ICML2022 论文表明,可以通过 Logit Normalization (LogitNorm) 来缓解这个问题——这是对交叉熵损失的简单修复——通过在训练中对 logits 强制执行恒定向量范数。所提出的方法的动机是分析 logit 的范数在训练期间不断增加,导致过度自信的输出。因此,LogitNorm 背后的关键思想是在网络优化期间解耦输出范数的影响。使用 LogitNorm 训练,神经网络在分布内和分布外数据之间产生高度可区分的置信度分数。大量实验证明了 LogitNorm 的优越性,在常见基准上将平均 FPR95 降低了高达 42.30%。
机器学习中的纸笔练习
这是机器学习中(主要是)纸笔练习的集合。练习涉及以下主题:线性代数、优化、有向图模型、无向图模型、图模型的表达能力、因子图和消息传递、隐马尔可夫模型的推理、基于模型的学习(包括 ICA 和非标准化模型) ,采样和蒙特卡洛积分,以及变分推理。
CNN 能比变形金刚更强大吗?
Vision Transformers 最近的成功正在动摇卷积神经网络 (CNN) 在图像识别领域长达十年的主导地位。具体来说,就分布外样本的鲁棒性而言,最近的数据科学研究发现,无论训练设置如何,Transformer 本质上都比 CNN 更鲁棒。此外,人们认为 Transformer 的这种优越性在很大程度上应归功于其类似自我注意的架构本身。在本文中,我们通过仔细检查变形金刚的设计来质疑这种信念。本文中的发现导致了三种高效的架构设计,以提高鲁棒性,但足够简单,可以在几行代码中实现,即 a) 修补输入图像,b) 扩大内核大小,c) 减少激活层和归一化层。将这些组件组合在一起,可以构建纯 CNN 架构,而无需任何与 Transformers 一样健壮甚至更健壮的注意力操作。可以找到与本文相关的代码在这里。
OPT:开放预训练的 Transformer 语言模型
大型语言模型通常经过数十万个计算日的训练,在零样本和少样本学习方面表现出非凡的能力。考虑到它们的计算成本,如果没有大量资金,这些模型很难复制。对于通过 API 可用的少数几个,无法访问完整的模型权重,这使得它们难以研究。本文介绍了开放式预训练变压器 (OPT),这是一套仅解码器的预训练变压器,参数范围从 125M 到 175B,旨在与感兴趣的研究人员充分和负责任地分享。结果表明,OPT-175B 与 GPT-3 相当,而开发所需的碳足迹仅为 1/7。与本文相关的代码可以在这里找到。
深度神经网络和表格数据:调查
异构表格数据是最常用的数据形式,对于许多关键和计算要求高的应用程序至关重要。在同构数据集上,深度神经网络多次表现出优异的性能,因此被广泛采用。然而,它们对用于推理或数据生成任务的表格数据的适应仍然具有挑战性。为了促进该领域的进一步发展,本文概述了用于表格数据的最新深度学习方法。本文将这些方法分为三组:数据转换、专门架构和正则化模型。对于这些组中的每一个,本文都提供了主要方法的全面概述。
在 ODSC West 2022 上了解有关数据科学研究的更多信息
如果您对机器学习、深度学习、NLP 等所有这些数据科学研究感兴趣,请于11 月 1 日至 3 日在 ODSC West 2022上了解有关该领域的更多信息。在本次活动中,您可以选择面对面和虚拟门票,您可以从世界各地的许多领先研究实验室中学习,了解该领域的新工具、框架、应用程序和开发。以下是我们数据科学研究前沿轨道中的一些杰出会议:
- 用于精准健康的可扩展、实时心率变异性生物反馈:一种新的算法方法
- 商业决策中的因果/规范性分析
- 人工智能可以从数据中学习。但它能学会推理吗?
- StructureBoost:具有分类结构的梯度提升
- 用于量化金融和交易的机器学习模型
- 一种基于直觉的强化学习方法
- 稳健和公平的不确定性估计
2022 年数据科学研究综述:重点介绍 ML、DL、NLP 等的更多相关文章
- 2017 年 机器学习之数据挖据、数据分析,可视化,ML,DL,NLP等知识记录和总结
今天是2017年12月30日,2017年的年尾,2018年马上就要到了,回顾2017过的确实很快,不知不觉就到年末了,再次开篇对2016.2017年的学习数据挖掘,机器学习方面的知识做一个总结,对自己 ...
- 消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍.RabbitMQ&Redis的重点介绍与简单应用 消息队列介绍.RabbitMQ.Redis 一.什么是消息队列 这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下 ...
- jmockit使用总结-MockUp重点介绍
公司对开发人员的单元测试要求比较高,要求分支覆盖率.行覆盖率等要达到60%以上等等.项目中已经集成了jmockit这个功能强大的mock框架,学会使用这个框架势在必行.从第一次写一点不会,到完全可以应 ...
- ML,DL核心数学及算法知识点总结
ML,DL核心数学及算法知识点总结:https://mp.weixin.qq.com/s/bskyMQ2i1VMNiYKIvw_d7g
- 事实胜于雄辩,苹果MacOs能不能玩儿机器/深度(ml/dl)学习(Python3.10/Tensorflow2)
坊间有传MacOs系统不适合机器(ml)学习和深度(dl)学习,这是板上钉钉的刻板印象,就好像有人说女生不适合编程一样的离谱.现而今,无论是Pytorch框架的MPS模式,还是最新的Tensorflo ...
- 百度ML/DL方向面经
最近败人品败得有些厉害,很多事都处理得不好--感觉有必要做点好事攒一攒. 虽然可能面试经过不是很有代表性,不过参考价值大概还是有的-- 由于当时人在国外,三轮都是电面-- 一面 当地时间早上5点半爬起 ...
- .NET:“事务、并发、并发问题、事务隔离级别、锁”小议,重点介绍:“事务隔离级别"如何影响 “锁”?
备注 我们知道事务的重要性,我们同样知道系统会出现并发,而且,一直在准求高并发,但是多数新手(包括我自己)经常忽略并发问题(更新丢失.脏读.不可重复读.幻读),如何应对并发问题呢?和线程并发控制一样, ...
- 各种vpn协议介绍(重点介绍sslvpn的实现方式openvpn)
vpn介绍: VIrtual Private Network 虚拟专用网络哪些用户会用vpn? 公司的远程用户(出差.家里),公司的分支机构.idc机房.企业间.FQ常见vpn协议有哪些? ...
- spring框架总结(03)重点介绍(Spring框架的第二种核心掌握)
1.Spring的AOP编程 什么是AOP? ----- 在软件行业AOP为Aspect Oriented Programming 也就是面向切面编程,使用AOP编程的好处就是:在不修改源代码的情 ...
- ML&DL视频教程资源
作者:Bruce链接:https://www.zhihu.com/question/49909565/answer/345894856来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
随机推荐
- kaggle数据集某咖啡店的营销数据分析
因为还处于数据分析的学习阶段(野生Python学者),所以在kaggle这个网站找了两个数据集来给自己练练手. 准备工作 import pandas as pd import os import ma ...
- 工作中的技术总结_ form表单的前后台交互 _20210825
工作中的技术总结_ form表单的前后台交互 _20210825 在项目经常会使用 form 表单 进行数据的 页面展示 以及数据的 提交和后台处理 1.数据是怎么从后台传递到前台的 model.ad ...
- DPaRL:耶鲁+AWS出品,开放世界持续学习场景的新解法 | ECCV'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处 论文: Open-World Dynamic Prompt and Continual Visual Representation Learning ...
- 支持国产3A游戏大作 ——《黑神话:悟空》
- 盘点阿里、腾讯、百度大厂C#开源项目
BAT作为互联网第一梯队的互联网公司,他们开源的项目都是发自内心地将踩过的坑和总结的经验融入到开源项目中,供业界所有人使用,希望帮助他人解决问题. 目前互联网的大厂开源的项目涉及各种语言,项目类型包含 ...
- Air780E软件指南:C语言内存数组(zbuff)
一.ZBUFF(C内存数组)简介 zbuff库可以用c风格直接操作(下标从0开始),例如buff[0]=buff[3] 可以在sram上或者psram上申请空间,也可以自动申请(如存在psram则在p ...
- XSS跨站脚本之portswigger labs练习
目录 1 什么是XSS 2 XSS的类型有哪些 3 XSS攻击的过程和原理 4 XSS的防御 5 可能会用到的XSS Payload资源 6 靶场训练 portswigger labs 6.1 没有任 ...
- 孤立森林(IForest)代码实现及与PyOD对比
孤立森林(Isolation Forest)是经典的异常检测算法(论文网址).本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比. 简单来说,孤立森林(IForest)中包含若 ...
- Python:pygame游戏编程之旅一(Hello World)
按照上周计划,今天开始学习pygame,学习资料为http://www.pygame.org/docs/,学习的程序实例为pygame模块自带程序,会在程序中根据自己的理解加入详细注释,并对关键概念做 ...
- linux 软连接使用
转载请注明出处: 在Linux系统中,软连接(Symbolic Link)是一种特殊类型的文件链接,类似于Windows系统中的快捷方式.它允许用户通过一个文件路径访问另一个文件或目录,而不需要拥有原 ...