Pearson(皮尔逊)相关系数及MATLAB实现
转自:http://blog.csdn.net/wsywl/article/details/5727327
由于使用的统计相关系数比较频繁,所以这里就利用几篇文章简单介绍一下这些系数。
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
Pearson(皮尔逊)相关系数
1、简介
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
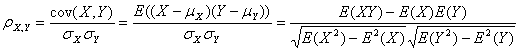
公式二:

公式三:
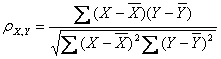
公式四:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
2、适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
3、Matlab实现
皮尔逊相关系数的Matlab实现(依据公式四实现):
- function coeff = myPearson(X , Y)
- % 本函数实现了皮尔逊相关系数的计算操作
- %
- % 输入:
- % X:输入的数值序列
- % Y:输入的数值序列
- %
- % 输出:
- % coeff:两个输入数值序列X,Y的相关系数
- %
- if length(X) ~= length(Y)
- error('两个数值数列的维数不相等');
- return;
- end
- fenzi = sum(X .* Y) - (sum(X) * sum(Y)) / length(X);
- fenmu = sqrt((sum(X .^2) - sum(X)^2 / length(X)) * (sum(Y .^2) - sum(Y)^2 / length(X)));
- coeff = fenzi / fenmu;
- end %函数myPearson结束
也可以使用Matlab中已有的函数计算皮尔逊相关系数:
- coeff = corr(X , Y);
4、参考内容
Pearson(皮尔逊)相关系数及MATLAB实现的更多相关文章
- Pearson(皮尔逊)相关系数
Pearson(皮尔逊)相关系数:也叫pearson积差相关系数.衡量两个连续变量之间的线性相关程度. 当两个变量都是正态连续变量,而且两者之间呈线性关系时,表现这两个变量之间相关程度用积差相关系数, ...
- np.corrcoef()方法计算数据皮尔逊积矩相关系数(Pearson's r)
上一篇通过公式自己写了一个计算两组数据的皮尔逊积矩相关系数(Pearson's r)的方法,但np已经提供了一个用于计算皮尔逊积矩相关系数(Pearson's r)的方法 np.corrcoef() ...
- pandas通过皮尔逊积矩线性相关系数(Pearson's r)计算数据相关性
皮尔逊积矩线性相关系数(Pearson's r)用于计算两组数组之间是否有线性关联,举个例子: a = pd.Series([1,2,3,4,5,6,7,8,9,10]) b = pd.Series( ...
- 皮尔逊(Pearson)系数矩阵——numpy
一.原理 注意 专有名词.(例如:极高相关) 二.代码 import numpy as np f = open('../file/Pearson.csv', encoding='utf-8') dat ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 皮尔逊残差 | Pearson residual
参考:Pearson Residuals 这些概念到底是写什么?怎么产生的? 统计学功力太弱了!
- Spark Mllib里的如何对两组数据用皮尔逊计算相关系数
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
- 从欧几里得距离、向量、皮尔逊系数到http://guessthecorrelation.com/
一.欧几里得距离就是向量的距离公式 二.皮尔逊相关系数反应的就是线性相关 游戏http://guessthecorrelation.com/ 的秘诀也就是判断一组点的拟合线的斜率y/x ------- ...
- Python基于皮尔逊系数实现股票预测
# -*- coding: utf-8 -*- """ Created on Mon Dec 2 14:49:59 2018 @author: zhen "&q ...
随机推荐
- 按Enter键后Form表单自动提交的问题
怪事年年有,今年特别多. 话说,最近项目中遇到一件怪事,当我鼠标focus在文本框中,轻轻敲了下回车键,尼玛页面突然刷新了,当时把宝宝给吓得. 接下来就是一番苦逼的烧脑和蛋疼~ 一.被表象所迷惑 突然 ...
- 一、Android学习第一天——环境搭建(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 一. Android学习第一天——环境搭建 Android 开发环境的搭建 ...
- 一:Shell基础
1.shell概述 shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用shell来启动,挂起,停止甚至是编写一些程序: shell还是 ...
- MMORGP大型游戏设计与开发(客户端架构 part1 of vgui)
作为客户端的重要装饰,UI扮演着极为重要的角色,是客户端中核心的组成.vgui(微GUI)中,提供了核心的接口封装,实现了客户端中常见的界面操作,并结合lua脚本,使得控制界面更加的方便. 构架 总结 ...
- POJ1849Two[DP|树的直径](扩展HDU4003待办)
Two Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 1390 Accepted: 701 Description Th ...
- AC日记——判断字符串是否为回文 openjudge 1.7 33
33:判断字符串是否为回文 总时间限制: 1000ms 内存限制: 65536kB 描述 输入一个字符串,输出该字符串是否回文.回文是指顺读和倒读都一样的字符串. 输入 输入为一行字符串(字符串中 ...
- 精选30个优秀的CSS技术和实例
精选30个优秀的CSS技术和实例 投递人 墙头草 发布于 2008-12-06 20:57 评论(97) 有17487人阅读 原文链接 [收藏] « » 今天,我为大家收集精选了30个使用纯CSS ...
- PHP加载另一个文件类的方法
加载另一个文件类的方法 当前文件下有a.php 和b.php,想要在class b中引入class a <?php class a { public $name = ' ...
- poj1129 Channel Allocation
Channel Allocation Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 14361 Accepted: 73 ...
- 使用Access-Control-Allow-Origin解决跨域
什么是跨域 当两个域具有相同的协议(如http), 相同的端口(如80),相同的host(如www.google.com),那么我们就可以认为它们是相同的域(协议,域名,端口都必须相同). 跨域就指着 ...